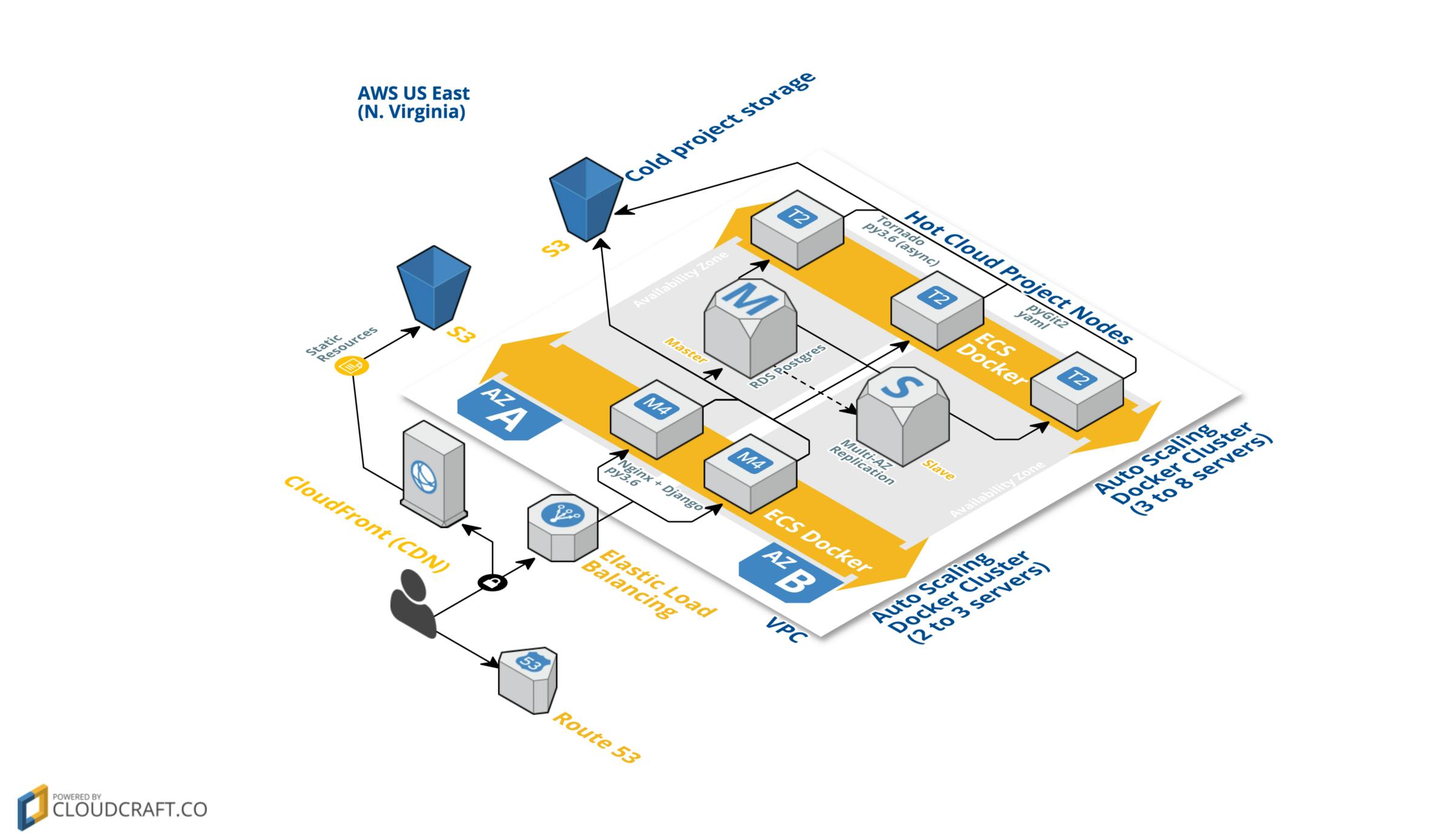
When it came to designing the infrastructure needed to back the Paw Cloud syncing service, we wanted to build it in a way that each component could be unplugged without the consequence of user data loss. As we found out that many users of were sharing their work over Dropbox, Git or as Slack attachments, we realized that we had the opportunity to build a great syncing service to help their API development efforts. We wanted to build something that’s both seamless for the users and reliable to be trusted on a daily basis by the engineers using our product. Paw We have 2 sets of auto scaling ECS (EC2 Container Service, aka. Amazon EC2 for Docker) clusters making up the core backbone of serving both the website and the cloud sycning solution . paw.cloud Paw for Teams When I joined the Paw team in October 2015, our website ( at the time) was hosted by a single instance on Digital Ocean. With team syncing features planned we set out to build our new infrastructure on Amazon with the goal of high redundancy and statelessness operations of all deployed code. luckymarmot.com AWS Two things however cannot be stateless: database and customer project storage. So we chose to use AWS’s Relational Database Service (RDS) with PostgreSQL and S3 to provide the stateful storage solution. In doing so we are now able to expand and shrink both our public facing Django servers and our cloud syncing worker nodes without any worry about data consistency and loss. Our website and all of our APIs are served through a Docker container of the first set of Docker clusters (the most public facing one) as seen above. This container contains Nginx mapping through uWSGI to (1.10.6) running on . Django Python 3.6 Our web frontend is a hybrid mix of Django static templates rendered server-side for non-authenticated landing pages and for account, and pages. We feel this provides a good balance between dynamic content pages that are harder for search engines to crawl and static pages. The exception to this is our docs were we have a very custom solution for producing static HTML content for search engines and legacy browsers while serving richer content with React. All web assets (stylesheets, JS, etc.) are served through the CloudFront CDN backed by an Amazon S3 bucket. React purchase documentation For managing our cloud syncing service all requests first pass through Django (where users are authenticated) and are passed on upstream to another auto scaling Docker cluster running (an asynchronous Python-based web framework) again on 3.6. This was a joy to write in Python 3.5+, taking advantage of the fully asynchronous runtime and syntax . Our public facing Django cluster is responsible of routing requests to the appropriate backend Tornado instance, and when a project is cold on Amazon S3, of loading it on the most available backend instance. As project writes happen a backup of the full project is pushed to S3 and the project version hash is persisted in the Postgres database to ensure data consistency. Tornado Python (async, await) Upcoming articles about the Paw Cloud infrastructure will cover reStructuredText as source for an adaptive React based product documentation platform, Modifying files stored outside of PostgreSQL while maintaining full transaction safety and stateless design . Git as a cloud storage backend for complex multiobject documents: a pathway to follow?