
314 reads
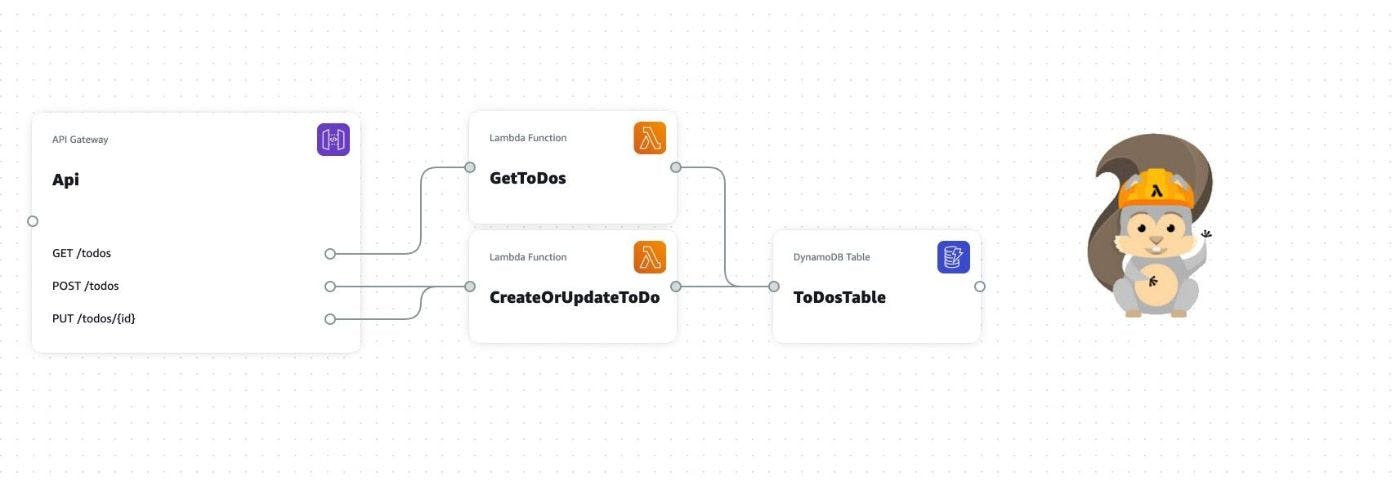
Building Your Infrastructure With Just a Diagram
by byIldar Sharafeev@isharafeev
byIldar Sharafeev@isharafeev
Sr Software Engineer. decade+ in the industry. Passionate about frontend, micro-frontends, serverless, and clean code.
January 26th, 2023





Audio Presented by
Sr Software Engineer. decade+ in the industry. Passionate about frontend, micro-frontends, serverless, and clean code.


Sr Software Engineer. decade+ in the industry. Passionate about frontend, micro-frontends, serverless, and clean code.
About Author

Sr Software Engineer. decade+ in the industry. Passionate about frontend, micro-frontends, serverless, and clean code.
Comments
















