
























































Jan 01, 1970
4,377 okumalar
alpaca-lora: Evde Pişirilmiş Büyük Dil Modeli ile Denemeler
Çok uzun; Okumak
Büyük dil modelleri (LLM'ler), LangChain ve Semantic Kernel gibi araçlarla kullanıcı etkileşimlerini geliştirerek yazılım geliştirmede devrim yaratıyor. İçerik oluşturmanın çeşitli aşamalarında yardımcı olabilirler ve karmaşık süreçleri kolaylaştırabilirler. Ancak LLM sağlayıcılarına bağımlılık, içerik sansürü ve özelleştirme seçeneklerine ilişkin endişeler, açık kaynak alternatifleri arayışına yol açmıştır. Makale, kendi LLM'niz olan alpaca-lora'yı eğitmek için bir ince ayar yöntemini araştırıyor ve özellikle V100 GPU'lar gibi donanımlarda başarılı ince ayarlar elde etmek için süreç, zorluklar ve potansiyel çözümler hakkında bilgiler sunuyor. Amaç, ani tekrarlardan kaçınırken tutarlı ve bağlamsal olarak uygun yanıtlar üreten Yüksek Lisans ÖM'leri oluşturmaktır.
Büyük dil modelleri (LLM), ChatGPT'nin piyasaya sürülmesinden bu yana yazılım geliştirmede moda bir kelime haline geldi. İnsanlarla doğal konuşmalar yapabilme yeteneği buzdağının sadece görünen kısmıdır. LangChain veya Semantic Kernel gibi araçlarla geliştirilen LLM'ler, kullanıcıların yazılımla etkileşimini tamamen değiştirme potansiyeline sahiptir. Başka bir deyişle Yüksek Lisans, işlevler ve veri kaynakları arasında sinerji yaratabilir ve daha verimli ve sezgisel bir kullanıcı deneyimi sağlayabilir.
Örneğin birçok kişi bir sonraki viral videoları için halihazırda yapay zeka tabanlı içerik oluşturma araçlarını kullanıyor. Tipik bir video üretim hattı, yalnızca birkaçını saymak gerekirse, komut dosyası oluşturma, lojistik, storyboard oluşturma, düzenleme ve pazarlamayı içerir. Süreci kolaylaştırmak için bir Yüksek Lisans, içerik oluşturuculara senaryo yazarken araştırma yapma, çekim için malzeme satın alma, senaryoya dayalı hikaye taslakları oluşturma (görüntü oluşturmak için istikrarlı bir yayılmaya ihtiyaç duyabilir), düzenleme sürecini kolaylaştırma ve göz alıcı başlık yazma konusunda yardımcı olabilir. /Sosyal medyada görüntülemeleri çekmek için video açıklamaları. Yüksek Lisans'lar tüm bunları düzenleyen temeldir, ancak Yüksek Lisans'ı bir yazılım ürününe dahil ederken çeşitli endişeler olabilir:
OpenAI'nin API'sini kullanırsam bu hizmete çok bağımlı hale gelir miyim? Peki ya fiyatı artırırlarsa? Peki ya hizmet kullanılabilirliğini değiştirirlerse?
OpenAI'nin içeriği sansürlemesi veya belirli kullanıcı girdileri hakkında yapıcı olmayan geri bildirimler sağlaması hoşuma gitmiyor. (Ya da tam tersi: OpenAI sansürünün benim kullanım durumumda hassas olan bazı şeyleri göz ardı etmesinden hoşlanmıyorum.)
Müşterilerim özel bulutu veya şirket içi dağıtımı tercih ediyorsa hangi ChatGPT alternatiflerine sahibim?
Sadece kontrolün bende olmasını istiyorum. LLM'yi özelleştirmem gerekiyor ve ucuz olmasını istiyorum.
İşte bu endişelerden dolayı OpenAI'nin GPT modellerinin açık kaynaklı bir eşdeğerinin olup olamayacağını merak ediyorum. Şans eseri, harika açık kaynak toplulukları şimdiden çok umut verici bazı çözümleri paylaşıyor. Kendi LLM'nizi eğitmek için parametre açısından verimli bir ince ayar yöntemi olan alpaca-lora'yı denemeye karar verdim. Bu blog yazısında süreç, karşılaştığım sorunlar, bunları nasıl çözdüğüm ve bundan sonra neler olabileceği anlatılıyor. Bu tekniği kendi LLM'nizi eğitmek için de kullanmak istiyorsanız, umarım bilgiler yardımcı olabilir.
Hadi başlayalım!
İçeriğe Genel Bakış
- LLaMA, alpaka ve LoRA nedir?
- İnce Ayar Deneyi
- Kaynak kodunu hızla tarayın
- İlk deneme
- İlk gözlem
- İkinci deneme ve (biraz) başarı
- 7B'nin ötesine geçiyoruz
- Özet
LLaMA, alpaka ve LoRA nedir?
LLaMA, Meta AI'nın temel dil modellerinden oluşan bir koleksiyondur. Bu otoregresif modeller 7B'den 65B'ye kadar değişen parametre sayılarına sahiptir ve yalnızca araştırma amacıyla kullanılabilirler. Meta yakın zamanda ticari olarak bazı sınırlamalarla kullanılabilecek LLaMA 2'yi piyasaya sürdü. LLaMA model ailesini özel kılan şey, eğitim yapısı ve performansıdır. Meta, LLaMA'nın halka açık veri kümeleri üzerinde eğitildiğini belirtiyor. 13B modeli, çoğu kıyaslamada GPT-3 (175B modeli) ile karşılaştırılabilir performansa ulaşıyor.
alpaca , Stanford'un LLaMA'yı temel alan talimatları takip eden bir Yüksek Lisans eğitimi oluşturma girişimidir. Bu şekilde çalışır:
Bir dil modelinden talimat-girdi-yanıt üçlülerini oluşturmasını isteyin.
LLaMA'da ince ayar yapmak için oluşturulan verileri kullanın.
İnce ayardan sonra LLaMA kullanıcının talimatlarını takip edebilir ve buna göre yanıt verebilir.
Vanilya LLaMA'nın yanıtı ile ince ayarlı LLaMA yanıtı arasında bir karşılaştırma:
{ "instruction": "Answer user's question.", "input": "Can you put a medium voltage circuit breaker in a low voltage switchgear? Why? Explain in detail.", "vanilla LLaMA": { "answer": "Yes, you can put a medium voltage circuit breaker in a low voltage switchgear. The medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put....(repetition continues)" }, "fine-tuned LLaMA": { "answer": "No, it is not possible to put a medium voltage circuit breaker in a low voltage switchgear. This is because low voltage switchgear is designed to handle voltages up to 1 kV, while medium voltage switchgear is designed to handle voltages from 1 kV to 38 kV. The circuit breakers, contacts, and other components in low voltage switchgear are not suitable for the higher voltages and currents of medium voltage switchgear. Using a medium voltage circuit breaker in a low voltage switchgear could result in damage to the components and could pose a safety hazard." } }
Gördüğünüz gibi ince ayar LLM davranışını oldukça büyük ölçüde değiştiriyor. Vanilya modeli bir tekrarlama döngüsüne sıkışmış durumda. İnce ayarlı model %100 doğru yanıt vermese de, en azından yanıtı net bir "Hayır"dır. İnce ayar, kullanılabilir LLM üretmek için gerekli bir adımdır. Çoğu durumda, açık kaynaklı, ince ayarlı bir LLM'nin dağıtılması yeterlidir. Ancak bazı özel iş kullanım durumlarında, modellere etki alanına özgü veri kümelerinde ince ayar yapılması tercih edilebilir.
Alpaka'nın en büyük dezavantajı kaynak gereksinimidir. GitHub sayfasında şunu belirtiyor:
Safça, bir 7B modeline ince ayar yapmak yaklaşık 7 x 4 x 4 = 112 GB VRAM gerektirir.
Bu, A100 80 GB GPU'nun kaldırabileceğinden daha fazla VRAM'dir. LoRA kullanarak VRAM gereksinimini aşabiliriz.
LoRA şu şekilde çalışır:
- Bir modelde, bir transformatör modelindeki sorgu projeksiyon ağırlığı $W_q$ gibi bazı ağırlıkları seçin. Seçilen ağırlıklara (evet, aritmetik toplama) adaptör ağırlıkları ekleyin.
- Orijinal modeli dondurun, yalnızca eklenen ağırlığı eğitin.
Eklenen ağırlığın bazı özel özellikleri vardır. Bu makaleden ilham alan Edward Hu ve ark. orijinal model ağırlığı $W_o\in R^{d \times k}$ için, aşağı akış görevleri için ince ayarlanmış bir ağırlık $W_o'=W_o+BA$ üretebileceğinizi gösterdi; burada $B\in R^{d \times r}$ , $A \in R^{r \times k}$ ve $r\ll min(d, k)$ bağdaştırıcı ağırlığının "içsel sırasıdır". Bağdaştırıcı ağırlığı için uygun bir $r$ ayarlamak önemlidir, çünkü daha küçük bir $r$ model performansını düşürür ve daha büyük bir $r$, orantısal performans artışı olmaksızın bağdaştırıcı ağırlık boyutunu artırır.
Bu teknik, bir matrisi birkaç küçük matrise ayrıştırarak ve yalnızca en büyük birkaç tekil değeri koruyarak yaklaşık olarak tahmin eden kesik SVD'ye benzer. $W_o\in R^{100 \times 100}$ varsayıldığında, tam bir ince ayar 10.000 parametreyi değiştirecektir. LoRA'nın $r=8$ ile ince ayarı, ince ayarı yapılmış ağırlığı her biri $B\in R^{100 \times 8}$ ve $A\in R^{8 \times 100}$ olmak üzere 2 parçaya ayırır. bölüm 800 parametre içermektedir (toplamda 1600 parametre). Eğitilebilir parametre sayısı 6,25 kat azaltılmıştır.
Modeli LoRA ile dönüştürdükten sonra, yalnızca ~%1 oranında eğitilebilir ağırlığa sahip olan ancak belirli alanlarda performansı büyük ölçüde iyileştirilmiş bir model elde ettik. Bu, 7B veya 13B modellerini RTX 4090 veya V100 gibi daha erişilebilir donanımlar üzerinde eğitmemize olanak tanır.
İnce Ayar Deneyi
Deneyi Huawei Cloud üzerinde GPU hızlandırmalı VM örneği ( p2s.2xlarge , 8vCPU, 64GB RAM, 1x V100 32GB VRAM.) ile çalıştırdım. V100'ün bfloat16 veri türünü desteklemediği, tensör çekirdeğinin ise int8'i desteklemediği biliniyor. hızlanma. Bu 2 sınır, karma duyarlıklı eğitimi yavaşlatabilir ve karma duyarlıklı eğitim sırasında sayısal taşmaya neden olabilir. Bunu daha sonraki tartışmalar için aklımızda tutacağız.
Kaynak kodunu hızla tarayın
finetune.py ve generate.py projenin temelidir. İlk komut dosyası, LLaMA modellerine ince ayar yapar ve ikinci komut dosyası, kullanıcılarla sohbet etmek için ince ayarlı modeli kullanır. Öncelikle finetune.py ana akışına bir göz atalım:
- önceden eğitilmiş büyük bir temel modelinin yüklenmesi
model = LlamaForCausalLM.from_pretrained( base_model, # name of a huggingface compatible LLaMA model load_in_8bit=True, torch_dtype=torch.float16, device_map=device_map, )
- modelin tokenizerini yükle
tokenizer = LlamaTokenizer.from_pretrained(base_model) tokenizer.pad_token_id = ( 0 # unk. we want this to be different from the eos token ) tokenizer.padding_side = "left" # Allow batched inference
eğitim şablonunu temel alarak,
tokenizevegenerate_and_tokenize_promptüzere iki işlevle model girişleri hazırlayın.
huggingface'in PEFT'sini kullanarak LoRA'ya uyarlanmış bir model oluşturun
config = LoraConfig( r=lora_r, # the lora rank lora_alpha=lora_alpha, # a weight scaling factor, think of it like learning rate target_modules=lora_target_modules, # transformer modules to apply LoRA to lora_dropout=lora_dropout, bias="none", task_type="CAUSAL_LM", ) model = get_peft_model(model, config)
- bir eğitmen örneği oluşturun ve eğitime başlayın
trainer = transformers.Trainer( model=model, train_dataset=train_data, eval_dataset=val_data, args=transformers.TrainingArguments( ...
Bu oldukça basit.
Sonunda, komut dosyası kontrol noktalarını, bağdaştırıcı ağırlıklarını ve bağdaştırıcı yapılandırmasını içeren bir model klasörü oluşturur.
Şimdi, generate.py ana akışına bakalım :
- yük modeli ve adaptör ağırlıkları
model = LlamaForCausalLM.from_pretrained( base_model, device_map={"": device}, torch_dtype=torch.float16, ) model = PeftModel.from_pretrained( model, lora_weights, device_map={"": device}, torch_dtype=torch.float16, )
- nesil yapılandırmasını belirtin
generation_config = GenerationConfig( temperature=temperature, top_p=top_p, top_k=top_k, num_beams=num_beams, **kwargs, ) generate_params = { "input_ids": input_ids, "generation_config": generation_config, "return_dict_in_generate": True, "output_scores": True, "max_new_tokens": max_new_tokens, }
- akışlı ve akışsız oluşturma modu için işlevleri tanımlayın:
if stream_output: # streaming ... # Without streaming with torch.no_grad(): generation_output = model.generate( input_ids=input_ids, generation_config=generation_config, return_dict_in_generate=True, output_scores=True, max_new_tokens=max_new_tokens, ) s = generation_output.sequences[0] output = tokenizer.decode(s) yield prompter.get_response(output)
- Modeli test etmek için bir Gradio sunucusu başlatın:
gr.Interface( ...
İlk deneme
Projenin README.md dosyası, aşağıdaki ince ayar ayarlarının Stanford alpaka ile karşılaştırılabilir performansa sahip bir LLaMA 7B ürettiğini belirtti. Sarılma yüzünde "resmi" bir alpaka-lora ağırlığı paylaşıldı.
python finetune.py \ --base_model='decapoda-research/llama-7b-hf' \ --num_epochs=10 \ --cutoff_len=512 \ --group_by_length \ --output_dir='./lora-alpaca' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --lora_r=16 \ --micro_batch_size=8
Ancak tecrübelerime göre kullanılabilir bir model ortaya çıkmadı. Bunu bir V100'de çalıştırmak, aşağıdaki gösteriyi durduran sorunlarla karşılaşacaktır:
- modelin
load_in_8bitile yüklenmesi veri türü hatasına neden olur. - bağlama komut dosyası PEFT'nin geçersiz bir bağdaştırıcı oluşturmasına neden olur. Geçersiz bağdaştırıcı orijinal LLaMA modelinde hiçbir değişiklik yapmaz ve yalnızca anlamsız sözler üretir.
-
decapoda-research/llama-7b-hfmodelinde görünüşe göre yanlış tokenizer kullanılmış. Pad jetonu, bos jetonu ve eos jetonu, LLaMA'nın resmi tokenizerinden farklıdır. - daha önce de belirtildiği gibi V100, int8/fp16 karma eğitimi için uygun desteğe sahip değildir. Bu,
training loss = 0.0veeval loss = NaNgibi beklenmeyen davranışlara neden olur.
Araştırma yapıp VM'de sayısız saat harcadıktan sonra, eğitimin tek bir V100'de çalışmasını sağlayacak gerekli değişiklikleri buldum.
... # do not use decapoda-research/llama-7b-hf as base_model. use a huggingface LLaMA model that was properly converted and has a correct tokenizer, eg, yahma/llama-7b-hf or huggyllama/llama-7b. # decapoda-research/llama-7b-hf is likely to cause overflow/underflow on V100. train loss goes to 0 and eval loss becomes NaN. using yahma/llama-7b-hf or huggyllama/llama-7b somehow mitigates this issue model = LlamaForCausalLM.from_pretrained( base_model, load_in_8bit=True, # only work for 7B LLaMA. On a V100, set True to save some VRAM at the cost of slower training; set False to speed up training at the cost of more VRAM / smaller micro batch size torch_dtype=torch.float16, device_map=device_map, ) ... # comment out the following line if load_in_8bit=False model = prepare_model_for_int8_training(model) ... # set legacy=False to avoid unexpected tokenizer behavior. make sure no tokenizer warning was raised during tokenizer instantiation tokenizer = LlamaTokenizer.from_pretrained(base_model, legacy=False) ... # the following binding script results in invalid adapter. simply comment them out old_state_dict = model.state_dict model.state_dict = ( lambda self, *_, **__: get_peft_model_state_dict( self, old_state_dict() ) ).__get__(model, type(model)) ... # if load_in_8bit=True, need to cast data type during training with torch.autocast('cuda'): trainer.train(resume_from_checkpoint=resume_from_checkpoint)
Bu değişiklikleri yaptıktan sonra bu eğitim argümanları kullanılabilir bir model üretir.
{ "args": [ "--base_model", "yahma/llama-7b-hf", "--num_epochs=10", "--data_path", "yahma/alpaca-cleaned", "--output_dir", "./your output dir", "--cutoff_len=512", "--lora_target_modules=[q_proj,k_proj,v_proj,o_proj]", "--lora_r=16", "--micro_batch_size=2", "--batch_size=16", "--wandb_project", "your wandb project name" ], }
Eğitim betiğinin yalnızca "en iyi" modeli (en düşük değerlendirme kaybına sahip kontrol noktası) değil aynı zamanda birkaç kontrol noktasını da kaydettiğini unutmayın. Daha fazla analiz için eğitim/değerlendirme kayıplarını kaydetmek için wandb'yi kullandım.
İlk gözlem
İnce ayarlı modele rastgele sorular soruyorum. Bazı makul tepkiler üretir.
İşte bir örnek:
Talimat: Kullanıcının sorusunu dikkatlice yanıtlayın.
Giriş: Bir şalt devre kesici kamyonunu rafa kaldırdığınızda ne olur?
Yanıt: Bir şalt cihazı devre kesici arabası "çıkarıldığında", bu, kamyondaki tüm devre kesicilerin açıldığı ve kamyonun enerjisiz durumda olduğu anlamına gelir. Bu genellikle kamyona servis yapılırken, tamir edilirken veya incelenirken yapılır. Devre kesiciler söküldükten sonra forklift üzerinde çalışmak güvenlidir ve gerekli bakım veya onarımlar tamamlandıktan sonra yeniden enerji verilebilir.
Bu örnek, LLM'nin dahili bilgisini sorgulamaktadır. Model şalterler hakkında çok şey biliyor gibi görünüyordu. Ancak akıl yürütme yeteneğini ampirik olarak test etmeye çalıştığımda çok tuhaf bir sonuç verdi:
Talimat:
Bir projeye ilişkin aşağıda verilen bilgilere göre soruları cevaplayınız. Chinese-Llama-2 projesi, büyük dil modeli Llama-2'nin Çince dilinde anlaşılmasını, üretilmesini ve çeviri yeteneklerini geliştirmeyi amaçlamaktadır. LoRA ince ayarı, tam parametreli talimat ince ayarı ve ikincil ön eğitim gibi yöntemlerin uygulanmasıyla sizi ilgili veri kümelerini, eğitim kılavuzlarını ve model parametrelerini indirmeye ve kullanmaya davet ediyoruz.
Girdi: Bu projede hangi yöntemler kullanılıyor?
Yanıt: Chinese-Llama-2 projesi, büyük dil modeli Llama-2'nin Çince dilinde anlaşılmasını, üretilmesini ve çeviri yeteneklerini geliştirmeyi amaçlamaktadır. LoRA ince ayarı, tam parametreli talimat ince ayarı ve ikincil ön eğitim gibi yöntemlerin uygulanmasıyla sizi ilgili veri kümelerini, eğitim kılavuzlarını ve model parametrelerini indirip kullanmaya davet ediyoruz.</s>
Gördüğünüz gibi model, istemi tekrarlamayı seviyor. Ben buna istem tekrarlayıcı modeli diyorum ve diğer geliştiriciler de bu davranışı repo sorunlarında rapor ediyorlardı. Soruları yanıtlama yeteneği, daha dikkatli tasarlanmış yönlendirmelerle daha da iyi hale gelir. Farklı modellerde hızlı etkililiği garanti edemediğimizden, bu davranış bir üretim sisteminde istediğimiz şey değildir. Modellerin istemlere karşı daha az duyarlı olması gerekir. Bir şekilde bu Yüksek Lisans'ın performansını artırmak istiyoruz.
Bir sonraki oturumda bu soruna neyin sebep olduğunu ve ince ayar sonuçlarının nasıl iyileştirilebileceğini tartışacağım.
İkinci deneme ve (biraz) başarı
İnce ayar sonucunu iyileştirmek için denediğim 3 şey:
İstemlerdeki kaybı maskeleyin (istem tekrarını önlemeye yardımcı olur)
group-by-lengthseçeneğini kapatın (performansın artmasına yardımcı olur, kayıp eğrisinin daha düzgün görünmesini sağlar)Değerlendirme kayıp eğrisine güvenmeyin. Değerlendirme kaybı "en iyi" kontrol noktasından daha yüksek olsa bile, eğitim kaybı daha düşük olan bir kontrol noktası kullanın. (Değerlendirme kaybı buradaki en iyi matris olmadığından performansı artırmaya yardımcı olur)
Bu 3 noktayı tek tek açıklayalım.
İstemlerde kaybı maskeleme
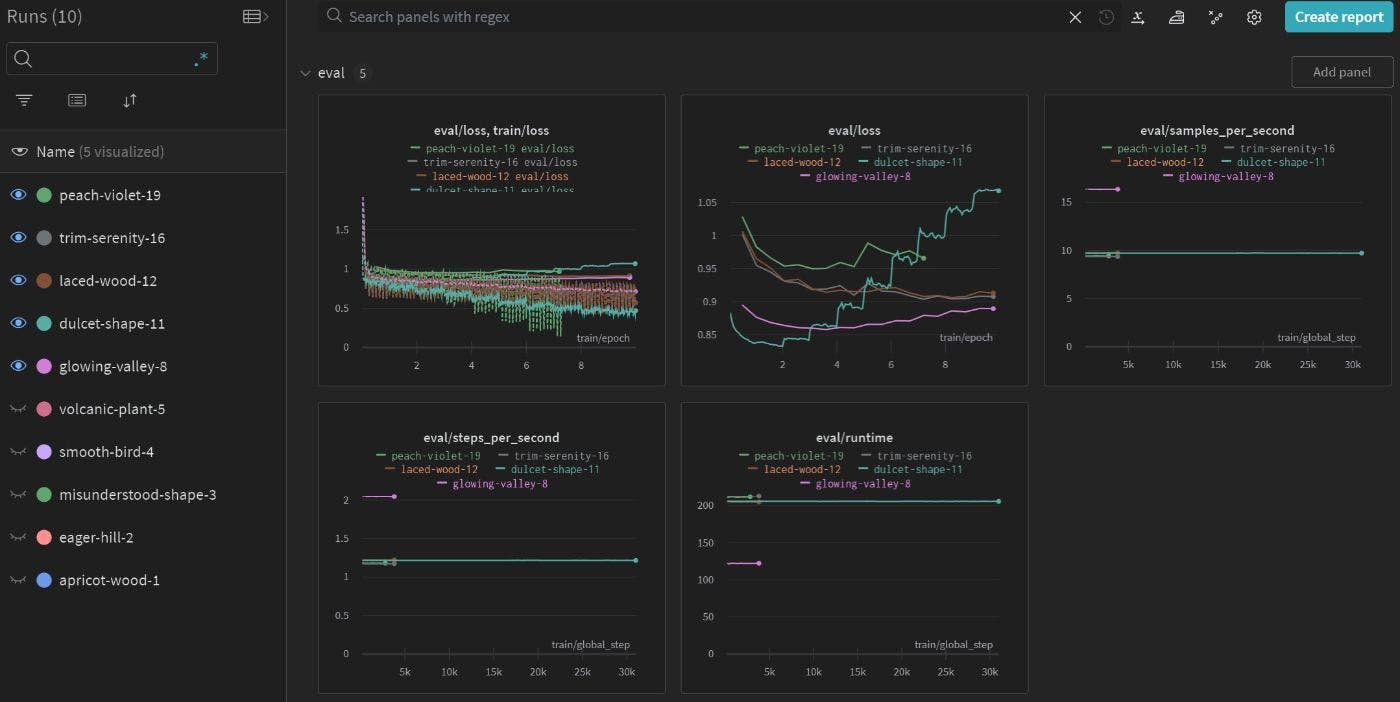
Bu gönderiyi ve resmi lora ağırlıkları taahhüt mesajını bulana kadar hızlı tekrarın nedenlerini arıyordum. Kayıp hesaplamasında istemlerin hariç tutulması gerektiğini önerdiler. Temel olarak, modeli bilgi istemi belirteçleri çıkarmaya teşvik etmek istemezsiniz. Eğitim sırasında istemlerin maskelenmesi, modeli bilgi istemi belirteçlerini tekrarlamaya teşvik etmez. Aşağıdaki grafik bunu açıklamaktadır: 3 eğitim çalıştırması arasında stoic-star-6 , eğitim sırasındaki istemleri maskelemeyen tek çalışmadır. Bu nedenle başlangıçta eğitim kaybı daha yüksektir. Eğer a) kayıp hesaplanırken istemler maskelenmezse ve b) eğitim yetersizse, modelin talimatları takip etmek yerine istemleri tekrarlama olasılığının daha yüksek olacağından şüpheleniyorum.
Kaynak kodunda kayıp maskeleme, bilgi istemi belirteçlerinin -100'e ayarlanmasıyla yapılır:
Endeksleri
-100olarak ayarlanmış belirteçler göz ardı edilir (maskelenir), kayıp yalnızca[0, ..., config.vocab_size]içindeki etiketlere sahip belirteçler için hesaplanır.
group-by-length seçeneğini kapat
group-by-length seçeneği huggingface'in Trainer benzer uzunluktaki girdileri gruplar halinde gruplamasına olanak tanır. Bu, giriş dizilerini doldururken VRAM kullanımından tasarruf etmenize yardımcı olur. Ancak bu, tek bir parti içindeki numune farklılığını büyük ölçüde azaltacaktır. Eğitim sürecinde genellikle modeli çeşitli eğitim örneklerine maruz bırakmayı tercih ediyoruz. group-by-length False olarak ayarlanması örnek varyasyonunu azaltır. Aynı zamanda eğitim sırasında kayıp dalgalanmasına da neden olur (Örneğin, iki ardışık partinin dolgu uzunlukları 10 ve 50'dir. Daha kısa olan partinin kaybı daha düşük, daha uzun olan partinin kaybı ise daha yüksektir. Bu, şekilde gösterildiği gibi bir salınımlı kayıp eğrisi ile sonuçlanır. altında).
Öte yandan, group-by-length toplu örnek varyasyonunu azalttığından, model performansının da bundan olumsuz etkilenebileceğinden şüpheleniyorum. Aşağıdaki şekil group-by-length göre gruplu veya grupsuz antrenman kaybını karşılaştırmaktadır. group-by-length etkinleştirilmiş peach-violet-19 çalıştırması için ortalama kaybın daha yüksek olduğu açıktır.
Değerlendirme kayıp eğrisine güvenmeyin
Tüm koşularımda eğitim kaybı ve değerlendirme kaybının birbirinden farklı olduğunu gözlemledim.
İşte bir örnek:
Bu örnekte optimum kontrol noktası epoch=2 civarında gerçekleşir. Orijinal repo tarafından önerilen optimum kontrol noktasını yüklerseniz, önceki oturumda belirtildiği gibi büyük olasılıkla bir istem tekrarlayıcı modeli elde edersiniz.
Eğitimin sonuna doğru bir model kontrol noktası yükleyerek daha performanslı bir model elde ettim. Daha önce de aynı soruyu sordum ve model doğru cevabı verdi:
Talimat:
Bir projeye ilişkin aşağıda verilen bilgilere göre soruları cevaplayınız. Chinese-Llama-2 projesi, büyük dil modeli Llama-2'nin Çince dilinde anlaşılmasını, üretilmesini ve çeviri yeteneklerini geliştirmeyi amaçlamaktadır. LoRA ince ayarı, tam parametreli talimat ince ayarı ve ikincil ön eğitim gibi yöntemlerin uygulanmasıyla sizi ilgili veri kümelerini, eğitim kılavuzlarını ve model parametrelerini indirmeye ve kullanmaya davet ediyoruz.
Girdi: Bu projede hangi yöntemler kullanılıyor?
Yanıt: Chinese-Llama-2 projesi, LoRA ince ayarı, tam parametreli talimat ince ayarı ve ikincil ön eğitim gibi yöntemleri kullanıyor.</s>
Ancak değerlendirme kaybına bakılırsa bu modelin daha kötü performans göstermesi gerekir. İkilemin nedeni nedir?
Değerlendirme kaybının büyük dil modeli performansını ölçmek için iyi bir matris olmadığını düşünüyorum. LLaMA, eğitim ve değerlendirme kaybı için CrossEntropyLoss kullanır:
# modelling_llama.py from transformers library ... # forward function under LlamaForCausalLM class if labels is not None: # Shift so that tokens < n predict n shift_logits = logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() # Flatten the tokens loss_fct = CrossEntropyLoss() loss = loss_fct(shift_logits.view(-1, self.config.vocab_size), shift_labels.view(-1))
Bir değerlendirme seti üzerinde test yaparken, bir model aynı cevabı farklı ifadelerle üretebilir:
{ "evaluation prompt": "What is 1 + 3?" "evaluation answer": "4." "prediction answer": "The answer is 4." }
Her iki cevap da doğrudur ancak tahmin cevabı değerlendirme cevabıyla tam olarak eşleşmezse değerlendirme kaybı yüksek olacaktır. Bu durumda modelin performansını ölçmek için daha iyi bir değerlendirme matrisine ihtiyacımız var. Doğru değerlendirmeyi daha sonra yapacağız. Şimdilik en iyi modelin en düşük eğitim kaybına sahip model olduğunu varsayalım.
7B'nin ötesine geçiyoruz
V100'de bir 13B modeline ince ayar yapmayı denedim. V100, 7B modelinde hem int8 hem de fp16 eğitimini işleyebilirken, 13B modelinde int8 eğitimini işleyemez. load_int_8bit = True ise, 13B modeli training_loss = 0.0 üretecektir. Bunun neden olduğunu anlamak için bazı hata ayıklama araçlarını kullanabiliriz ( spoiler uyarısı: taşma/eksiklik nedeniyle oluşur).
Eğitim sırasında parametreleri incelemek için huggingface'in DebugUnderflowOverflow aracını kullandım. İlk ileri geçişte inf/nan değerlerini tespit etti:
Daha spesifik olarak DebugUnderflowOverflow , aşağıdaki şekilde gösterildiği gibi LlamaDecoderLayer 2. girişinde negatif sonsuzluk değerleri yakaladı. 2. girdi attention_mask . Biraz daha derine indim ve attention_mask dolgu elemanları için çok büyük negatif değerlere sahip olması gerektiğini öğrendim. Negatif sonsuzluk değerleri tesadüfen her dizinin başında yer alır. Bu gözlem beni bu katmanda negatif sonsuzluk değerlerinin oluşması gerektiğine inandırıyor. Daha ileri araştırmalar ayrıca sonsuzluk değerlerinin sonraki birkaç katmanda daha fazla sonsuzluk değerlerine neden olmadığını gösterdi. Bu nedenle, LlamaDecoderLayer taşma büyük olasılıkla anormal eğitim kaybının temel nedeni değildir.
Daha sonra her katmanın çıktılarını inceledim. Aşağıdaki şekilde görüldüğü gibi son katmanların çıktılarının taştığı çok açıktı. Bunun int-8 ağırlıklarının sınırlı hassasiyetinden (veya sınırlı float16 aralığından kaynaklandığına inanıyorum. Büyük olasılıkla bfloat16 bu sorunu önleyebilir).
Taşma problemini çözmek için eğitim sırasında float16 kullandım. Bazı hileler kullanılmadığı sürece V100, 13B modelini eğitmek için yeterli VRAM'e sahip değildir. Hugging Face DeepSpeed , eğitim VRAM kullanımını azaltmak için CPU yükünü boşaltma gibi çeşitli yöntemler sağlar. Ancak en basit yöntem, eğitim başlamadan önce model.gradient_checkpointing_enable() çağırarak degrade denetim noktası oluşturmayı etkinleştirmektir.
Kademeli kontrol noktası oluşturma, eğitim hızını daha az VRAM kullanımıyla değiştirir. Tipik olarak ileri geçiş sırasında aktivasyonlar hesaplandı ve geri geçiş sırasında kullanılmak üzere bellekte saklandı. Bu, ek bellek kaplar. Ancak degrade kontrol noktası belirlemede, ileri geçiş sırasındaki aktivasyonları depolamak yerine, bunlar geri geçiş sırasında yeniden hesaplanır ve böylece VRAM'den tasarruf sağlanır. İşte bu teknikle ilgili güzel bir makale .
Llama 13B'yi float16 ve degrade kontrol noktası etkinken eğitmeyi başardım:
python finetune.py \ --base_model=yahma/llama-13b-hf \ --num_epochs=10 \ --output_dir 'your/output/dir' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --cutoff_len=1024 \ --lora_r=16 \ --micro_batch_size=4 \ --batch_size=128 \ --wandb_project 'alpaca_lora_13b' \ --train_on_inputs=False
13B modeli, ad varlığı tanıma gibi bazı gelişmiş görevleri yerine getirebilir. Test için örnek bir bilgi istemi kullanıyorum ve bu, 13B modelinin doğru yanıtıdır:
Her şey yolunda! Bu heyecan verici bir başlangıç. Model, LangChain ile karmaşık uygulamalar oluşturmamıza olanak tanıyor.
Bu noktada otomatik model değerlendirmeye yönelik araçlar hâlâ eksiktir. Modellerimizi birçok test senaryosunda değerlendirmek, hatta kendi test senaryolarımızı oluşturmak için Dil Modeli Değerlendirme Sistemini kullanabiliriz. Hugging Face'in Açık Yüksek Lisans Liderlik Tablosu için kullandığı aracın aynısıdır. Değerlendirme LLM gelişiminin çok önemli bir yönü olsa da, bu makale yalnızca eğitim sürecine odaklanmaktadır. Gelecekteki bir makalede değerlendirmeyi tartışabilirim.
Özet
Bu makalede, büyük temel modelleri (LFM'ler) kavramını ve LFM'lerin istenildiği gibi davranmasını sağlayan çeşitli ince ayar yöntemlerini tanıttık. Daha sonra LFM'de ince ayar yapmak için parametre açısından verimli bir yöntem olan LoRA'ya odaklandık ve ince ayar kodunun yanı sıra performans iyileştirme tekniklerini açıkladık. Sonunda bir adım daha ileri gittik ve bir Llama 13B modelini V100 GPU üzerinde başarıyla eğittik. 13B modeli eğitiminde bazı sorunlarla karşılaşılsa da bu sorunların donanım kısıtlamalarından kaynaklandığını gördük ve çözüm önerileri sunduk. Sonunda, çalışan, ince ayarlı bir Yüksek Lisans elde ettik, ancak Yüksek Lisans'ın performansını henüz niceliksel olarak değerlendirmedik.
Yazar hakkında
Selamlar! Adım Wei. Ben özel bir problem çözücüyüm, Kıdemli Yapay Zeka Uzmanıyım ve ABB'de analitik proje lideriyim ve makine öğrenimi Google Geliştirici Uzmanıyım . Minnesota Twin Cities Üniversitesi'nden Makine Mühendisliği alanında yüksek lisans derecesine ve Urbana-Champaign'deki Illinois Üniversitesi'nden Makine Mühendisliği alanında lisans derecesine sahibim.
Teknoloji yığınım Python / C# programlama, bilgisayarla görme, makine öğrenimi, algoritmalar ve mikro hizmetler üzerine yoğunlaşıyor ancak aynı zamanda oyun geliştirme (Unity), ön/arka uç geliştirme, teknik liderlik gibi geniş bir ilgi alanım da var. tek kartlı bilgisayarlar ve robotlarla uğraşmak.
Umarım bu makale insanlara bir şekilde yardımcı olabilir. Okuduğunuz için teşekkürler ve mutlu problem çözümleri!
L O A D I N G
. . . comments & more!
. . . comments & more!



