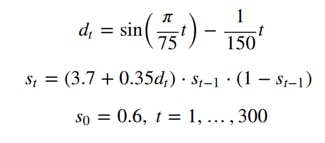I recently started PhD studies in machine learning at Ruhr University Bochum. One of the main research topics of the group I joined is called Slow Feature Analysis (SFA). To learn about a new topic, I like seeing examples and intuitive explanations if possible before submerging myself in mathematical rigor. I wrote this blog post for others who like approaching subjects in a similar manner, as I believe that SFA is quite powerful and interesting. In this post I’ll lead with a code example where SFA is applied, to help motivate the method. Then I’ll go into more detail about the math behind the method and finally provide links to other good resources on the material. 1. Determining a smooth latent variable SFA is an unsupervised learning method to extract the smoothest (slowest) underlying functions or from a time series. This can be used for dimensionality reduction, regression and classification. For example, we can have a highly erratic series that is determined by a nicer behaving latent variable. features Let’s start by generating time series and D S: <a href="https://medium.com/media/eb21f9e38f260e44cc189d0519724165/href">https://medium.com/media/eb21f9e38f260e44cc189d0519724165/href</a> This is known as the logistic map. By plotting the series , we can inspect its chaotic nature. The underlying time series that’s driving the behavior of the curve above is much simpler: S D <a href="https://medium.com/media/c1b2f8e7cef9961881db6fec59c437d1/href">https://medium.com/media/c1b2f8e7cef9961881db6fec59c437d1/href</a> How can we determine the simple, underlying driving force from the erratic time series? We can use SFA to determine the most slowly varying features of a function. In our case, we would start off with data like and end up with , without necessarily knowing beforehand how is generated. S D S Implementations of SFA aim at finding features of the input that are . But as we can see from our example, the driving force is highly non-linear! This can be remedied by doing a non-linear expansion of the time series first, then finding linear features of the expanded data. By doing this we find non-linear features of the original data. linear D S Let’s create a new multivariate time series by stacking time delayed copies of on it: S <a href="https://medium.com/media/74b5d3081145588c5f4a721a2a57ff93/href">https://medium.com/media/74b5d3081145588c5f4a721a2a57ff93/href</a> Next we do a cubic expansion of the data and extract the SFA features. A cubic expansion turns a 4 dimensional vector [ , , , ]ᵀ into the 34 element vector with elements , t²v, tvu, t_²_, tv, t_ for distinct ∈{a, b, c, d}. a b c d t_³ t, u, v <a href="https://medium.com/media/69ae30d6cb09be6d313ae5a161f42fe4/href">https://medium.com/media/69ae30d6cb09be6d313ae5a161f42fe4/href</a> Keep in mind that the best number of time delayed copies to be added varies from problem to problem. Alternatively, if the original data is too high-dimensional then dimensionality reduction needs to be done, for example with . Principal Component Analysis Consider thus the following to be the hyperparameters of the method: the method of dimensionality expansion (reduction), the output dimension after expansion (reduction) and the number of slow features to be found. Now, after adding the time delayed copies, the length of the time series changed from 300 to 297. The corresponding length of the slow feature time series is thus 297 as well. For nicer visualization here, we turn it to length 300 by prepending the first value to it and appending the last value two times. The features found by SFA have zero mean and unit variance, so we normalize as well before visualizing the results. D <a href="https://medium.com/media/ebfa6a0a4a087c1a9943cfc9875099cc/href">https://medium.com/media/ebfa6a0a4a087c1a9943cfc9875099cc/href</a> Even considering only 300 data points, the SFA features manage to almost completely recover the underlying source - which is quite impressive! <a href="https://medium.com/media/538bc4a47e52faeb3abf5f8c1eb6399d/href">https://medium.com/media/538bc4a47e52faeb3abf5f8c1eb6399d/href</a> 2. So what’s going on under the hood? Theoretically, the SFA algorithm accepts as input a (multivariate) time series and an integer indicating the number of features to extract from the series, where is less than the dimension of the time series. The algorithm determines functions X m m m such that the average of the squared time derivative of two successive time points of each is minimized. Intuitively, we want to maximize the slowness of the features: yᵢ where the dot indicates the time derivatives, in the discrete case: The objective function (1) measures the slowness of the feature. The zero-mean constraint (2) makes the second moment and variance of the features equivalent and simplifies the notation. The unit variance constraint (3) discards constant solutions. The final constraint (4) decorrelates our features and induces an ordering on their slowness. This means that we first find the slowest feature, then we find the next slowest feature that is orthogonal to the one before it and so on. Decorrelating the features ensures that we capture the most information. In the following I glance over important details and skip steps, but I want to include it for completeness. I suggest looking at the links below as well for more thorough explanations. Let’s consider only linear features: The time series X can be “raw data” or its non-linear expansion, see example above. Remember that even though those are linear features of the expanded data, they can still be non-linear features of the original data. Assuming zero-mean , the linear features are found by solving the = . We determine eigenvalue-eigenvector tuples ( , ) such that = where we have X generalized eigenvalue problem AW BWΛ m λᵢ Wᵢ A Wᵢ λᵢ B Wᵢ, The scalars signify the slowness of the features, i.e. the smaller the , the more slowly varying the corresponding . If you are familiar with the generalized eigenvalue problem, note that the eigenvalues here are increasing — not decreasing. Lastly, the eigenvectors are the transformation vectors that define our learned features. λᵢ λᵢ yᵢ Wᵢ 3. Further reading The original paper: https://www.ini.rub.de/PEOPLE/wiskott/Reprints/WiskottSejnowski-2002-NeurComp-LearningInvariances.pdf Application of SFA to classification: http://cogprints.org/4104/1/Berkes2005a-preprint.pdf Example above is adapted from: http://mdp-toolkit.sourceforge.net/examples/logmap/logmap.html