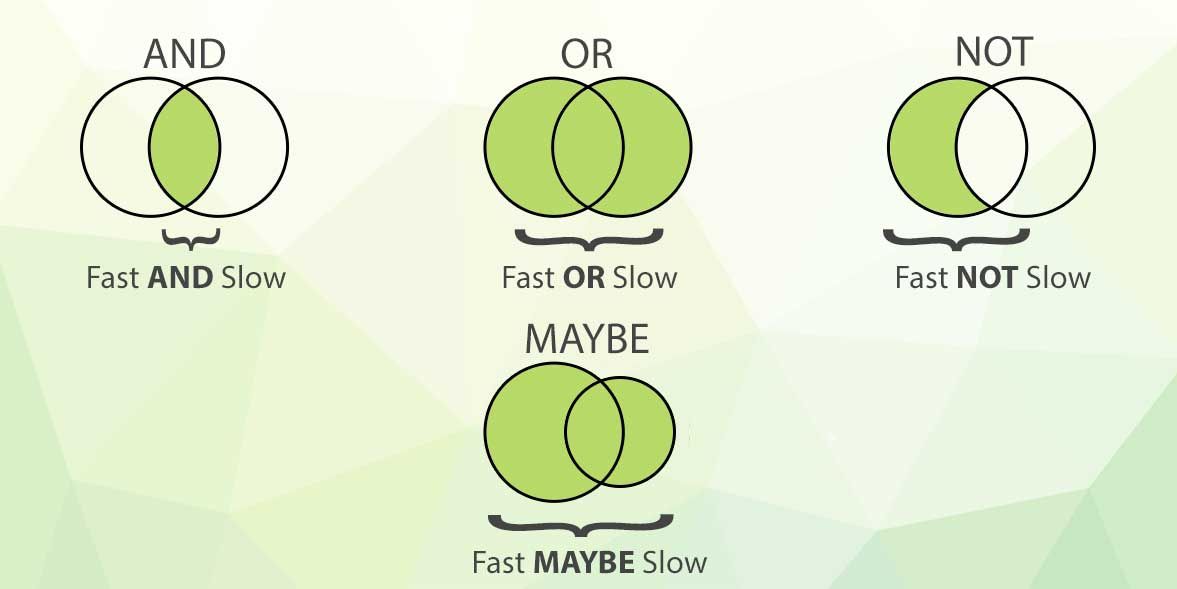
229 reads
Bite-Sized Tips To Make Chinese Full-Text Search
by byGreg@gregdevogo
byGreg@gregdevogo
Experienced BackEnd dev, trying to balance between madness, creativity and procrastination
September 27th, 2020





Experienced BackEnd dev, trying to balance between madness, creativity and procrastination


Experienced BackEnd dev, trying to balance between madness, creativity and procrastination
About Author

Experienced BackEnd dev, trying to balance between madness, creativity and procrastination
Comments