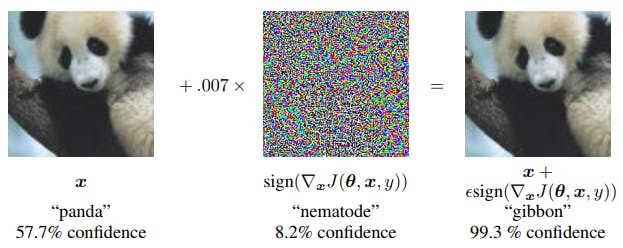
Prelude: Let’s begin with a simple introduction into the world of adversarial inputs. These are inputs into a classifier that have been shrewdly perturbed in such a way that these changes are near damn invisible to the naked eye but can fool the machine learning classifier into predicting either a arbitrary wrong class (Un-targeted) or a specific wrong class (targeted). machine learning There are two defining images that come to my mind when I think of this field at large. The first one is the classic image from . Panda-to-Nematode here The second one, is this one below that provides a geometrical perspective on where these adversarial inputs actually reside. An image that provides a geometrical perspective on the adversarial inputs (Source: ) https://infoscience.epfl.ch/record/229872/files/spm_preprint.pdf Where I , harnessing adversarial examples in a non-computer vision setting for dataset augmentation (to increase both robustness and generalizatibity) forms a key part of our pipeline. In this regard, we have disseminated a few humble attempts such as work Vulnerability of deep learning-based gait biometric recognition to adversarial perturbations , On grey-box adversarial attacks and transfer learning and On Lyapunov exponents and adversarial perturbations. Recently while dabbling with the idea of using to generate mutually adversarial pairs of images, I chanced upon this fuzziness surrounding one of the more fundamental questions of machine learning: What does constitute a true label and how do machine learning companies offering commercial off-the-shelf (OTS) define the same? interpolated style transfer APIs TLDR: 1: We describe an experiment that entailed using style transferred images to target mis-classification in the context of a specific popular commercial off-the-shelf (OTS) API (I use the API for all the results shown here.) Watson Visual-Recognition- V3 API, version 2016–05–20 2: The style transferred images achieved adversarial attack success rates of 97:5 % (195 out of 200). 3: The goal is or to berate the commercial API used, but to merely highlight the fuzzing surrounding what constitutes a true label or a true tag. This is one account of the simple observation that while using interpolated style transfer as a method for generating mutually adversarial pairs, the ’ ’ that is adversarially perturbed is not necessarily a naturally occurring image and is a style-transferred image itself. not to proclaim a new blackbox attack recipe raw image 4: Pitch the idea of using interpolated style transfer as a recipe of generating mutually adversarial pairs that can be used for model regularization as well as generating co-class images as inputs into training pipelines for Siamese-net like trained on triplet-loss cost functions. challenging embedding deepnets 5: Pitch the idea of using the interpolated weight as the in here: new semantic epsilon Time for a new ? semantic epsilon The Deep-dive: With this prelude in tow, the deep dive now begins. Let’s start by focusing on the figure below: Cat2Fabric: The journey of a cat’s image into a pattern What we see is the of the image of a cat getting style-transferred into a ‘pattern-style-image’ using the [2] project for different interpolation weights monotonically increasing from 0 to 1 (from the left to the right). As seen, with the raw image (interpolation weight ( )) or style-transferred images with low interpolation weights (up until interpolation weight ) as inputs, the commercial OTS classification API has, as expected classified the image as a with high confidence scores (0.97 to 0.99). When we increase the interpolation weight slightly to , we see a dramatic change in the inferred label landscape. The top guessed classes dramatically change from to . While the two images are virtually indistinguishable for the naked eye and are merely apart in terms of the structural similarity distance (which is [4]) ( apart in terms of the infinity-norm distance), the labels assigned for the two images by the black-box classifier turn out to be wildly different. Thus, we refer to this pair as constituting a with regards to the black-box classifier and the distance metric used. The local texture based features that the classifier might have learned, has perhaps coaxed it into making erroneous classification, while the image still clearly looks like that of cat. Now emerges a natural query whether the artistically style transferred image (with to be classified as a in the first place. This is akin to another related question of what is the normative expected class when the input is a real world figurine rather than an animate being, which brings us to the figure below. journey arbitrary image stylization Magenta w=0 w=0.1 correctly cat w=0.15 feline, cat and carnivore cellophane, moth and invertebrate 0.03 1-structural similarity index 0.125 mutually adversarial pair synthetically generated w=0.1) deserved cat Is this a ‘Cat’ or a ‘Cat-figurine’? Here, we see the input image ( The image was sourced from ). We find this specific shopping portal to be an especially good source of such figurine art examples.literally being that of an artistic cat figurine that results in a high confidence classification of being categorized a with high confidence score ( ). here cat 0.89 It is indeed legitimate to ask if the cat example discussed above was idiosyncratically chosen. In order to assuage those concerns, we did the following experiment.The main querying point behind the experiment was as follows: For this, we extracted 200 randomly chosen cat images from the dataset. We resized all of them to size 299 x 299 and style transferred each one of them using the same style image extracted from the DTD dataset[1] using the style transfer algorithm detailed in [2]. The figure below showcases this with a specific example. Specific of the experimentation procedure: Is it indeed the case that images that are style transferred with a global low interpolation weight do result in mis-classifications? Kaggle Dogs and Cats The concept In order to ensure that the images still looked ‘cat-like’ the interpolation weight was set to a value of . One can sift through all the raw images and the style transferred images as a gif animation here below. low 0.125 Gif of true images and their style transferred counterparts Now, both the raw images and the style transferred images were classified using the API.The that sets the language of the output class names was set to .The was set to the default option ( ).The was set to that required no training and would . The parameter that represents the minimum score a class must have to be returned was set to .The results are covered in the forthcoming section. Watson Visual Recognition- V3 API, version 2016–05–20 Accept-Language header string en owners query array IBM classifier-ids default Return classes from thousands of general tags threshold query 0.5 Results: Histogram of the top inferred labels In the figure above, we see the counts of the most probable classes that the API returned. As seen, the top 4 classes that encompassed more than of the test images were . 50% crazy quilt, camouflage, mosaic and patchwork In the figure below, we see the scores as well as the histogram of scores related to the 200 classification trials. Scores and histogram of scores returned by the Watson classifier for the 200 test images As seen, we have an overwhelmingly large number of cases where the mis-classifications were made with high confidence scores associated. In the figure below, we see the 5 images that the API classified correctly. The lucky 5: Correctly classified as ‘Cat’ by Watson Now, in this figure, we see randomly chosen 6 examples of style transferred images that were classified incorrectly. 6 random not-so luckies Due to limitations of API usage for free-tier users, we could not extend the experiment for larger datasets, which is our immediate goal. Besides this, another question that we would like to explore is the choice of the style image. We selected an image for the texture dataset on account of 2 reasons. The first being that a pre-trained style transfer model was readily available. The second reason was based on a hunch that texture, would be in fact be the right aspect of the image to to induce a mis-classification.As stated in the prelude, our intention is not to proclaim a new black-box attack or to berate the commercial API. Conclusion and Future Work perturb Besides showcasing the potential of looking at style transfer as an adversarial example generating technique, we also wanted to draw attention to the inherent fuzziness that surrounds the definition of what constitutes an image class/category or ‘tags’ in the case of such APIs and what entails an image mis-classification.The API that we used the technology as: . With regards to the specific , it was stated that upon usage with Pre-trained models (in lieu of a custom trained classifier), the API On the concluding note, we would like to remark that we also ascertained the efficacy of these style-transferred based black-box attacks using the universal adversarial images for different Deep-nets from [3] as the style image, the results of which we plan to disseminate in the full version of this work. describes Watson Visual Recognition’s category-specific models enable you to analyze images for scenes, objects, faces, colors, foods, and other content API documentation Returns classes from thousands of general tags. Links: (This work will be presented at the @ CVPR-2018) CV-COPS workshop Github: https://github.com/vinayprabhu/Art_Attack Poster: Poster for the paper References [1] M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, and A. Vedaldi. Describing textures in the wild. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 3606–3613. IEEE, 2014. [2] G. Ghiasi, H. Lee, M. Kudlur, V. Dumoulin, and J. Shlens. Exploring the structure of a real-time, arbitrary neural artistic stylization network. arXiv preprint arXiv:1705.06830, 2017. [3] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard. Universal adversarial perturbations. https://arxiv.org/abs/1610.08401 [4] Z.Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600– 612, 2004.