
692 reads
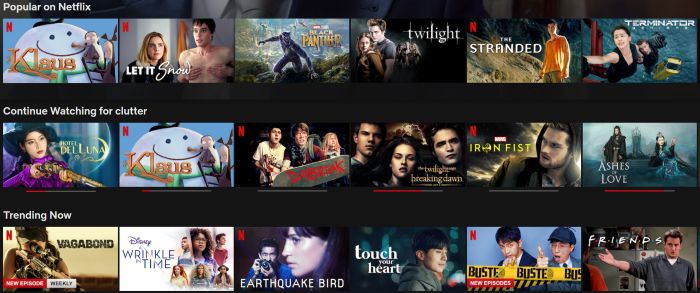
Content-Based Recommender Using Natural Language Processing (NLP)
by byJames N@jnyh
byJames N@jnyh
perpetual student | fitness enthusiast | passionate explorer | https://github.com/jnyh
August 11th, 2020





perpetual student | fitness enthusiast | passionate explorer | https://github.com/jnyh


perpetual student | fitness enthusiast | passionate explorer | https://github.com/jnyh
About Author

perpetual student | fitness enthusiast | passionate explorer | https://github.com/jnyh
Comments






![Applying Agile Framework To Data Science Projects [A How-To Guide]](https://hackernoon.imgix.net/images/6x213yz0.jpg?auto=format&fit=max&w=3840)









![What Are Convolution Neural Networks? [ELI5]](https://hackernoon.imgix.net/images/69s32rn.jpg?auto=format&fit=max&w=3840)
