2,100 reads
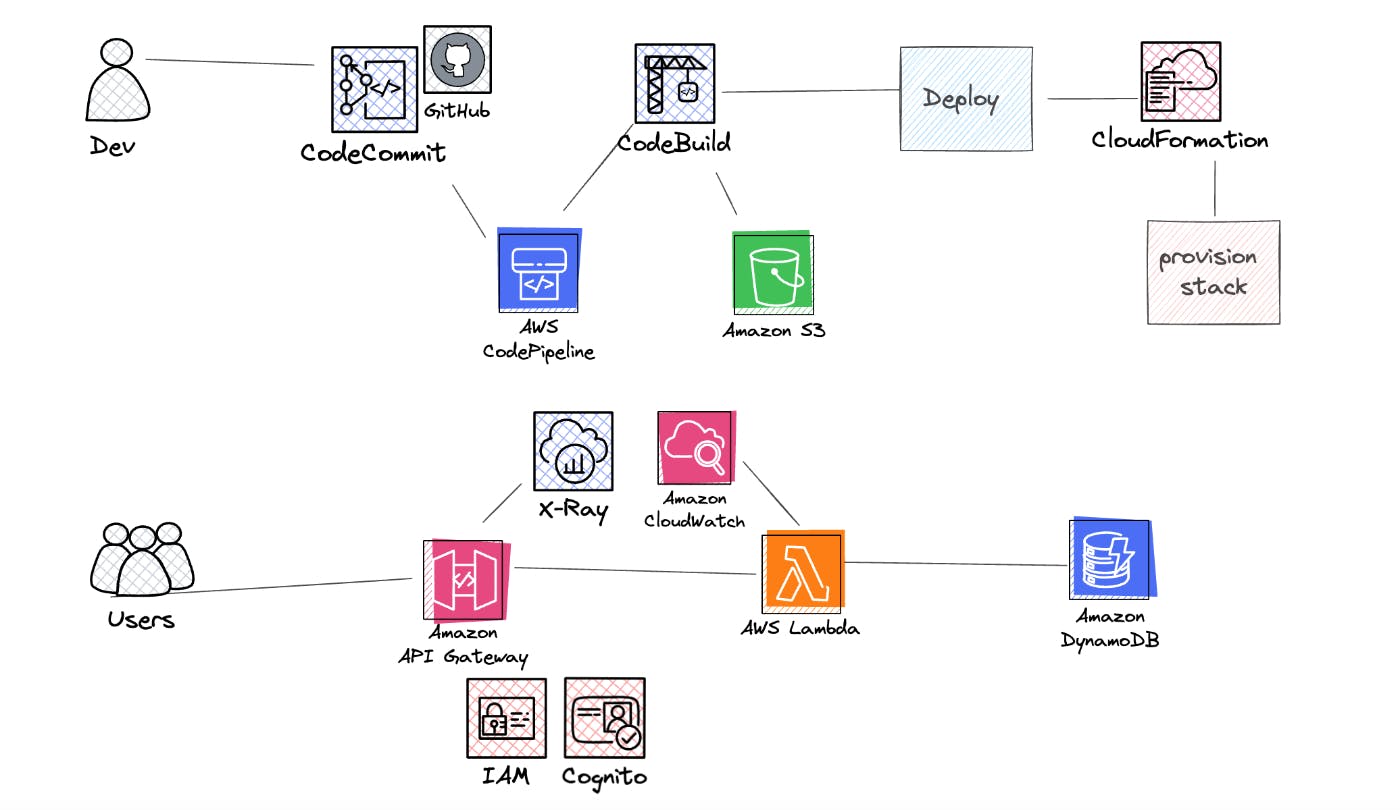
Detecting Architectural Gaps with Automation - Proposed Solution
by
May 21st, 2024







Story's Credibility



Story's Credibility
About Author

Please refer to https://github.com/dimanikulin
Comments

Please refer to https://github.com/dimanikulin