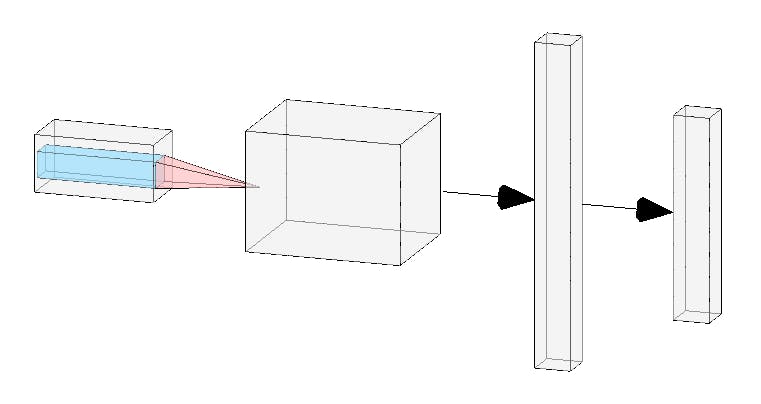
This AI is hungry - Part I - Deep Learning Tutorial: Classification of Cooking Dishes and Recipes with Machine Learning In this tutorial I will show how to train with Keras to and to . The dataset contains >400'000 food images and >300'000 recipes from chefkoch.de. This tutorial is divided into two parts. Part 2 will soon be published. deep convolutional neural networks classify images into food categories output a matching recipe body[data-twttr-rendered="true"] {background-color: transparent;}.twitter-tweet {margin: auto !important;} Hungry for a new dataset? 😋Check out the classification of recipes based off more than 400,000 food images from social media. #deeplearning #machinelearning #deepchef https://t.co/V5XQv4PeEZ — @kaggle function notifyResize(height) {height = height ? height : document.documentElement.offsetHeight; var resized = false; if (window.donkey && donkey.resize) {donkey.resize(height); resized = true;}if (parent && parent._resizeIframe) {var obj = {iframe: window.frameElement, height: height}; parent._resizeIframe(obj); resized = true;}if (window.location && window.location.hash === "#amp=1" && window.parent && window.parent.postMessage) {window.parent.postMessage({sentinel: "amp", type: "embed-size", height: height}, "*");}if (window.webkit && window.webkit.messageHandlers && window.webkit.messageHandlers.resize) {window.webkit.messageHandlers.resize.postMessage(height); resized = true;}return resized;}twttr.events.bind('rendered', function (event) {notifyResize();}); twttr.events.bind('resize', function (event) {notifyResize();});if (parent && parent._resizeIframe) {var maxWidth = parseInt(window.frameElement.getAttribute("width")); if ( 500 < maxWidth) {window.frameElement.setAttribute("width", "500");}} Preface Since the invention of the Internet, the Internet has clearly shaped the coming decades. Nowadays, the smartphone can access huge amounts of data within seconds, communication with people from around the world are almost instantaneous. On the advancement to revolutionize the world like the Internet is Artificial Intelligence. It has become indispensable and has been in operation in large companies for a long time such as in Amazon or Netflix. But especially in recent years the media presence for Artificial Intelligence has risen sharply. You hear successes from all corners of the industrial world, which in turn attract more companies, to adapt theirs Business strategy to today’s Big Data and Machine Learning trend to certainly not lose the connection. But the concept of machines without explicit learning algorithms is nothing new, in fact the first successes were made in the 60s. Rather, it is the massive data collection rage which opens a whole new world of possibilities. The term artificial intelligence has become a click-bait title of the media world, the dream of computers comparable to man to make intelligent decisions, assess situations and lead long conversations, is still in the distance. The driving force of, for example, self-driving cars are rather mathematical models that achieve success with the amount of data and improved computer performance that was impossible to achieve nearly 30 years ago. An important role is played by Image Classification: recognition of content in images. At the end of 2015, Google had a library open sourced, called TensorFlow, which in the media was defined among other reasons as one of the driving forces for the success of Google Translator. Thanks to Google and now many other facilities, everyone has access to these “intelligence” or models and can train them more or less at home on the computer. The question I asked myself was, what can I do with it? Hardly any other area affects human well-being to a similar extent as nutrition. Every day countless of food pictures are published by users on social networks; from the first home-made cake to the top Michelin dish, the joy of the world is shared with you in case a dish is successful. It is a fact that no matter how different you may be from each other, good food is appreciated by everyone. Advances in the classification or object recognition of individual cooking ingredients are sparse. The problem is that there are almost no public edited records available. This work deals with the problem of automated recognition of a photographed cooking dish and the subsequent output of the appropriate recipe. The distinction between the difficulty of the chosen problem and previous supervised classification problems is that there are large overlaps in food dishes, as dishes of different categories may look very similar only in terms of image information. Looks similar, but doesn’t taste similar! The tutorial is subdivided into according to the motto : smaller parts divide and conquer According to the current state, the largest German-language dataset of more than 300'000 recipes will be scraped and analyzed. Then, a newly developed method, according to the author’s knowledge, will be presented: the combination of object recognition or cooking court recognition using Convolutional Neural Networks (short CNN) and the search of the nearest neighbor of the input image (Next-Neighbor Classification) in a record of over 400,000 images. This combination helps to find the correct recipe more likely, as the top-5 categories of the CNN are compared to the next-neighbor category. The exact solution is the following: For every recipe it has number of pictures. For each of the images feature vectors are extracted from a pre-trained Convolution Neural Network trained on 1000 categories in the ILSVRC 2014 image recognition competition with millions of images. The feature vectors form an internal representation of the image in the last fully connected layer before the 1000-category Softmax Layer which was removed beforehand. These feature vectors are then dimensionally reduced by PCA (Principal Component Analysis) from an matrix to an matrix, where . As a result, one chooses the top 5 images with the smallest Euclidean distance to the input image, i.e. the top 5 optical, just from the picture information, similar pictures to the Input image. W K N x 4096 N x V V < 4096 Furthermore, a CNN is trained with number of categories with pictures of recipes. has been determined dynamically using topic modeling and semantic analysis of recipe names. As a result one gets for each category a probability to which the input image could belong. C W C The top 5 categories of the input image of the CNN (2.) are compared with the categories of the top 5 optically similar images (1.) The schema to visualize the method looks like this: 1│── │ └── Clearing data│ └── Data augmentation Data preparation 2│── Data analysis and visualization, split data(Train, Valid, Test) 3│── │ └── Latent Dirichlet Allocation (LDA)│ └── Non-negative Matrix Factorization Topic Modeling 4│── │ └── k-nearest neighbors│ └── t-SNE visualization Feature Extraction 5│── │ └── AlexNet, VGG, ResNet, GoogLeNet Transfer Learning: Training pre-trained CNN (Convolutional Neural Network) 6└── Deploying with Flask Each part contains Jupyter notebooks which you can view on the . Github page Part I: Scraping and preparing the data In order to be able to train a model at all, you need enough data (so-called data augmentation and fine-tuning of pre-trained models can be used as a remedy). Only because of this amount of data can generalization of the training set be continually increased to some degree and high accuracy can be achieved in the test set. The first part of this tutorial deals with the data acquisition, analysis and visualization of features and their relationships. Peter Norvig, Google’s Director of Research, revealed in an interview in 2011 We do not have better algorithms. We just have more data. Without exception, the quality and quantity of the data set are not negligible. That’s why Europe’s biggest cooking platform will be scraped: each recipe, finally 316'756 recipes (as of December 2017), are downloaded with a total of 879'620 images. It is important not to proceed too fast when downloading and to protect the servers with too many queries, since otherwise a ban of the own IP address would make the data collection more difficult. More data leads to more dimensions, but more dimensions do not necessarily lead to a better model. Deviating patterns in the data set which disturb the learning can be unintentionally amplified by more dimensions, a generalization and learning of the data record is impaired for the neural network, the signal-to-noise ratio decreases. All 300k recipes sorted by date: http://www.chefkoch.de/rs/s30o3/Rezepte.html When doing website scrapping, it is important to respect the robots.txt file. Some administrators do not want visits from bots to specific directories. provides: https://www.chefkoch.de/robots.txt User-agent: * # directed to all spiders, not just scooters Disallow: / cgi-bin Disallow: / stats Disallow: / pictures / photo albums / Disallow: / forumuploads / Disallow: / pictures / user / Disallow: / user / Disallow: / avatar / Disallow: / cms / Disallow: / products / Disallow: / how2videos / Listed are directories that do not interest us, so you can confidently continue. Nevertheless, measures such as random headers and enough big pauses between the individual requests are recommended to avoid a possible ban of the website. # Chefkoch.de Website CHEFKOCH_URL = 'http://www.chefkoch.de' START_URL = 'http://www.chefkoch.de/rs/s' CATEGORY = '/Rezepte.html' category_url = START_URL + '0o3' + CATEGORY def _get_html(url): page = '' while page == '': try: page = requests.get(url, headers=random_headers()) except: print('Connection refused') time.sleep(10) continue return page.text def _get_total_pages(html): soup = BeautifulSoup(html, 'lxml') total_pages = soup.find('div', class_='ck-pagination qa-pagination').find('a', class_='qa-pagination-pagelink-last').text return int(total_pages) html_text_total_pages = _get_html(category_url) total_pages = _get_total_pages(html_text_total_pages) print('Total pages: ', total_pages) Total pages: 10560 A next, important step is therefore feature selection to disadvantage unimportant data. Preparing raw data for the Neural Net is commonplace in practice. In the first pass, the recipe name, the average application for the recipe, the number of ratings, the difficulty level, the preparation time and the publication date are downloaded. In the second pass, then the ingredient list, the recipe text, all images, and the number of times the recipe has been printed. With these features, the data record can be described very well and helps to gain a strong understanding of the data set, which is important to select the algorithms. Data such as recipe name, rating, date from the upload of the recipe, etc. are stored in a csv file. If the recipe has an image, the thumbnail is placed in the search_thumbnails folder. We will make usage of multiprocessing to ensure shorter download time. For further information visit Python’s Documentation def scrap_main(url): print('Current url: ', url) html = _get_html(url) _get_front_page(html) #sleep(randint(1, 2)) start_time = time() with Pool(15) as p: p.map(scrap_main, url_list) print("--- %s seconds ---" % (time() - start_time)) Please note the given code has been shortened. For the full code visit the . corresponding Jupyter Notebook Next we need to scrape the list of ingredients, the preparation, the tags and all images of each recipe. def write_recipe_details(data): dpath = DATAST_FOLDER + DFILE_NAME with open(dpath, 'a', newline='') as f: writer = csv.writer(f) try: writer.writerow((data['link'], data['ingredients'], data['zubereitung'], data['tags'], data['gedruckt:'], data['n_pics'] #data['reviews'], #data['gespeichert:'], #data['Freischaltung:'], #data['author_registration_date'], #data['author_reviews'] )) except: writer.writerow('') If everything went smoothly with the download, our data looks like this: A total of 879'620 images (35 GB) 316'756 recipes — Of which 189'969 contain one or more pictures — — Of which 107,052 recipes contain more than 2 images — 126'787 contain no picture Part II: Data analysis and visualization Statistics In order to get a first impression, one usually plots a heatmap to get first insights, which features are interesting. The heatmap gives us insight which values correlate with other values. The highest correlation have and . Figure 2 shows the pair plot on the 1st column, 2nd row, and it stands out that the higher the number of ratings, the better the rating of the recipe. Also interesting is the comparison between preparation time and number of ratings. Most reviews are based on recipes with short preparation time. Another idea is to compare the number of newly uploaded recipes per year. votes average_rating It seems that the ChefKoch community prefers easy recipes. In the years 2008 to 2009, it has noticeably the most uploads per year. A quick search search on the internet shows that in 2008 the food price crisis had prevailed. A comparison of the curves (bottom graphic ) shows that there was a . Demand rose for recipes because one stayed at home and cooked for himself and his family in order to save the budget as much as possible. direct correlation between the world’s rising prices and the supply of recipes On the left the and on the right the number of uploaded recipes per year. index Ingredients Altogether share . If you remove all ingredients that occur more than once, it has . For the association analysis of the ingredients the APRIORI algorithm is used. This provides the frequency of what ingredients in combination with other ingredients occur in total how often. 316'755 recipes 3'248'846 ingredients 63'588 unique ingredients On the left are the top 8 and on the right the top 9–16 ingredients with the highest incidence. Leader of the ingredients is salt with 60 percent representation in all recipes. In third place you can see the first tuple, so the combination of two ingredients, namely pepper and salt are with just over 40 percent by far the most common pair. The most common triplets, quadruplets and even quintuplets can be found in the . corresponding Jupyter Notebook More graphics can be found in this notebook . Part III: Topic Modeling The goal of this procedure is to divide all recipe names into n-categories. For a supervised classification problem, one provides the neural network with images which are labeled. It is only with these labels that learning becomes possible. The problem is that Chefkoch.de does not categorize their pictures. Possible procedures to split the 316755 recipe names are shown here. Take the following example:1. Pizza with mushrooms2. Stuffed peppers with peas and tuna3. Pizza with seafood4. Paprika with peas Four recipe names must be divided into n categories. Obviously, 1st and 3rd need to be in the same category called pizza. The 2nd and 4th can also be divided into a new category due to the peas. But how do you manage a lot more than 300 thousand recipe names? Latent Dirichlet Allocation (LDA) LDA is a probability model which assumes that each name can be assigned to a topic. First, the name body must be cleaned, i.e. stop words are removed and words are reduced to their root. The clean vocabulary serves as input. de_stop = get_stop_words('german') s_stemmer = SnowballStemmer('german') tokenizer = RegexpTokenizer(r'\w+') final_names = [] for recipe_name in twentyeigth_iter: raw = recipe_name.lower() tokens = tokenizer.tokenize(raw) stop_t = [recipe_name for recipe_name in tokens if not recipe_name in de_stop and not recipe_name in filter_words_] stem_t = [i for i in stop_t if len(i)>1] if len(stem_t)==0: final_names.append(['error']) else: final_names.append(stem_t) print('20 Cleaned Recipe names example: \n >>>') pprint(final_names[:20]) 20 Cleaned Recipe names example: >>> [['bratapfel', 'rotkohl'], ['frühstückswolke'], ['deichgrafensalat'], ['geschichteter', 'kohl'], ['rinderlendenragout'], ['blaukraut'], ['sauerbraten'], ['punschtorte'], ['oberländer'], ['mcmoes', 'pasta'], ['geschnetzeltes'], ['ahorn', 'bacon', 'butter'], ['endiviensalat'], ['rote', 'linsen', 'gemüse'], ['kotelett', 'gratin'], ['rotkohl'], ['remouladensauce'], ['nudeln'], ['kohlsuppe'], ['gemüse', 'hackfleischauflauf']] 300 topics were set as condition. The model for Topic 89 provides good results: drinks are detected and summarized. For the sake of simplicity, the exact mathematical definition is not discussed. As a result, one has a list of probabilities of how certain the model is that it would fit the topic. Example: ‘0.363 *’ scalloped ‘+ 0.165 *’ spicy ‘+ 0.124 *’ summer “+ 0.006 *” taboulé “+ 0.004 *” oatmeal biscuits “. An interactive graph to browse through each of the 300 topics can be found at code / 04_01_topic_modeling.ipynb in the Github Repo. Non-negative Matrix Factorization The first step is to calculate the tf-idf (term frequency-inverse document frequency). This represents nothing more than the importance of a word in a recipe name, considering the importance in the whole text corpus. The four most important words are: 1. salad (2935.18)2. spaghetti (2429.36)3. torte (2196.21)4. cake (1970.08) The NMF algorithm takes as input the tf-idf and simultaneously performs dimension reduction and clustering. This effort provides excellent results as you can see for the first 4 topics: _salad mixed corn melons chicoree bulgur radish celery q_uinoa lukewarm The result can be visualized using t-SNE. It is important that a record with several dimensions is reduced to 2D, which allows to find a coordinate for each recipe name. Topic # 0: spaghetti carbonara alla olio aglio al sabo puttanesca di mare Topic # 1: Topic # 2: noodles chinese asia mie asian wok udon basil black light Topic # 3: muffins blueberry hazelnut cranberry savory juicy sprinkles johannisbeer oatmeal chocolate Due to the complexity and associated calculation time of t-SNE, a subset of 50,000 was taken. For further information visit the . corresponding Jupyter Notebook Part IV: Feature Extraction Decoupled from nature, neural networks work on the model of the human brain. The idea is that it learns from its mistakes, gradually the weights of the neuron are adjusted to adapt to the data. When it sees new data, it activates the right neurons to produce the desired behavior. With CNNs, the image information is first summarized to reduce the number of parameters. One assumes that the first layers in a CNN recognize rough structures in the picture. The further you proceed to the last Softmax layer, the finer the learned features become. One can take advantage of this, one takes pre-trained CNNs which have been trained with millions of pictures and removes the last layers and trains them with their own data. This saves millions of parameters. The CNN chosen here is the VGG-16 which was trained in a classification competition 2014 on 1000 categories. If you remove the last layer, you get a feature extractor of the second-to-last layer. This forms an nx4096 matrix, where n is the number of input pictures. features = [] for image_path in tqdm(images): img, x = get_image(image_path); feat = feat_extractor.predict(x)[0] features.append(feat) We let the VGG-16 calculate the vector for every image we have. This vector is, so to speak, the an internal representation the neural network builds. fingerprint of the picture: Left the 4096 vector calculated from cake on the right. Now all we have to do is for every new given input image we pass it through the VGG-16, get the fingerprint vector and calculate the nearest neighbors with approximate nearest neighbor search. The library I will use for this is . FALCONN is a library with algorithms for the nearest neighbor search problem. The algorithms in FALCONN are based on (LSH), which is a popular class of methods for nearest neighbor search in high-dimensional spaces. The goal of FALCONN is to provide very efficient and well-tested implementations of LSH-based data structures. FALCONN Locality-Sensitive Hashing Currently, FALCONN supports two LSH families for the : hyperplane LSH and cross polytope LSH. Both hash families are implemented with multi-probe LSH in order to minimize memory usage. Moreover, FALCONN is optimized for both dense and sparse data. Despite being designed for the cosine similarity, FALCONN can often be used for nearest neighbor search under the Euclidean distance or a maximum inner product search. cosine similarity Let’s pass this brownie through our pipe and let’s see what we get. For further information visit the . corresponding Jupyter Notebook We can even create a grid of images to view the interpretation of the neural network. The following picture is only a small part of the whole image. You can see cooking dishes that have similar features are closer together. The whole grid can be found . here Similar cooking dishes are close to each other. That’s a wrap for this tutorial! How to train your own neural network and finally turn our product into a web application with Flask (Part V and Part VI), I’ll pick up for the next tutorial. If you are still hungry for more knowledge, be sure to check out my GitHub . If you think this post was helpful, don’t forget to show your 💚 through 👏 👏and follow me to hear more articles about Deep Learning and Data Science. Also, check out my other stories. Please comment to share your opinion! Cheers! 🙇 This article was written with ❤️ in 🇨🇭.