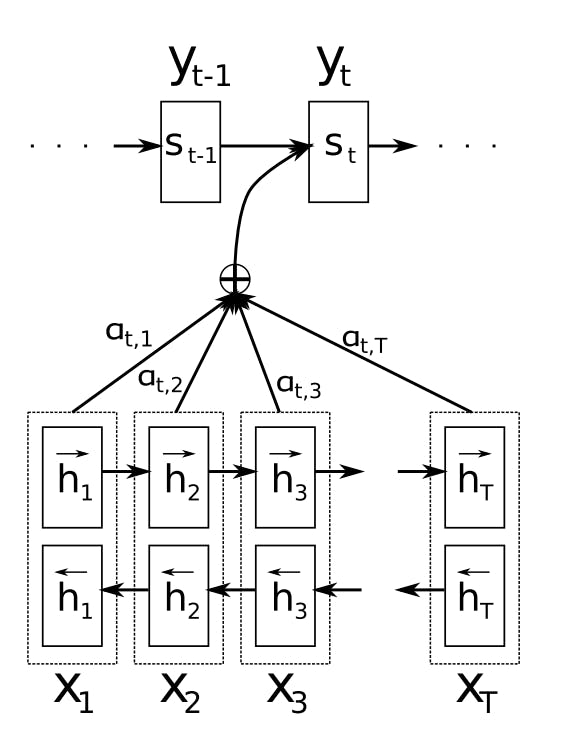
An reads and encodes a source sentence into a . Encoder fixed-length vector A then outputs a translation from the encoded vector. Decoder Limitation A potential issue with this encoder–decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a . fixed-length vector How Attention solves the problem? Attention Mechanism allows the decoder to attend to different parts of the source sentence at each step of the output generation. Instead of encoding the input sequence into a , we let the model learn for each output time step. That is we let the model what to attend based on the input sentence and what it has produced so far. single fixed context vector how to generate a context vector learn Attention Mechanism Here, the generates from the inputs Encoder h1,h2,h….hT X1,X2,X3…XT Then, we have to find out the for each of the output time step. context vector ci How the Context Vector for each output timestep is computed? is the which is a that is trained with all the other components of the proposed system a Alignment model feedforward neural network The scores (e) how well each encoded input (h) matches the current output of the decoder (s). Alignment model The alignment scores are normalized using a softmax function. The context vector is a weighted sum of the (hj) and annotations normalized alignment scores. Decoding The Decoder generates output for i’th timestep by looking into the i’th context vector and the previous hidden outputs s(t-1). Reference — , 2015. Neural Machine Translation by Jointly Learning to Align and Translate