
































Jan 01, 1970
4,377 lectures
alpaca-lora : Expérimentation d'un grand modèle de langage fait maison
Trop long; Pour lire
Les grands modèles de langage (LLM) révolutionnent le développement de logiciels, améliorant les interactions des utilisateurs avec des outils tels que LangChain et Semantic Kernel. Ils peuvent aider à différentes étapes de création de contenu et rationaliser des processus complexes. Cependant, les préoccupations concernant la dépendance à l'égard des fournisseurs LLM, la censure du contenu et les options de personnalisation ont conduit à rechercher des alternatives open source. L'article explore une méthode de réglage fin pour former votre propre LLM, alpaca-lora, offrant un aperçu du processus, des défis et des solutions potentielles, en particulier pour réussir un réglage précis sur du matériel tel que les GPU V100. L'objectif est de créer des LLM qui produisent des réponses cohérentes et contextuellement pertinentes tout en évitant les répétitions rapides.
Les grands modèles de langage (LLM) sont devenus le mot à la mode dans le développement de logiciels depuis la sortie de ChatGPT. Sa capacité à avoir des conversations naturelles avec les humains n’est que la pointe de l’iceberg. Améliorés avec des outils comme LangChain ou Semantic Kernel, les LLM ont le potentiel de changer complètement la façon dont les utilisateurs interagissent avec les logiciels. En d’autres termes, les LLM peuvent créer des synergies entre les fonctionnalités et les sources de données et offrir une expérience utilisateur plus efficace et intuitive.
Par exemple, de nombreuses personnes utilisent déjà des outils de création de contenu basés sur l’IA pour leurs prochaines vidéos virales. Un pipeline de production vidéo typique comprend le script, la logistique, le storyboard, le montage et le marketing, pour n'en nommer que quelques-uns. Pour rationaliser le processus, un LLM pourrait aider les créateurs de contenu dans leurs recherches lors de l'écriture des scripts, acheter des accessoires pour le tournage, générer des storyboards basés sur le script (peut nécessiter une diffusion stable pour la génération d'images), faciliter le processus d'édition et rédiger un titre accrocheur. /Descriptions vidéo pour attirer des vues sur les réseaux sociaux. Les LLM sont au cœur de tout cela, mais plusieurs problèmes peuvent survenir lors de l'intégration du LLM dans un produit logiciel :
Si j'utilise l'API d'OpenAI, vais-je devenir trop dépendant de ce service ? Et s'ils augmentaient le prix ? Et s'ils modifient la disponibilité du service ?
Je n'aime pas la façon dont OpenAI censure le contenu ou fournit des commentaires non constructifs sur certaines entrées utilisateur. (Ou l'inverse : je n'aime pas la façon dont la censure d'OpenAI ignore certaines choses qui sont sensibles dans mon cas d'utilisation.)
Si mes clients préfèrent le cloud privé ou le déploiement sur site, quelles sont les alternatives ChatGPT dont je dispose ?
Je veux juste avoir le contrôle. J'ai besoin de personnaliser le LLM et je le veux à moindre coût.
C'est pour ces préoccupations que je me demande s'il pourrait exister un équivalent open source des modèles GPT d'OpenAI. Heureusement, les merveilleuses communautés open source partagent déjà des solutions très prometteuses. J'ai décidé d'essayer alpaca-lora , une méthode de réglage précis et efficace pour entraîner votre propre LLM. Cet article de blog traite du processus, des problèmes que j'ai rencontrés, de la façon dont je les ai résolus et de ce qui pourrait arriver ensuite. Si vous souhaitez également utiliser cette technique pour former votre propre LLM, j'espère que ces informations pourront vous aider.
Commençons!
Aperçu du contenu
- Qu'est-ce que LLaMA, alpaga et LoRA ?
- L'expérience de réglage fin
- Scanner rapidement le code source
- La première tentative
- Le premier constat
- La deuxième tentative et le (quelque) succès
- Aller au-delà du 7B
- Résumé
Qu'est-ce que LLaMA, alpaga et LoRA ?
LLaMA est une collection de modèles de langage de base de Meta AI. Ces modèles autorégressifs ont un nombre de paramètres allant de 7B à 65B et ne peuvent être utilisés qu'à des fins de recherche. Meta a récemment publié LLaMA 2 , qui peut être utilisé commercialement avec certaines limites. Ce qui rend la famille de modèles LLaMA spéciale, c'est son corpus de formation et ses performances. Meta déclare que LLaMA est formé sur des ensembles de données accessibles au public. Sa variante 13B atteint des performances comparables au GPT-3 (un modèle 175B) sur la plupart des benchmarks.
alpaga est la tentative de Stanford de construire un LLM suivant les instructions basé sur LLaMA. Cela fonctionne comme ceci :
Demandez à un modèle de langage de générer des triplets instruction-entrée-réponse.
Utilisez les données générées pour affiner LLaMA.
Après un réglage fin, LLaMA est capable de suivre les instructions de l'utilisateur et de répondre en conséquence.
Voici une comparaison entre la réponse de LLaMA vanille et la réponse affinée de LLaMA :
{ "instruction": "Answer user's question.", "input": "Can you put a medium voltage circuit breaker in a low voltage switchgear? Why? Explain in detail.", "vanilla LLaMA": { "answer": "Yes, you can put a medium voltage circuit breaker in a low voltage switchgear. The medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put....(repetition continues)" }, "fine-tuned LLaMA": { "answer": "No, it is not possible to put a medium voltage circuit breaker in a low voltage switchgear. This is because low voltage switchgear is designed to handle voltages up to 1 kV, while medium voltage switchgear is designed to handle voltages from 1 kV to 38 kV. The circuit breakers, contacts, and other components in low voltage switchgear are not suitable for the higher voltages and currents of medium voltage switchgear. Using a medium voltage circuit breaker in a low voltage switchgear could result in damage to the components and could pose a safety hazard." } }
Comme vous pouvez le constater, le réglage fin modifie considérablement le comportement du LLM. Le modèle vanille est coincé dans une boucle de répétition. Même si le modèle affiné n'a pas donné une réponse correcte à 100 %, sa réponse est au moins un « non » catégorique. Le réglage fin est une étape nécessaire pour produire un LLM utilisable. Dans de nombreux cas, le déploiement d’un LLM open source affiné est suffisant. Cependant, dans certains cas d'utilisation métier personnalisés, il peut être préférable d'affiner les modèles sur des ensembles de données spécifiques à un domaine.
Le plus gros inconvénient de l’alpaga est son besoin en ressources. Sa page GitHub indique que :
Naïvement, le réglage fin d'un modèle 7B nécessite environ 7 x 4 x 4 = 112 Go de VRAM.
C’est plus de VRAM qu’un GPU A100 de 80 Go ne peut gérer. Nous pouvons contourner l'exigence de VRAM en utilisant LoRA .
LoRA fonctionne comme ceci :
- Sélectionnez certains poids dans un modèle, tels que le poids de projection de requête $W_q$ dans un modèle de transformateur. Ajoutez (oui, addition arithmétique) des poids d'adaptateur aux poids sélectionnés.
- Gelez le modèle original, entraînez uniquement le poids ajouté.
Le poids ajouté a des propriétés particulières. Inspirés par cet article , Edward Hu et al. a montré que pour un poids de modèle original $W_o\in R^{d \times k}$, vous pouvez produire un poids affiné $W_o'=W_o+BA$ pour les tâches en aval, où $B\in R^{d \times r}$ , $A \in R^{r \times k}$ et $r\ll min(d, k)$ est le "rang intrinsèque" du poids de l'adaptateur. Il est important de définir un $r$ approprié pour le poids de l'adaptateur, car un $r$ plus petit diminue les performances du modèle, et un $r$ plus grand augmente la taille du poids de l'adaptateur sans gain de performances proportionnel.
Cette technique est similaire au SVD tronqué, qui se rapproche d'une matrice en la décomposant en plusieurs matrices plus petites et en ne conservant que quelques plus grandes valeurs singulières. En supposant $W_o\in R^{100 \times 100}$, un réglage fin complet modifierait 10 000 paramètres. Le réglage fin de LoRA avec $r=8$ décomposerait le poids affiné en 2 parties, $B\in R^{100 \times 8}$ et $A\in R^{8 \times 100}$, chacune La partie contient 800 paramètres (1 600 paramètres au total.) Le nombre de paramètres pouvant être entraînés est réduit de 6,25 fois.
Après avoir transformé le modèle avec LoRA, nous avons obtenu un modèle qui n'a qu'environ 1 % de poids entraînables, mais ses performances sont grandement améliorées dans certains domaines. Cela nous permettrait de former des modèles 7B ou 13B sur du matériel plus accessible comme le RTX 4090 ou le V100.
L'expérience de réglage fin
J'ai mené l'expérience sur Huawei Cloud avec une instance de VM accélérée par GPU ( p2s.2xlarge , 8vCPU, 64 Go de RAM, 1x V100 32 Go de VRAM.) On sait que le V100 ne prend pas en charge le type de données bfloat16 et que son noyau tenseur ne prend pas en charge int8. accélération. Ces 2 limites peuvent ralentir l'entraînement en précision mixte et provoquer un débordement numérique lors de l'entraînement en précision mixte. Nous garderons cela à l’esprit pour une discussion ultérieure.
Scanner rapidement le code source
finetune.py et generate.py sont au cœur du projet. Le premier script affine les modèles LLaMA et le second utilise le modèle affiné pour discuter avec les utilisateurs. Jetons d'abord un coup d'œil au flux principal de finetune.py :
- chargement d'un grand modèle de fondation pré-entraîné
model = LlamaForCausalLM.from_pretrained( base_model, # name of a huggingface compatible LLaMA model load_in_8bit=True, torch_dtype=torch.float16, device_map=device_map, )
- charger le tokenizer du modèle
tokenizer = LlamaTokenizer.from_pretrained(base_model) tokenizer.pad_token_id = ( 0 # unk. we want this to be different from the eos token ) tokenizer.padding_side = "left" # Allow batched inference
sur la base du modèle de formation, préparez les entrées du modèle avec deux fonctions,
tokenizeetgenerate_and_tokenize_prompt.
créer un modèle adapté à LoRA en utilisant le PEFT de Huggingface
config = LoraConfig( r=lora_r, # the lora rank lora_alpha=lora_alpha, # a weight scaling factor, think of it like learning rate target_modules=lora_target_modules, # transformer modules to apply LoRA to lora_dropout=lora_dropout, bias="none", task_type="CAUSAL_LM", ) model = get_peft_model(model, config)
- créer une instance de formateur et démarrer la formation
trainer = transformers.Trainer( model=model, train_dataset=train_data, eval_dataset=val_data, args=transformers.TrainingArguments( ...
C'est assez simple.
À la fin, le script produit un dossier modèle avec des points de contrôle, des poids d'adaptateur et une configuration d'adaptateur.
Examinons ensuite le flux principal de generate.py :
- modèle de charge et poids de l'adaptateur
model = LlamaForCausalLM.from_pretrained( base_model, device_map={"": device}, torch_dtype=torch.float16, ) model = PeftModel.from_pretrained( model, lora_weights, device_map={"": device}, torch_dtype=torch.float16, )
- spécifier la configuration de génération
generation_config = GenerationConfig( temperature=temperature, top_p=top_p, top_k=top_k, num_beams=num_beams, **kwargs, ) generate_params = { "input_ids": input_ids, "generation_config": generation_config, "return_dict_in_generate": True, "output_scores": True, "max_new_tokens": max_new_tokens, }
- définir des fonctions pour le mode de génération streaming et non streaming :
if stream_output: # streaming ... # Without streaming with torch.no_grad(): generation_output = model.generate( input_ids=input_ids, generation_config=generation_config, return_dict_in_generate=True, output_scores=True, max_new_tokens=max_new_tokens, ) s = generation_output.sequences[0] output = tokenizer.decode(s) yield prompter.get_response(output)
- Démarrez un serveur Gradio pour tester le modèle :
gr.Interface( ...
La première tentative
Le README.md du projet indique que les paramètres de réglage précis suivants produisent un LLaMA 7B avec des performances comparables à celles de l'alpaga de Stanford. Un poids "officiel" d'alpaga-lora a été partagé sur Huggingface.
python finetune.py \ --base_model='decapoda-research/llama-7b-hf' \ --num_epochs=10 \ --cutoff_len=512 \ --group_by_length \ --output_dir='./lora-alpaca' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --lora_r=16 \ --micro_batch_size=8
Cependant, d’après mon expérience, cela n’a pas donné lieu à un modèle utilisable. L’exécuter sur un V100 rencontrera les problèmes suivants :
- le chargement du modèle avec
load_in_8bitprovoque une erreur de type de données. - un script de liaison amènera PEFT à produire un adaptateur non valide. L'adaptateur non valide n'apporte aucune modification au modèle LLaMA d'origine et ne produit que du charabia.
- le modèle
decapoda-research/llama-7b-hfapparemment utilisé le mauvais tokenizer. Son token pad, son token bos et son token eos sont différents du tokenizer officiel de LLaMA. - comme mentionné précédemment, le V100 ne prend pas en charge la formation mixte int8/fp16. Cela provoque des comportements inattendus, tels que
training loss = 0.0eteval loss = NaN.
Après avoir fouillé et perdu de nombreuses heures de VM, j'ai trouvé les changements nécessaires pour que la formation fonctionne sur un seul V100.
... # do not use decapoda-research/llama-7b-hf as base_model. use a huggingface LLaMA model that was properly converted and has a correct tokenizer, eg, yahma/llama-7b-hf or huggyllama/llama-7b. # decapoda-research/llama-7b-hf is likely to cause overflow/underflow on V100. train loss goes to 0 and eval loss becomes NaN. using yahma/llama-7b-hf or huggyllama/llama-7b somehow mitigates this issue model = LlamaForCausalLM.from_pretrained( base_model, load_in_8bit=True, # only work for 7B LLaMA. On a V100, set True to save some VRAM at the cost of slower training; set False to speed up training at the cost of more VRAM / smaller micro batch size torch_dtype=torch.float16, device_map=device_map, ) ... # comment out the following line if load_in_8bit=False model = prepare_model_for_int8_training(model) ... # set legacy=False to avoid unexpected tokenizer behavior. make sure no tokenizer warning was raised during tokenizer instantiation tokenizer = LlamaTokenizer.from_pretrained(base_model, legacy=False) ... # the following binding script results in invalid adapter. simply comment them out old_state_dict = model.state_dict model.state_dict = ( lambda self, *_, **__: get_peft_model_state_dict( self, old_state_dict() ) ).__get__(model, type(model)) ... # if load_in_8bit=True, need to cast data type during training with torch.autocast('cuda'): trainer.train(resume_from_checkpoint=resume_from_checkpoint)
Après avoir apporté ces modifications, ces arguments de formation produisent un modèle utilisable.
{ "args": [ "--base_model", "yahma/llama-7b-hf", "--num_epochs=10", "--data_path", "yahma/alpaca-cleaned", "--output_dir", "./your output dir", "--cutoff_len=512", "--lora_target_modules=[q_proj,k_proj,v_proj,o_proj]", "--lora_r=16", "--micro_batch_size=2", "--batch_size=16", "--wandb_project", "your wandb project name" ], }
Notez que le script de formation enregistre non seulement le « meilleur » modèle (point de contrôle avec la perte d'évaluation la plus faible), mais également quelques points de contrôle. J'ai utilisé wandb pour enregistrer les pertes de formation/évaluation pour une analyse plus approfondie.
Le premier constat
Je lance quelques questions aléatoires sur le modèle affiné. Cela produit des réponses raisonnables.
Voici un exemple :
Instruction : Répondez attentivement à la question de l'utilisateur.
Entrée : Que se passe-t-il lorsque vous démontez un camion de disjoncteurs d'appareillage de commutation ?
Réponse : Lorsqu'un camion de disjoncteurs d'appareillage de commutation est « débroché », cela signifie que tous les disjoncteurs du camion ont été ouverts et que le camion est dans un état non alimenté. Cela se fait généralement lorsque le camion est entretenu, réparé ou inspecté. Une fois les disjoncteurs débrochés, le camion peut être utilisé en toute sécurité et peut être remis sous tension une fois l'entretien ou les réparations nécessaires effectués.
Cet exemple interroge les connaissances internes du LLM. Le modèle semblait en savoir beaucoup sur les appareillages. Cependant, lorsque j’ai essayé de tester empiriquement sa capacité de raisonnement, cela a produit un résultat très étrange :
Instruction:
Compte tenu des informations ci-dessous sur un projet, répondez aux questions. Le projet Chinese-Llama-2 vise à améliorer les capacités de compréhension, de génération et de traduction du grand modèle linguistique Llama-2 en langue chinoise. Avec l'application de méthodes telles que le réglage fin de LoRA, le réglage fin des instructions complètes et la pré-formation secondaire, nous vous invitons cordialement à télécharger et à utiliser les ensembles de données, les guides de formation et les paramètres de modèle associés.
Entrée : Quelles méthodes sont utilisées dans ce projet ?
Réponse : Le projet Chinese-Llama-2 vise à améliorer les capacités de compréhension, de génération et de traduction du grand modèle linguistique Llama-2 en langue chinoise. Avec l'application de méthodes telles que le réglage fin de LoRA, le réglage fin des instructions complètes et la pré-formation secondaire, nous vous invitons cordialement à télécharger et à utiliser les ensembles de données, les guides de formation et les paramètres de modèle associés.</s>
Comme vous pouvez le voir, le modèle aime répéter l'invite. J'appelle cela le modèle de répéteur d'invite , et d'autres développeurs ont également signalé ce comportement dans les problèmes de dépôt . Sa capacité à répondre aux questions ne fait que s’améliorer grâce à des invites plus soigneusement conçues. Ce comportement n’est pas ce que nous souhaitons dans un système de production, car nous ne pouvons pas garantir une efficacité rapide entre les différents modèles. Les modèles doivent être moins sensibles aux invites. Nous voulons en quelque sorte améliorer les performances de ce LLM.
Lors de la prochaine session, je discuterai de la cause de ce problème et de la manière d'améliorer les résultats du réglage fin.
La deuxième tentative et le (quelque) succès
Voici 3 choses que j'ai essayées pour améliorer le résultat du réglage :
Masquer la perte sur les invites (permet d'éviter la répétition des invites)
Désactivez l'option
group-by-length(contribue à améliorer les performances, rend la courbe de perte plus lisse)Ne faites pas confiance à la courbe de perte d'évaluation. Utilisez un point de contrôle qui présente une perte d'entraînement inférieure, même si sa perte d'évaluation peut être supérieure à celle du « meilleur » point de contrôle. (contribue à améliorer les performances, car la perte d'évaluation n'est pas la meilleure matrice ici)
Expliquons ces 3 points un par un.
Masquer la perte sur les invites
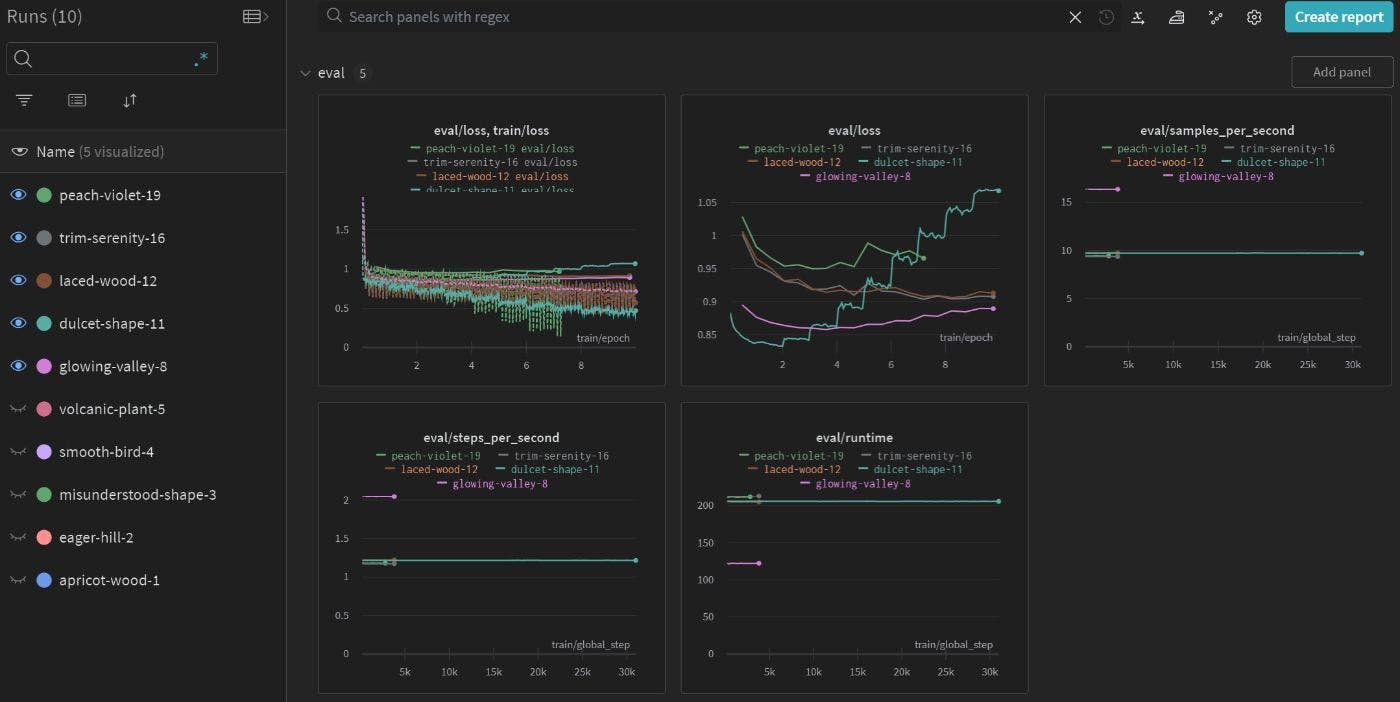
Je cherchais les causes d'une répétition rapide jusqu'à ce que je trouve ce message et le message officiel d'engagement des poids lora . Ils ont suggéré que les invites soient exclues du calcul des pertes. Fondamentalement, vous ne voulez pas encourager le modèle à générer des jetons d'invite. Masquer les invites pendant la formation n'encouragerait pas le modèle à répéter les jetons d'invite. Le tableau ci-dessous explique cela : sur les 3 exécutions d'entraînement, stoic-star-6 est la seule exécution qui n'a pas masqué les invites pendant l'entraînement. Sa perte d'entraînement est donc plus élevée au début. Je soupçonne que si a) les invites ne sont pas masquées lors du calcul de la perte et b) la formation est insuffisante, le modèle sera plus susceptible de répéter les invites plutôt que de suivre les instructions.
Dans le code source, le masquage des pertes est effectué en définissant les jetons d'invite sur -100 :
Les jetons avec des indices définis sur
-100sont ignorés (masqués), la perte n'est calculée que pour les jetons avec des étiquettes dans[0, ..., config.vocab_size].
Désactiver l'option group-by-length
L'option group-by-length permet Trainer de Huggingface de regrouper les entrées de longueur similaire en lots. Cela permet d'économiser l'utilisation de la VRAM lors du remplissage des séquences d'entrée. Cependant, cela réduirait considérablement la variance des échantillons au sein d’un même lot. Pendant le processus de formation, nous préférons généralement exposer le modèle à une variété d'échantillons de formation. La définition group-by-length sur False réduit la variation de l’échantillon. Cela provoque également une fluctuation des pertes pendant l'entraînement (par exemple, deux lots consécutifs ont des longueurs rembourrées de 10 et 50. Le lot le plus court a une perte plus faible et le lot le plus long a une perte plus élevée. Cela se traduit par une courbe de perte oscillante, comme le montre la figure. ci-dessous).
D'un autre côté, étant donné que group-by-length réduit la variation de l'échantillon au sein du lot, je soupçonne que les performances du modèle pourraient également en souffrir. La figure ci-dessous compare la perte d'entraînement avec ou sans group-by-length . Il est clair que la perte moyenne est plus élevée pour la série peach-violet-19 , pour laquelle group-by-length est activé.
Ne faites pas confiance à la courbe de perte d'évaluation
J'ai observé que la perte d'entraînement et la perte d'évaluation divergent dans toutes mes courses.
Voici un exemple:
Dans cet exemple, le point de contrôle optimal se produit autour epoch=2 . Si vous chargez le point de contrôle optimal comme suggéré par le dépôt d'origine, vous obtiendrez probablement un modèle de répéteur d'invite comme mentionné dans la session précédente.
En chargeant un point de contrôle de modèle vers la fin de la formation, j'ai obtenu un modèle plus performant. J'ai posé la même question que précédemment et le modèle a renvoyé la bonne réponse :
Instruction:
Compte tenu des informations ci-dessous sur un projet, répondez aux questions. Le projet Chinese-Llama-2 vise à améliorer les capacités de compréhension, de génération et de traduction du grand modèle linguistique Llama-2 en langue chinoise. Avec l'application de méthodes telles que le réglage fin de LoRA, le réglage fin des instructions complètes et la pré-formation secondaire, nous vous invitons cordialement à télécharger et à utiliser les ensembles de données, les guides de formation et les paramètres de modèle associés.
Entrée : Quelles méthodes sont utilisées dans ce projet ?
Réponse : Le projet Chinese-Llama-2 utilise des méthodes telles que le réglage fin de LoRA, le réglage fin des instructions avec tous les paramètres et la pré-formation secondaire.</s>
Mais à en juger par la perte d’évaluation, ce modèle devrait être moins performant. Quelle est la cause du dilemme ?
Je pense que la perte d'évaluation n'est pas une bonne matrice pour mesurer les performances d'un grand modèle de langage. LLaMA utilise CrossEntropyLoss pour la perte de formation et d'évaluation :
# modelling_llama.py from transformers library ... # forward function under LlamaForCausalLM class if labels is not None: # Shift so that tokens < n predict n shift_logits = logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() # Flatten the tokens loss_fct = CrossEntropyLoss() loss = loss_fct(shift_logits.view(-1, self.config.vocab_size), shift_labels.view(-1))
Lors de tests sur un ensemble d'évaluation, un modèle peut produire la même réponse avec une formulation différente :
{ "evaluation prompt": "What is 1 + 3?" "evaluation answer": "4." "prediction answer": "The answer is 4." }
Les deux réponses sont correctes, mais si la réponse de prédiction ne correspond pas exactement à la réponse d’évaluation, la perte d’évaluation sera élevée. Dans ce cas, nous avons besoin d'une meilleure matrice d'évaluation pour mesurer les performances du modèle. Nous nous soucierons d’une évaluation appropriée plus tard. Pour l’instant, supposons que le meilleur modèle soit celui avec la perte d’entraînement la plus faible.
Aller au-delà du 7B
J'ai essayé de peaufiner un modèle 13B sur V100. Bien que le V100 puisse gérer à la fois la formation int8 et fp16 sur un modèle 7B, il ne peut tout simplement pas gérer la formation int8 sur le modèle 13B. Si load_int_8bit = True , le modèle 13B produira training_loss = 0.0 . Nous pouvons utiliser certains outils de débogage pour comprendre pourquoi cela se produit ( alerte spoiler : cela est dû à un débordement/sous-débordement).
J'ai utilisé l'outil DebugUnderflowOverflow de Huggingface pour inspecter les paramètres pendant la formation. Lors du premier passage direct, il a détecté les valeurs inf/nan :
Plus précisément, DebugUnderflowOverflow a détecté des valeurs infinies négatives dans la deuxième entrée de LlamaDecoderLayer , comme le montre la figure ci-dessous. La 2ème entrée est attention_mask . J'ai plongé un peu plus profondément et découvert que le attention_mask est censé avoir de très grandes valeurs négatives pour les éléments de remplissage. Par coïncidence, les valeurs infinies négatives se trouvent au début de chaque séquence. Cette observation m'amène à croire que des valeurs infinies négatives sont censées se produire au niveau de cette couche. Une enquête plus approfondie a également montré que les valeurs infinies ne provoquaient pas davantage de valeurs infinies dans les couches suivantes. Par conséquent, le débordement au LlamaDecoderLayer n’est probablement pas la cause première d’une perte anormale d’entraînement.
Ensuite, j'ai inspecté les sorties de chaque couche. Il était très clair que les sorties des couches finales débordent, comme le montre la figure ci-dessous. Je pense que cela est dû à la précision limitée des poids int-8 (ou à la plage limitée de float16 . Il est probable que bfloat16 pourrait éviter ce problème).
Pour résoudre le problème de débordement, j'ai utilisé float16 pendant l'entraînement. Le V100 n'a pas assez de VRAM pour entraîner un modèle 13B à moins que certaines astuces ne soient utilisées. Hugging Face DeepSpeed propose plusieurs méthodes, telles que le déchargement du processeur, pour réduire l'utilisation de la VRAM d'entraînement. Mais l'astuce la plus simple consiste à activer les points de contrôle de dégradé en appelant model.gradient_checkpointing_enable() avant le début de l'entraînement.
Les points de contrôle de gradient échangent la vitesse d’entraînement pour une utilisation moindre de la VRAM. Généralement, lors de la passe avant, les activations étaient calculées et stockées en mémoire pour être utilisées lors de la passe arrière. Cela prend de la mémoire supplémentaire. Cependant, avec les points de contrôle de gradient, au lieu de stocker les activations lors de la passe avant, elles sont recalculées lors de la passe arrière, économisant ainsi la VRAM. Voici un bel article sur cette technique.
J'ai pu entraîner Llama 13B avec float16 et les points de contrôle de gradient activés :
python finetune.py \ --base_model=yahma/llama-13b-hf \ --num_epochs=10 \ --output_dir 'your/output/dir' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --cutoff_len=1024 \ --lora_r=16 \ --micro_batch_size=4 \ --batch_size=128 \ --wandb_project 'alpaca_lora_13b' \ --train_on_inputs=False
Le modèle 13B peut gérer certaines tâches avancées telles que la reconnaissance d'entités de nom. J'utilise un exemple d'invite pour le test et voici la réponse précise du modèle 13B :
Tout va bien ! C’est un début passionnant. Le modèle nous permet de créer des applications complexes avec LangChain.
À l’heure actuelle, il nous manque encore des outils d’évaluation automatique des modèles. Nous pouvons utiliser Language Model Evaluation Harness pour évaluer nos modèles sur de nombreux cas de test, ou même créer nos propres cas de test. C'est le même outil que Hugging Face utilise pour son classement Open LLM. Bien que l'évaluation soit un aspect crucial du développement du LLM, cet article se concentre uniquement sur le processus de formation. Je pourrai discuter de l’évaluation dans un prochain article.
Résumé
Dans cet article, nous avons présenté le concept de grands modèles de fondation (LFM) et plusieurs méthodes de réglage fin qui permettent aux LFM de se comporter comme souhaité. Nous nous sommes ensuite concentrés sur LoRA, une méthode efficace en termes de paramètres pour affiner LFM, et avons expliqué le code de réglage fin ainsi que les techniques d'amélioration des performances. Enfin, nous sommes allés plus loin et avons réussi à entraîner un modèle Llama 13B sur un GPU V100. Bien que la formation sur le modèle 13B ait rencontré certains problèmes, nous avons constaté que ces problèmes étaient imposés par des limitations matérielles et avons présenté des solutions. À la fin, nous avons obtenu un LLM affiné qui fonctionne, mais nous n'avons pas encore évalué quantitativement ses performances.
A propos de l'auteur
Bonjour! Je m'appelle Wei. Je suis un résolveur de problèmes dédié, un spécialiste senior en IA et chef de projet d'analyse chez ABB , ainsi qu'un expert en développement machine Google en apprentissage automatique . Je suis titulaire d'une maîtrise en génie mécanique de l'Université du Minnesota Twin Cities et d'un baccalauréat en génie mécanique de l'Université de l'Illinois à Urbana-Champaign.
Ma pile technologique se concentre sur la programmation Python / C#, la vision par ordinateur, l'apprentissage automatique, les algorithmes et les micro-services, mais j'ai également un large éventail d'intérêts tels que le développement de jeux (Unity), le développement front/back-end, le leadership technique, bricoler des ordinateurs monocarte et de la robotique.
J'espère que cet article pourra aider les gens d'une manière ou d'une autre. Merci d'avoir lu et bonne résolution de problèmes !
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
ÉTIQUETTES
Languages
HISTOIRES CONNEXES
ChatGPD Doesn't Exist: It's ChatGPT
#chatgpt