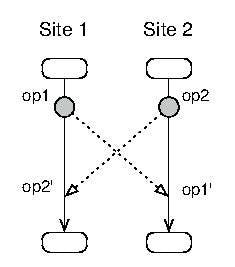
Introduction This is the third post in my series of , the real time collaborative editing algorithm. The first and second posts were and respectively. Operational Transformation (OT) How Real-Time Collaborative Editors work? [Operational Transformation] Operational Transformation, the real time collaborative editing algorithm As mentioned in earlier posts, Operational transformation was originally born due the need of consistency maintenance in collaborative text editors. In the span of over two decades OTs have gained new capabilities (such as undo operations and group undo) and have been applied to different applications ranging from HTML/XML editing, office and even 3D digital media design tools. tools There are many established approaches that exists to operational transformation. In this post, I will walk through the different OT algorithms that are well defined and implemented. Definitions/Terms used : In the post, I explained about the two kinds of Transformation functions, i.e, Inclusion Transformation and Exclusion Transformation. These functions have two properties/preconditions which ensures OT correctness. TP1 and TP2 are the transformation/convergence properties. second For two concurrent operations O1 and O2, the transform function (T) satisfies TP1 iff O1 T(O2, O1) ≡ O2 T(O1, O2) where denotes the sequence of operations containing Oi followed by Oj and ≡ denotes the equivalence of the two operations. : TP1 is required only if the Operational Transformation system allows any two operations to be executed in different orders. TP1 : o o o Precondition of TP1 For three concurrent operations O1, O2 and O3, the transform function (T) satisfies TP2 iff T(O3, O1 T(O2, O1)) ≡ T(O3, O2 T(O1, O2)). : TP2 is required only if the OT system allows two operations O1 and O2 be IT-transformed in two different document states (or contexts). TP2 : o o Precondition of TP2 TP2 property illustration 1. dOPT — distributed OPerational Transformation The dOPT Algorithm was one of the first approaches to OT. In dOPT Algorithm, each machine has an identifier i, which could be an IP or MAC. Each machine has to maintain a state vector s with components where is the number of machines. The component store the number of changes recorded by the machine. The requests are of the form: <i, s, o, p> n n i ith i — the original site’s identifier s — the state vector of the machine which is sending o — the operation which needs to be performed p — the priority which is associated with o [ ] this is where the algorithm got wrong A transformation matrix, denoted as T, is what solves . T is a matrix, where is the number of supported operations in the group- ware system. Each entry in the matrix is a function which transforms operations into other operations and to ensure convergence dOPT requires the Transformation Property 1. conflicting operations m x m m For handling requests, the actions are based on comparisons between [sending state] and [receiving state]. If they are same i.e , is executed immediately, if is queued and executed later and if is transformed and then executed. s_i s_x s_i = s_x o s_i > s_x, o s_i < s_x, o Strengths of the algorithm : Immediate feedback for local operations. Does not require locking of resources. Relatively easy to implement due to its simple data structures. Satisfies the which is defined as_, a_ consistency property which ensures that the execution order is the same as the operations natural cause-effect order. In other words if an operation causally precedes another operation , then at every site will be executed before . precedence property, O1 O2 O1 O2 Enforces the Transformation property 1. Problems: The priority, , suggested doesn’t work great for two clients. It fails whenever an operation is concurrent with two or more dependent operations. This algorithm is distributed and have a central server. p does not 1.1. adOPTed Algorithm The shortcomings in dOPT were in the way it transformed operations. The adOPTed introduced the second transformation property [TP2] which ensures that transformation of an operation along different paths will yield the same resulting operation. The adOPTed algorithm is right in general, and solves most of the shortcomings of dOPT algorithm but which is defined as, a consistency property which ensures that the intention of an operation is preserved after a transformation. The intention of an operation, , is the effect of applying on the resource where the operation was generated. has not proved Intention Preservation property, O O Also, the intent is always . Machines have no intent, Humans do. That’s why preserving intention becomes of sufficient importance. _of the user_ 2. GOT and GOTO — Generic and Generic Optimized Operational Transformation GOT control algorithm maintains convergence nicely i.e. when the same set of operations have been executed at all sites, all copies of the document which is shared are identical. Also, it is integrated with which states that when a new operation is ready; Undo/Do/Redo Scheme O operations in (which is defined as ‘saved executed operations at each site’) which totally follow to restore the document to the state before their execution. Undo History Buffer ( HB_)_ O (the operation) Do O all operations that were undone from the HB. Redo Also, in this convergence TP2 is not a necessary condition i.e the precondition CP2/TP2 is required only if the OT systems allows two operations op1 and op2 be IT-transformed [inclusion transformation] in two different document states. Strengths of the algorithm : OT based undo is established, faster and more efficient undo based operations. is fulfilled, which is defined as, a consistency property which ensures that copies of a shared resource are identical at all sites in state of rest (i.e. ensuring that all operations are executed). Convergence property Problems : The algorithm only supports basic string operations i.e Insert/Delete. Also, correctness proof of algorithm is missing. Algorithm is the ptimized version of GOT Algorithm. The optimization takes place because of two postconditions, and to reduce the number of (Inclusion/Exclusion) transformations by adding the properties from adOPTed. GOTO O TP1 TP2 IT/ET GOTO algorithm uses the function which basically uses ET between an insert and a delete [concurrent], what basically happens is we transpose the entire history to obtain the concurrent operations when integrating a remote operation. The algorithm fulfills the convergence property, precedence property, TP1, TP2 and has better undo operations, but was . convert2HC() never theoretically proven correct for all scenarios 3. COT — Context-based Operational Transformation The COT algorithm does not use a history buffer (HB) when an operation is executed, instead it keeps track of the document state in which a operation have been executed in. So instead of a HB it has a context vector. In an OT-based collaborative editor, a document state can be uniquely characterized by the set of original operations executed so far on the document. These original operations may be executed in different orders or forms at different sites, but they must produce the same document state according to the convergence/transformation properties . Moreover, the difference between two document states can be expressed in terms of different original operations executed in these two states. Since every transformed operation must come from an original operation, is used to denote the original operation of O. org(O) A document state, denoted as , can be represented as : DS The initial Document State is represented by DS = { } After executing an operation on , the new Document State . O DS DS’ = DS ∪ { org(O) } An operation is defined by a site identifier and a number given when it is generated. This operation in turn has that contains the operation context in terms of operations that precedes it. The operations inside the context vector in turn have their own site identifiers and defining numbers. a context vector This is the main difference since COT heavily relies on every operation which is to be executed on the same document state on all locations, if the operation is executed on the same document state at all sites the result can not diverge. A context vector, denoted as CV(O), can be represented as : where and CV(O) = [(ns⁰, ic⁰), (ns¹, ic¹), . . . , (ns^N-1, ic^N-1)] 0 ≤ i ≤ N-1 represents all original normal operations at site i ns^i represents all inverse operations for normal operations at site . ic^i = [(ns⁰, is⁰), (ns¹, is¹), . . . , (ns^k-1, is^k-1)] undoing i Also to capture the essential requirements for correct operation execution and transformation, a set of six rules called were introduced. Context-based Conditions (CCs) : Given a original O and a DS, where O ∉ DS, O can be transformed for execution on DS only if C(O) ⊆ DS. CC1 operation document state : Given an original operation O and a document state DS, where O ∉ DS and C(O) ⊆ DS, DS-C(O)² is the set of operations that O must be transformed against before being executed on DS. CC2 : Given any operation O and a state DS, O can be executed on DS only if C(O) = DS. CC3 : Given an original operation Ox and a operation O of any type, where Ox ∉ C(O), Ox can be transformed to the context of O only if C(Ox) ⊆ C(O). CC4 : Given an original operation Ox and a operation O of any type, where Ox ∉ C(O) and C(Ox) ⊆ C(O), C(O) ≠ C(Ox) is the set of operations that Ox must be transformed against before being IT-transformed with O. CC5 : Given two operations Oa and Ob, they can be IT-transformed with each other IT(Oa,Ob) or IT(Ob,Oa), only if C(Oa) = C(Ob). CC6 Due to these conditions and the context vector the COT algorithm is optimized to the extent that it does not even have a need for the transformations. This is made possible because of the context vector that enables a better use of s. ET IT Strengths of the algorithm: Fulfils the convergence property. Fulfils the precedence property. Platform capable of more than text editing. Has been well tested as it has been implemented in several editing programs such as CoMaya, CoWord and more. Problems : Requires more memory than other algorithms because of the nature of context vectors but can be optimized in the same way other algorithms have. 4. Google Wave OT Algorithm Wave OT is basically based on the algorithm given by Jupiter System [dOPT algorithm]. Having a simple and efficient server is important in making wave’s reliable and scalable. With this goal, Google’s Operational Transformation algorithm modifies the basic theory of OT by requiring the client to wait for (In the post, I have explained Client — Server Acknowledgement approach) from the server before sending more operations. When a server acknowledges a client’s operation, it means the server has transformed the client’s operation, applied it to the server’s copy of the wavelet and broadcast the transformed operation to all other connected clients. While the client is waiting for the acknowledgement, it caches operations produced locally and sends them in bulk later. Google acknowledgement [ACKs] second With the addition of acknowledgements, a client can infer the server’s OT path. By having this, the client can send operations to the server that are always on the server’s OT path. This has the important benefit that the server only needs to have , which is the history of operations it has applied. When it receives a client’s operation, it only needs to transform the operation against the operation history, apply the transformed operation, and then broadcast it. This source of truth also forces the client to wait for the server to the operation that the client has just sent which would mean that the client always stays on the server’s OT path. This would help in keeping a single history of operations without actually having to keep a mirror of the state for each client that is connected. That would eventually mean the number of clients that are connected to the server would have only one single copy of the document on the server. One trade off of this change is that a client will see from another client in intervals of approximately one round trip time to the other client. a single state space acknowledge chunks of operations (accumulated batch operations) Google Wave OT solves most of the flaws by its Acknowledge command and by strictly limiting the number of participants in communication to . If the number of clients were increased to three, of the time, conflicts arose. However, there is one flaw that might have slipped through, which is . two 17% intention preservation Conclusion The viable solution would be to incorporate with , since COT would be able to provide a better intention preservation. Also, COT algorithm is not based on when the operation arrives at different places but in what context [CV(O)] the original operation was executed in. Therefore at each site when Oi arrives a comparison will be made with Oi’s context vector and the site’s own document state. Context based OT Google wave OT Also, note that not all Operational Transformation approaches has been taken into considerations. I have merely listed those which I believed are the most significant ones. I would also be researching and writing another post on why Google Wave OT failed in practice by using whatever source code provided by Google implementing a test to prove that Waves OT fails to preserve true intention in practice. Also, I may perform a benchmarking with COT and Google Wave together to know if really COT can be incorporated with Google Wave’s OT. References High Latency, Low-Bandwidth Windowing in the Jupiter Collaboration System Authored by David A. Nichols, Pavel Curtis, Michael Dixon, and John Lamping. Achieving Convergence, Causality Preservation, and Intention Preservation in Real-Time Cooperative Editing Systems Authored by Chengzheng Sun, Xiaohua Jia, Yanchun Zhang, Yun Yang and David Chen. Operational Transformation in Real-Time Group Editors: Issues, Algorithms, and Achievements Authored by Chengzheng Sun and Clarence (Skip) Ellis. Compensation in Collaborative Editing Authored by Stephane Weiss, Pascal Urso and Pascal Molli Context-Based Operational Transformation in Distributed Collaborative Editing Systems Authored by David Sun and Chengzheng Sun Operational Transformation for Dependency Conflict Resolution in Real-time Collaborative 3D Design Systems Authored by Agustina, Chengzheng Sun, Dong Xu Proving Correctness of Transformation Functions in Real-Time Groupware Authored by Abdessamad Imine, Pascal Molli, Gerald Oster and Michael Rusinowitch Undo Any Operation at Any Time in Group Editors Authored by Chengzheng Sun A Survey on Operational Transformation Algorithms: Challenges, Issues and Achievements Authored by Santosh Kumawat and Ajay Khunteta A Performance Study of Group Editing Algorithms Authored by D. Li and R. Li Copies Convergence in a Distributed Real-Time Collaborative Environment Authored by Nicolas VIDOT, Michelle CART, Jean FERRIÉ, Maher SULEIMAN Google’s whitepaper on Operational Transformation Concurrency Control in Groupware Systems Authored by C.A. Ellis, S.J. Gibbs Wikipedia on Operational Transformation One of the most informative articles, I have found on wikipedia, suprisingly.