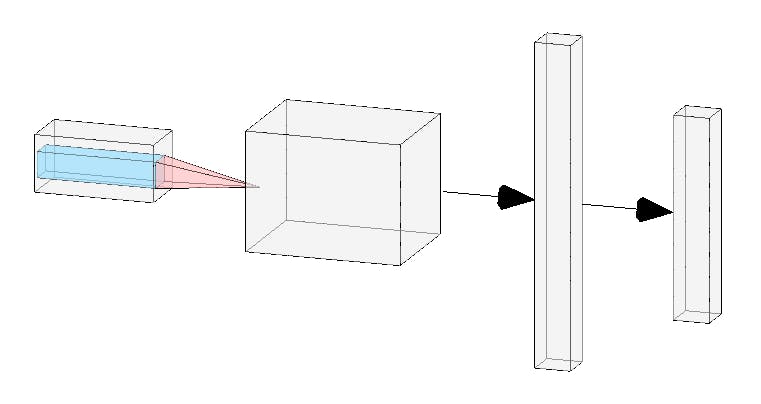
Well! I was reading this research paper h and there was something unexpected! I thought of testing it myself and was really shocked seeing the results. ttps://arxiv.org/pdf/1703.08774.pdf This paper ‘Who said What: Modeling Individual Labelers Improves Classification’ is presented by Melody Y.Guan, Varun Gulshan, Andrew M. Dai and ‘Godfather of ML’- Geoffrey E. Hinton. Even if teacher is wrong, you can still top the exam! 😛 This paper has revealed some results which not everyone will be ready to digest unless proved.Some of them are: Train MNIST with 50% wrong labels and still get 97% accuracy. More labelers doesn’t mean more accurate labeling of data. Reliability of 3 doctors is highest compared to 6 doctors! In this article we’ll prove that training MNIST on 50% noisy labels do give 97%+ accuracy. We will use Deep Learning studio by Deepcognition.ai to make the process a bit faster. First, let me show you the architecture of our Deep Learning model for MNIST. We’ll use same model architecture to train it with true labels for the first time and second time with noisy labels to compare their accuracy. Model Architecture model architecture If you are new to Deepcognition, do see my article to get basic intuition of using Deep Learning Studio. _Kingdom:Plantae Clade:Angiosperms Order:Asparagales Family:Iridaceae Subfamily:Iridoideae Tribe:Irideae Genus:Iris_towardsdatascience.com Iris genus classification|DeepCognition| Azure ML studio Let’s dive in now! Classification of MNIST with true labels Data True data is available publicly in Deep Learning Studio. Just select mnist-public from datasets as shown below. You can see that all the labels are correct Training results Our model achieved an of in validation set, when trained with . accuracy 98.01% correct labels training results with true labels Lets experiment with noisy labels Data Now, we need to use data which has 50% wrong labels. You can download it from . After downloading the data, upload it to your deepcognition’s account and select it from Data tab. It may take around 28 minutes to upload data. Be calm. here You can see that labels are wrong Note: I misclassified 50% of images from each class. But wait! . This should be done only for training data, so I did. The testing data must be present with correct labels. I made a split of 80%-20%. So when you select this dataset,choose only 80%-20%–0% or 80%-0%-20% in train-validation-test set in tab.Don’t shuffle the data as we’ll lose our correct training data. Data Don’t forget to choose ‘Normalization’ of images, otherwise our loss function won’t converge(even if all labels are correct). Training After training our model achieved where as 51.67% training accuracy 97.59% validation accuracy! So yeah, I finally confirmed that even with 50% wrong labels, we may have high accuracy. Training results with 50% noisy labels This was awesome! I insist everyone to replicate these results yourself! Thanks for reading! Happy Deep Learning!