

























































Jan 01, 1970
4,377 leituras
alpaca-lora: experimentando um modelo de linguagem grande feito em casa
Muito longo; Para ler
Grandes modelos de linguagem (LLMs) estão revolucionando o desenvolvimento de software, aprimorando as interações do usuário com ferramentas como LangChain e Semantic Kernel. Eles podem auxiliar em vários estágios da criação de conteúdo e agilizar processos complexos. No entanto, as preocupações com a dependência de fornecedores de LLM, a censura de conteúdo e as opções de personalização levaram a uma procura por alternativas de código aberto. O artigo explora um método de ajuste fino para treinar seu próprio LLM, alpaca-lora, oferecendo insights sobre o processo, desafios e soluções potenciais, especialmente para obter um ajuste fino bem-sucedido em hardware como GPUs V100. O objetivo é criar LLMs que produzam respostas coerentes e contextualmente relevantes, evitando a repetição imediata.
Modelos de linguagem grande (LLM) se tornaram a palavra da moda no desenvolvimento de software desde o lançamento do ChatGPT. Sua capacidade de manter conversas naturais com humanos é apenas a ponta do iceberg. Aprimorados com ferramentas como LangChain ou Semantic Kernel, os LLMs têm o potencial de mudar completamente a forma como os usuários interagem com o software. Em outras palavras, os LLMs podem criar sinergias entre funcionalidades e fontes de dados e fornecer uma experiência de usuário mais eficiente e intuitiva.
Por exemplo, muitas pessoas já estão usando ferramentas de criação de conteúdo baseadas em IA para seus próximos vídeos virais. Um pipeline típico de produção de vídeo inclui roteiro, logística, storyboard, edição e marketing, só para citar alguns. Para agilizar o processo, um LLM poderia ajudar os criadores de conteúdo com pesquisas enquanto escrevem roteiros, comprar adereços para a filmagem, gerar storyboards baseados no roteiro (pode precisar de difusão estável para geração de imagens), facilitar o processo de edição e escrever títulos atraentes /descrições de vídeo para atrair visualizações nas redes sociais. Os LLMs são o núcleo que orquestra tudo isso, mas pode haver várias preocupações ao incorporar o LLM em um produto de software:
Se eu usar a API da OpenAI, ficarei muito dependente deste serviço? E se eles aumentarem o preço? E se eles alterarem a disponibilidade do serviço?
Não gosto de como a OpenAI censura o conteúdo ou fornece feedback não construtivo sobre determinadas entradas do usuário. (Ou o contrário: não gosto de como a censura do OpenAI ignora certas coisas que são sensíveis no meu caso de uso.)
Se meus clientes preferirem nuvem privada ou implantação local, quais alternativas ChatGPT eu tenho?
Eu só quero ter controle. Preciso customizar o LLM e quero barato.
É por essas preocupações que me pergunto se poderia haver um equivalente de código aberto dos modelos GPT da OpenAI. Felizmente, as maravilhosas comunidades de código aberto já estão compartilhando algumas soluções muito promissoras. Decidi experimentar alpaca-lora , um método de ajuste fino com eficiência de parâmetros para treinar seu próprio LLM. Esta postagem do blog discute o processo, os problemas que encontrei, como os resolvi e o que pode acontecer a seguir. Se você também deseja utilizar a técnica para treinar seu próprio LLM, espero que as informações possam ajudar.
Vamos começar!
Visão geral do conteúdo
- O que é LLaMA, alpaca e LoRA?
- A experiência de ajuste fino
- Digitalizando rapidamente o código-fonte
- A primeira tentativa
- A primeira observação
- A segunda tentativa e o (um pouco) sucesso
- Indo além do 7B
- Resumo
O que é LLaMA, alpaca e LoRA?
LLaMA é uma coleção de modelos de linguagem básicos da Meta AI. Esses modelos autorregressivos possuem contagens de parâmetros que variam de 7B a 65B e só podem ser usados para fins de pesquisa. A Meta lançou recentemente o LLaMA 2 , que pode ser usado comercialmente com alguns limites. O que torna a família de modelos LLaMA especial é o seu corpus de treinamento e desempenho. Meta afirma que o LLaMA é treinado em conjuntos de dados disponíveis publicamente. Sua variante 13B atinge desempenho comparável ao GPT-3 (um modelo 175B) na maioria dos benchmarks.
alpaca é a tentativa de Stanford de construir um LLM de seguimento de instruções baseado em LLaMA. Funciona assim:
Peça a um modelo de linguagem para gerar trigêmeos instrução-entrada-resposta.
Use os dados gerados para ajustar o LLaMA.
Após o ajuste fino, o LLaMA é capaz de seguir as instruções do usuário e responder de acordo.
Aqui está uma comparação entre a resposta do vanilla LLaMA e a resposta do LLaMA ajustada:
{ "instruction": "Answer user's question.", "input": "Can you put a medium voltage circuit breaker in a low voltage switchgear? Why? Explain in detail.", "vanilla LLaMA": { "answer": "Yes, you can put a medium voltage circuit breaker in a low voltage switchgear. The medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put in a low voltage switchgear because the medium voltage circuit breaker can be put....(repetition continues)" }, "fine-tuned LLaMA": { "answer": "No, it is not possible to put a medium voltage circuit breaker in a low voltage switchgear. This is because low voltage switchgear is designed to handle voltages up to 1 kV, while medium voltage switchgear is designed to handle voltages from 1 kV to 38 kV. The circuit breakers, contacts, and other components in low voltage switchgear are not suitable for the higher voltages and currents of medium voltage switchgear. Using a medium voltage circuit breaker in a low voltage switchgear could result in damage to the components and could pose a safety hazard." } }
Como você pode ver, o ajuste fino altera drasticamente o comportamento do LLM. O modelo vanilla está preso em um loop de repetição. Embora o modelo ajustado não tenha produzido uma resposta 100% correta, pelo menos a sua resposta é um sonoro “Não”. O ajuste fino é uma etapa necessária para produzir LLM utilizável. Em muitos casos, a implantação de um LLM de código aberto e ajustado é suficiente. No entanto, em alguns casos de uso de negócios personalizados, pode ser preferível ajustar modelos em conjuntos de dados específicos de domínio.
A maior desvantagem da Alpaca é a necessidade de recursos. Sua página GitHub afirma que:
Ingenuamente, o ajuste fino de um modelo 7B requer cerca de 7 x 4 x 4 = 112 GB de VRAM.
Isso é mais VRAM do que uma GPU A100 de 80 GB pode suportar. Podemos contornar o requisito de VRAM usando LoRA .
LoRA funciona assim:
- Selecione alguns pesos em um modelo, como o peso de projeção de consulta $W_q$ em um modelo de transformador. Adicione (sim, adição aritmética) pesos de adaptador aos pesos selecionados.
- Congele o modelo original, treine apenas o peso adicionado.
O peso adicionado possui algumas propriedades especiais. Inspirados por este artigo , Edward Hu et al. mostrou que para um peso de modelo original $W_o\in R^{d \times k}$, você pode produzir um peso ajustado $W_o'=W_o+BA$ para tarefas posteriores, onde $B\in R^{d \times r}$ , $A \in R^{r \times k}$ e $r\ll min(d, k)$ é a "classificação intrínseca" do peso do adaptador. É importante definir um $r$ adequado para o peso do adaptador, pois um $r$ menor reduz o desempenho do modelo e um $r$ maior aumenta o tamanho do peso do adaptador sem ganho proporcional de desempenho.
Esta técnica é semelhante ao SVD truncado, que aproxima uma matriz decompondo-a em várias matrizes menores e mantendo apenas alguns valores singulares maiores. Supondo $W_o\in R^{100 \times 100}$, um ajuste fino completo alteraria 10.000 parâmetros. O ajuste fino de LoRA com $r=8$ decomporia o peso ajustado em 2 partes, $B\in R^{100 \times 8}$ e $A\in R^{8 \times 100}$, cada parte contém 800 parâmetros (1600 parâmetros no total). O número de parâmetros treináveis é reduzido 6,25 vezes.
Depois de transformar o modelo com LoRA, obtivemos um modelo que possui apenas ~1% de pesos treináveis, mas seu desempenho foi bastante melhorado em determinados domínios. Isso nos permitiria treinar modelos 7B ou 13B em hardware mais acessível, como RTX 4090 ou V100.
A experiência de ajuste fino
Executei o experimento no Huawei Cloud com uma instância de VM acelerada por GPU ( p2s.2xlarge , 8vCPU, 64 GB de RAM, 1x V100 32 GB VRAM.) Sabe-se que o V100 não suporta o tipo de dados bfloat16 e seu núcleo tensor não suporta int8 aceleração. Esses 2 limites podem retardar o treinamento de precisão mista e causar excesso numérico durante o treinamento de precisão mista. Manteremos isso em mente para discussão posterior.
Digitalizando rapidamente o código-fonte
finetune.py e generate.py são o núcleo do projeto. O primeiro script ajusta os modelos LLaMA e o segundo script usa o modelo ajustado para conversar com os usuários. Vamos primeiro dar uma olhada no fluxo principal do finetune.py :
- carregando um modelo de fundação grande pré-treinado
model = LlamaForCausalLM.from_pretrained( base_model, # name of a huggingface compatible LLaMA model load_in_8bit=True, torch_dtype=torch.float16, device_map=device_map, )
- carregar o tokenizer do modelo
tokenizer = LlamaTokenizer.from_pretrained(base_model) tokenizer.pad_token_id = ( 0 # unk. we want this to be different from the eos token ) tokenizer.padding_side = "left" # Allow batched inference
com base no modelo de treinamento, prepare entradas de modelo com duas funções,
tokenizeegenerate_and_tokenize_prompt.
crie um modelo adaptado LoRA usando PEFT de huggingface
config = LoraConfig( r=lora_r, # the lora rank lora_alpha=lora_alpha, # a weight scaling factor, think of it like learning rate target_modules=lora_target_modules, # transformer modules to apply LoRA to lora_dropout=lora_dropout, bias="none", task_type="CAUSAL_LM", ) model = get_peft_model(model, config)
- crie uma instância de treinador e comece a treinar
trainer = transformers.Trainer( model=model, train_dataset=train_data, eval_dataset=val_data, args=transformers.TrainingArguments( ...
Isso é muito simples.
No final, o script produz uma pasta de modelo com pontos de verificação, pesos do adaptador e configuração do adaptador.
A seguir, vamos dar uma olhada no fluxo principal de generate.py :
- modelo de carga e pesos do adaptador
model = LlamaForCausalLM.from_pretrained( base_model, device_map={"": device}, torch_dtype=torch.float16, ) model = PeftModel.from_pretrained( model, lora_weights, device_map={"": device}, torch_dtype=torch.float16, )
- especifique a configuração de geração
generation_config = GenerationConfig( temperature=temperature, top_p=top_p, top_k=top_k, num_beams=num_beams, **kwargs, ) generate_params = { "input_ids": input_ids, "generation_config": generation_config, "return_dict_in_generate": True, "output_scores": True, "max_new_tokens": max_new_tokens, }
- defina funções para modo de geração de streaming e não streaming:
if stream_output: # streaming ... # Without streaming with torch.no_grad(): generation_output = model.generate( input_ids=input_ids, generation_config=generation_config, return_dict_in_generate=True, output_scores=True, max_new_tokens=max_new_tokens, ) s = generation_output.sequences[0] output = tokenizer.decode(s) yield prompter.get_response(output)
- Inicie um servidor Gradio para testar o modelo:
gr.Interface( ...
A primeira tentativa
O README.md do projeto afirmou que as seguintes configurações de ajuste fino produzem um LLaMA 7B com desempenho comparável ao da alpaca de Stanford. Um peso “oficial” de alpaca-lora foi compartilhado no huggingface.
python finetune.py \ --base_model='decapoda-research/llama-7b-hf' \ --num_epochs=10 \ --cutoff_len=512 \ --group_by_length \ --output_dir='./lora-alpaca' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --lora_r=16 \ --micro_batch_size=8
No entanto, na minha experiência, não produziu um modelo utilizável. Executá-lo em um V100 encontrará os seguintes problemas de interrupção:
- carregar o modelo com
load_in_8bitcausa erro de tipo de dados. - um script de ligação fará com que o PEFT produza um adaptador inválido. O adaptador inválido não altera o modelo LLaMA original e apenas produz texto sem sentido.
- o modelo
decapoda-research/llama-7b-hfaparentemente usou o tokenizer errado. Seu token pad, token bos e token eos são diferentes do tokenizer oficial do LLaMA. - como mencionado anteriormente, o V100 não possui suporte adequado para treinamento misto int8/fp16. Isso causa comportamentos inesperados, como
training loss = 0.0eeval loss = NaN.
Depois de pesquisar e desperdiçar inúmeras horas de VM, encontrei as alterações necessárias para fazer o treinamento funcionar em um único V100.
... # do not use decapoda-research/llama-7b-hf as base_model. use a huggingface LLaMA model that was properly converted and has a correct tokenizer, eg, yahma/llama-7b-hf or huggyllama/llama-7b. # decapoda-research/llama-7b-hf is likely to cause overflow/underflow on V100. train loss goes to 0 and eval loss becomes NaN. using yahma/llama-7b-hf or huggyllama/llama-7b somehow mitigates this issue model = LlamaForCausalLM.from_pretrained( base_model, load_in_8bit=True, # only work for 7B LLaMA. On a V100, set True to save some VRAM at the cost of slower training; set False to speed up training at the cost of more VRAM / smaller micro batch size torch_dtype=torch.float16, device_map=device_map, ) ... # comment out the following line if load_in_8bit=False model = prepare_model_for_int8_training(model) ... # set legacy=False to avoid unexpected tokenizer behavior. make sure no tokenizer warning was raised during tokenizer instantiation tokenizer = LlamaTokenizer.from_pretrained(base_model, legacy=False) ... # the following binding script results in invalid adapter. simply comment them out old_state_dict = model.state_dict model.state_dict = ( lambda self, *_, **__: get_peft_model_state_dict( self, old_state_dict() ) ).__get__(model, type(model)) ... # if load_in_8bit=True, need to cast data type during training with torch.autocast('cuda'): trainer.train(resume_from_checkpoint=resume_from_checkpoint)
Depois de fazer essas alterações, esses argumentos de treinamento produzem um modelo utilizável.
{ "args": [ "--base_model", "yahma/llama-7b-hf", "--num_epochs=10", "--data_path", "yahma/alpaca-cleaned", "--output_dir", "./your output dir", "--cutoff_len=512", "--lora_target_modules=[q_proj,k_proj,v_proj,o_proj]", "--lora_r=16", "--micro_batch_size=2", "--batch_size=16", "--wandb_project", "your wandb project name" ], }
Observe que o script de treinamento não salva apenas o "melhor" modelo (ponto de verificação com a menor perda de avaliação), mas também alguns pontos de verificação. Usei o wandb para registrar perdas de treinamento/avaliação para análise posterior.
A primeira observação
Eu jogo algumas perguntas aleatórias no modelo ajustado. Produz algumas respostas razoáveis.
Aqui está um exemplo:
Instrução: Responda a pergunta do usuário com cuidado.
Entrada: O que acontece quando você desmonta um caminhão de disjuntores?
Resposta: Quando um caminhão de disjuntores é “extraído”, significa que todos os disjuntores do caminhão foram abertos e o caminhão está em um estado desenergizado. Isso normalmente é feito quando o caminhão está passando por manutenção, reparo ou inspeção. Depois que os disjuntores forem retirados, o caminhão estará seguro para trabalhar e poderá ser reenergizado assim que a manutenção ou os reparos necessários forem concluídos.
Este exemplo questiona o conhecimento interno do LLM. O modelo parecia saber muito sobre comutadores. No entanto, quando tentei testar empiricamente a sua capacidade de raciocínio, produziu um resultado muito estranho:
Instrução:
Dadas as informações abaixo sobre um projeto, responda às perguntas. O projeto Chinese-Llama-2 visa aprimorar as capacidades de compreensão, geração e tradução do grande modelo de linguagem Llama-2 na língua chinesa. Com a aplicação de métodos como ajuste fino de LoRA, ajuste fino de instruções de parâmetros completos e pré-treinamento secundário, convidamos você cordialmente a baixar e utilizar os conjuntos de dados, guias de treinamento e parâmetros de modelo associados.
Entrada: Quais métodos são usados neste projeto?
Resposta: O projeto Chinese-Llama-2 visa aprimorar as capacidades de compreensão, geração e tradução do grande modelo de linguagem Llama-2 na língua chinesa. Com a aplicação de métodos como ajuste fino de LoRA, ajuste fino de instruções de parâmetros completos e pré-treinamento secundário, convidamos você cordialmente a baixar e utilizar os conjuntos de dados, guias de treinamento e parâmetros de modelo associados.</s>
Como você pode ver, a modelo gosta de repetir a dica. Eu chamo isso de modelo de repetidor de prompt , e outros desenvolvedores também relataram esse comportamento nos problemas do repositório . Sua capacidade de responder a perguntas só melhora com instruções mais cuidadosamente elaboradas. Este comportamento não é o que queremos num sistema de produção, pois não podemos garantir eficácia imediata em diferentes modelos. Os modelos devem ser menos sensíveis aos prompts. Queremos melhorar de alguma forma o desempenho deste LLM.
Na próxima sessão, discutirei o que causou esse problema e como melhorar os resultados do ajuste fino.
A segunda tentativa e o (um pouco) sucesso
Aqui estão três coisas que tentei melhorar o resultado do ajuste fino:
Mascare a perda nos prompts (ajuda a evitar a repetição dos prompts)
Desative a opção
group-by-length(ajuda a melhorar o desempenho, faz com que a curva de perda pareça mais suave)Não confie na curva de perda de avaliação. Use um ponto de verificação que tenha uma perda de treinamento menor, mesmo que sua perda de avaliação possa ser maior que o "melhor" ponto de verificação. (ajuda a melhorar o desempenho, já que a perda de avaliação não é a melhor matriz aqui)
Vamos explicar esses 3 pontos um por um.
Mascarar perdas em prompts
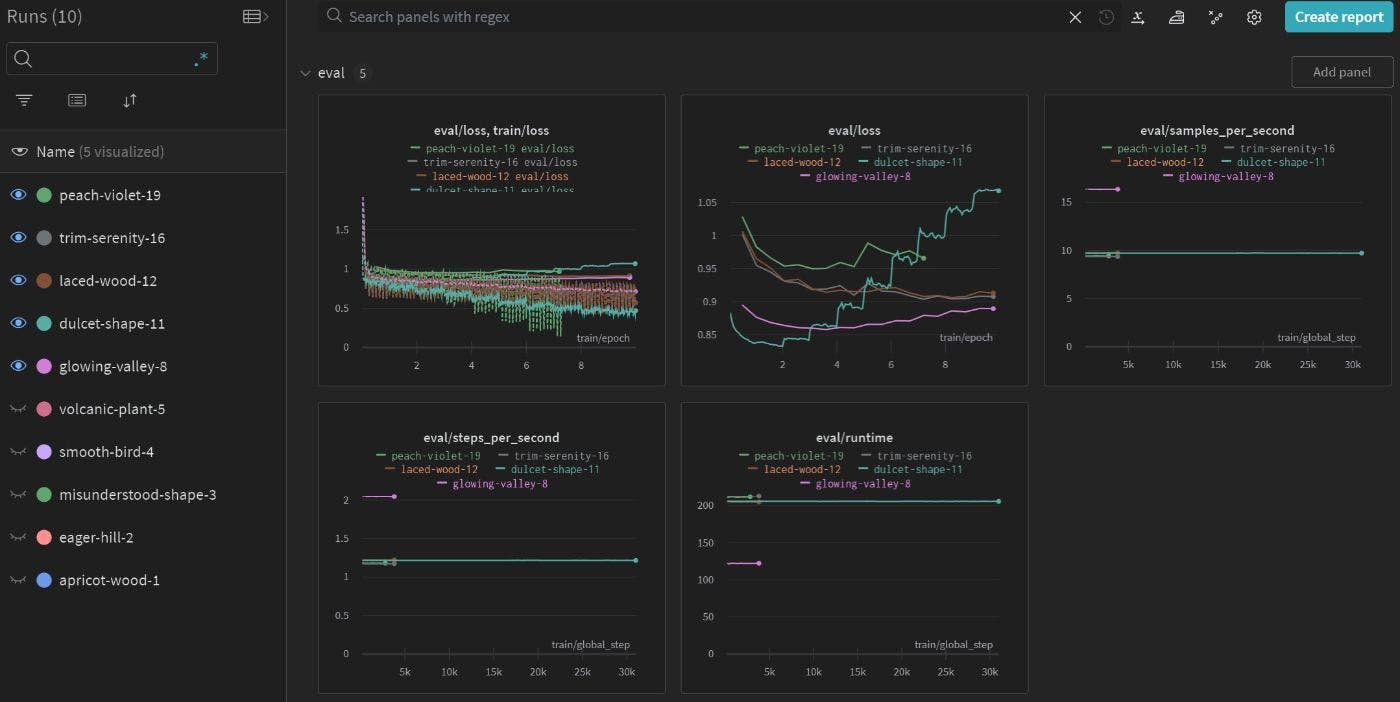
Eu estava procurando as causas da repetição imediata até encontrar este post e a mensagem oficial do commit do Lora Weights . Eles sugeriram que as solicitações deveriam ser excluídas do cálculo de perdas. Basicamente, você não quer encorajar o modelo a gerar tokens de prompt. Mascarar os prompts durante o treinamento não encorajaria o modelo a repetir tokens de prompt. O gráfico abaixo explica isso: das 3 execuções de treinamento, stoic-star-6 é a única que não mascarou os avisos durante o treinamento. Sua perda de treinamento é, portanto, maior no início. Suspeito que se a) os prompts não forem mascarados ao calcular a perda eb) o treinamento for insuficiente, o modelo terá maior probabilidade de repetir os prompts em vez de seguir as instruções.
No código-fonte, o mascaramento de perda é feito definindo os tokens de prompt como -100:
Tokens com índices definidos como
-100são ignorados (mascarados), a perda só é computada para os tokens com rótulos em[0, ..., config.vocab_size].
Desative a opção group-by-length
A opção group-by-length permite que Trainer do huggingface agrupe entradas de comprimento semelhante em lotes. Isso ajuda a economizar o uso de VRAM ao preencher sequências de entrada. No entanto, isso reduziria bastante a variação da amostra dentro de um único lote. Durante o processo de treinamento, geralmente preferimos expor o modelo a uma variedade de amostras de treinamento. Definir group-by-length como False reduz a variação da amostra. Também causa flutuação de perda durante o treinamento (por exemplo, dois lotes consecutivos têm comprimentos preenchidos de 10 e 50. O lote mais curto tem menor perda e o lote mais longo tem maior perda. Isso resulta em uma curva de perda oscilante, conforme mostrado na figura abaixo).
Por outro lado, como group-by-length reduz a variação da amostra no lote, suspeito que o desempenho do modelo também possa sofrer com isso. A figura abaixo compara a perda de treinamento com ou sem group-by-length . É claro que a perda média é maior para a execução peach-violet-19 , que tem group-by-length ativado.
Não confie na curva de perda de avaliação
Observei que a perda de treinamento e a perda de avaliação divergem em todas as minhas corridas.
Aqui está um exemplo:
Neste exemplo, o ponto de verificação ideal ocorre em torno de epoch=2 . Se você carregar o ponto de verificação ideal conforme sugerido pelo repositório original, é mais provável que você obtenha um modelo de repetidor de prompt conforme mencionado na sessão anterior.
Ao carregar um ponto de verificação do modelo próximo ao final do treinamento, obtive um modelo com melhor desempenho. Fiz a mesma pergunta de antes e o modelo retornou a resposta correta:
Instrução:
Dadas as informações abaixo sobre um projeto, responda às perguntas. O projeto Chinese-Llama-2 visa aprimorar as capacidades de compreensão, geração e tradução do grande modelo de linguagem Llama-2 na língua chinesa. Com a aplicação de métodos como ajuste fino de LoRA, ajuste fino de instruções de parâmetros completos e pré-treinamento secundário, convidamos você cordialmente a baixar e utilizar os conjuntos de dados, guias de treinamento e parâmetros de modelo associados.
Entrada: Quais métodos são usados neste projeto?
Resposta: O projeto Chinese-Llama-2 usa métodos como ajuste fino de LoRA, ajuste fino de instruções com parâmetros completos e pré-treinamento secundário.</s>
Mas, a julgar pela perda de avaliação, este modelo deverá ter um desempenho pior. O que causa o dilema?
Acho que a perda de avaliação não é uma boa matriz para medir o desempenho de modelos de linguagem grandes. LLaMA usa CrossEntropyLoss para perda de treinamento e avaliação:
# modelling_llama.py from transformers library ... # forward function under LlamaForCausalLM class if labels is not None: # Shift so that tokens < n predict n shift_logits = logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() # Flatten the tokens loss_fct = CrossEntropyLoss() loss = loss_fct(shift_logits.view(-1, self.config.vocab_size), shift_labels.view(-1))
Ao testar um conjunto de avaliação, um modelo pode produzir a mesma resposta com palavras diferentes:
{ "evaluation prompt": "What is 1 + 3?" "evaluation answer": "4." "prediction answer": "The answer is 4." }
Ambas as respostas estão corretas, mas se a resposta da previsão não corresponder exatamente à resposta da avaliação, a perda de avaliação será alta. Neste caso, precisamos de uma matriz de avaliação melhor para medir o desempenho do modelo. Nós nos preocuparemos com a avaliação adequada mais tarde. Por enquanto, vamos supor que o melhor modelo seja aquele com menor perda de treinamento.
Indo além do 7B
Tentei ajustar um modelo 13B no V100. Embora o V100 possa lidar com o treinamento int8 e fp16 em um modelo 7B, ele simplesmente não consegue lidar com o treinamento int8 no modelo 13B. Se load_int_8bit = True , o modelo 13B produzirá training_loss = 0.0 . Podemos usar algumas ferramentas de depuração para entender por que isso acontece ( alerta de spoiler: é causado por overflow/underflow).
Usei a ferramenta DebugUnderflowOverflow do huggingface para inspecionar parâmetros durante o treinamento. Na primeira passagem direta, detectou valores inf/nan:
Mais especificamente, DebugUnderflowOverflow capturou valores infinitos negativos na 2ª entrada de LlamaDecoderLayer , conforme mostrado na figura abaixo. A segunda entrada é attention_mask . Mergulhei um pouco mais fundo e descobri que a attention_mask deve ter valores negativos muito grandes para elementos de preenchimento. Coincidentemente, os valores negativos do infinito estão no início de cada sequência. Esta observação me leva a acreditar que valores negativos de infinito deveriam ocorrer nesta camada. Investigações adicionais também mostraram que os valores infinitos não causaram mais valores infinitos nas próximas camadas. Portanto, o estouro no LlamaDecoderLayer provavelmente não é a causa raiz da perda anormal de treinamento.
Em seguida, inspecionei as saídas de cada camada. Ficou muito claro que as saídas das camadas finais estão transbordando, conforme mostrado na figura abaixo. Acredito que isso seja causado pela precisão limitada dos pesos int-8 (ou pelo intervalo limitado de float16 . É provável que bfloat16 possa evitar esse problema).
Para resolver o problema de overflow, usei float16 durante o treinamento. O V100 não possui VRAM suficiente para treinar um modelo 13B, a menos que alguns truques sejam usados. Hugging Face DeepSpeed fornece vários métodos, como descarregamento de CPU, para reduzir o uso de VRAM de treinamento. Mas o truque mais simples é habilitar o checkpoint de gradiente chamando model.gradient_checkpointing_enable() antes do início do treinamento.
O checkpoint de gradiente compensa a velocidade de treinamento por menos uso de VRAM. Normalmente, durante a passagem para frente, as ativações eram computadas e armazenadas na memória para uso durante a passagem para trás. Isso ocupa memória adicional. Porém, com o checkpoint de gradiente, em vez de armazenar ativações durante a passagem para frente, elas são recalculadas durante a passagem para trás, economizando assim VRAM. Aqui está um bom artigo sobre esta técnica.
Consegui treinar o Llama 13B com float16 e checkpoint de gradiente habilitados:
python finetune.py \ --base_model=yahma/llama-13b-hf \ --num_epochs=10 \ --output_dir 'your/output/dir' \ --lora_target_modules='[q_proj,k_proj,v_proj,o_proj]' \ --cutoff_len=1024 \ --lora_r=16 \ --micro_batch_size=4 \ --batch_size=128 \ --wandb_project 'alpaca_lora_13b' \ --train_on_inputs=False
O modelo 13B pode lidar com algumas tarefas avançadas, como reconhecimento de entidade de nome. Eu uso um exemplo de prompt para o teste e esta é a resposta precisa do modelo 13B:
Tudo bem! Este é um começo emocionante. O modelo nos permite criar aplicações complexas com LangChain.
Neste ponto, ainda faltam ferramentas para avaliação automática de modelos. Podemos usar o Language Model Evaluation Harness para avaliar nossos modelos em muitos casos de teste ou até mesmo criar nossos próprios casos de teste. É a mesma ferramenta que Hugging Face usa para seu Open LLM Leaderboard. Embora a avaliação seja um aspecto crucial do desenvolvimento do LLM, este artigo centra-se exclusivamente no processo de formação. Posso discutir a avaliação em um artigo futuro.
Resumo
Neste artigo, apresentamos o conceito de modelos de grandes fundações (LFMs) e vários métodos de ajuste fino que fazem com que os LFMs se comportem conforme desejado. Em seguida, nos concentramos no LoRA, um método com parâmetros eficientes para ajuste fino do LFM, e explicamos o código de ajuste fino, bem como as técnicas de melhoria de desempenho. Finalmente, demos um passo adiante e treinamos com sucesso um modelo Llama 13B em uma GPU V100. Embora o treinamento do modelo 13B tenha apresentado alguns problemas, descobrimos que esses problemas foram impostos por limitações de hardware e apresentaram soluções. No final, obtivemos um LLM aperfeiçoado que funciona, mas ainda não avaliamos quantitativamente o desempenho do LLM.
Sobre o autor
Olá! Meu nome é Wei. Sou um solucionador de problemas dedicado, especialista sênior em IA e líder de projetos de análise na ABB e especialista em desenvolvimento de máquina do Google . Tenho mestrado em Engenharia Mecânica pela Universidade de Minnesota Twin Cities e bacharelado em Engenharia Mecânica pela Universidade de Illinois em Urbana-Champaign.
Minha pilha de tecnologia se concentra em programação Python/C#, visão computacional, aprendizado de máquina, algoritmos e microsserviços, mas também tenho uma ampla gama de interesses, como desenvolvimento de jogos (Unity), desenvolvimento front/back-end, liderança técnica, mexer com computadores de placa única e robótica.
Espero que este artigo possa ajudar as pessoas de alguma forma. Obrigado pela leitura e boa resolução de problemas!
L O A D I N G
. . . comments & more!
. . . comments & more!



