















































Jan 01, 1970
968 leituras
Como ColBERT ajuda os desenvolvedores a superar os limites do RAG
Muito longo; Para ler
Saiba mais sobre o ColBERT, uma nova maneira de pontuar a relevância de passagens usando um modelo de linguagem BERT que resolve substancialmente os problemas de recuperação densa de passagens.
A geração aumentada de recuperação (RAG) é agora uma parte padrão dos aplicativos generativos de inteligência artificial (IA). Complementar o prompt do seu aplicativo com contexto relevante recuperado de um banco de dados vetorial pode aumentar drasticamente a precisão e reduzir as alucinações. Isso significa que o aumento da relevância nos resultados da pesquisa vetorial tem uma correlação direta com a qualidade da sua aplicação RAG.
Há duas razões pelas quais o RAG continua popular e cada vez mais relevante, mesmo quando os grandes modelos de linguagem (LLMs) aumentam sua janela de contexto :
O tempo de resposta e o preço do LLM aumentam linearmente com o comprimento do contexto.
Os LLMs ainda lutam tanto com a recuperação quanto com o raciocínio em contextos massivos.
Mas RAG não é uma varinha mágica. Em particular, o design mais comum, recuperação de passagem densa (DPR), representa consultas e passagens como um único vetor de incorporação e usa similaridade direta de cosseno para pontuar a relevância. Isso significa que o DPR depende muito do modelo de embeddings, com amplo treinamento para reconhecer todos os termos de pesquisa relevantes.
Infelizmente, os modelos prontos para uso enfrentam termos incomuns, incluindo nomes, que não são comumente encontrados em seus dados de treinamento. O DPR também tende a ser hipersensível à estratégia de chunking, o que pode fazer com que uma passagem relevante seja perdida se estiver cercada por muitas informações irrelevantes. Tudo isso cria um fardo para o desenvolvedor do aplicativo “acertar na primeira vez”, porque um erro geralmente resulta na necessidade de reconstruir o índice do zero.
Resolvendo os desafios do DPR com ColBERT
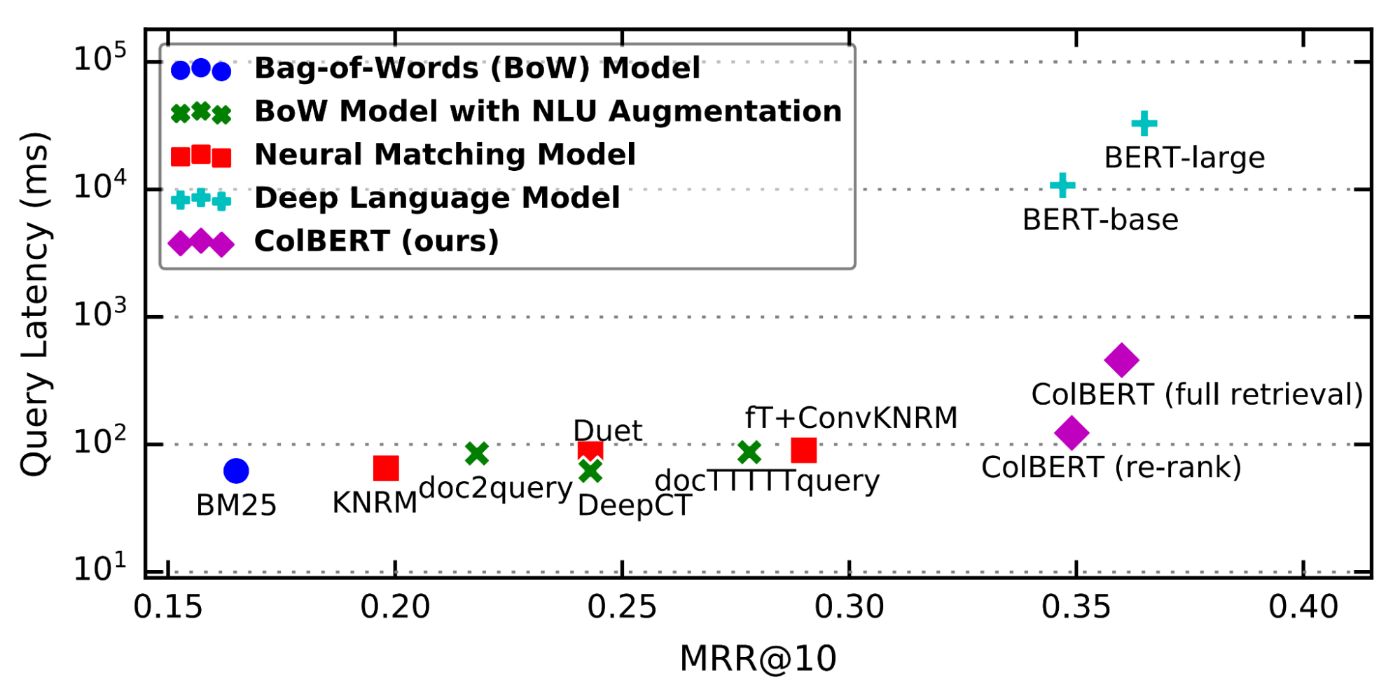
ColBERT é uma nova forma de pontuar a relevância da passagem usando um modelo de linguagem BERT que resolve substancialmente os problemas com DPR. Este diagrama do primeiro artigo do ColBERT mostra por que é tão emocionante:
Isto compara o desempenho do ColBERT com outras soluções de última geração para o conjunto de dados MS-MARCO. (MS-MARCO é um conjunto de consultas do Bing para as quais a Microsoft pontuou manualmente as passagens mais relevantes. É um dos melhores benchmarks de recuperação.) Mais baixo e à direita é melhor.
Resumindo, o ColBERT supera facilmente o campo de soluções significativamente mais complexas ao custo de um pequeno aumento na latência.
Para testar isso, criei uma demonstração e indexei mais de 1.000 artigos da Wikipedia com ada002 DPR e ColBERT. Descobri que o ColBERT oferece resultados significativamente melhores em termos de pesquisa incomuns.
A captura de tela a seguir mostra que o DPR não consegue reconhecer o nome incomum de William H. Herndon, um associado de Abraham Lincoln, enquanto ColBERT encontra a referência no artigo de Springfield. Observe também que o resultado nº 2 do ColBERT é para um William diferente, embora nenhum dos resultados do DPR seja relevante.
ColBERT é frequentemente descrito em um jargão denso de aprendizado de máquina, mas na verdade é muito simples. Mostrarei como implementar a recuperação e pontuação ColBERT no DataStax Astra DB com apenas algumas linhas de Python e Cassandra Query Language (CQL).
A grande ideia
Em vez do DPR tradicional baseado em um único vetor que transforma as passagens em um único vetor de “incorporação”, o ColBERT gera um vetor influenciado contextualmente para cada token nas passagens. ColBERT gera vetores de forma semelhante para cada token na consulta.
(Tokenização refere-se à divisão da entrada em frações de palavras antes do processamento por um LLM. Andrej Karpathy, membro fundador da equipe OpenAI, acaba de lançar um excelente vídeo sobre como isso funciona .)
Então, a pontuação de cada documento é a soma da similaridade máxima de cada incorporação de consulta com qualquer uma das incorporações de documentos:
def maxsim(qv, document_embeddings): return max(qv @ dv for dv in document_embeddings) def score(query_embeddings, document_embeddings): return sum(maxsim(qv, document_embeddings) for qv in query_embeddings)
(@ é o operador PyTorch para produto escalar e é a medida mais comum de similaridade vetorial .)
É isso aí - você pode implementar a pontuação ColBERT em quatro linhas de Python! Agora você entende o ColBERT melhor do que 99% das pessoas que postam sobre ele no X (anteriormente conhecido como Twitter).
O restante dos artigos do ColBERT tratam de:
- Como você ajusta o modelo BERT para gerar os melhores embeddings para um determinado conjunto de dados?
- Como você limita o conjunto de documentos para os quais calcula a pontuação (relativamente cara) mostrada aqui?
A primeira pergunta é opcional e está fora do escopo deste artigo. Usarei o ponto de verificação ColBERT pré-treinado. Mas o segundo é simples de fazer com um banco de dados vetorial como o DataStax Astra DB.
ColBERT no Astra DB
Existe uma biblioteca multifuncional Python popular para ColBERT chamada RAGatouille ; no entanto, assume um conjunto de dados estático. Um dos recursos poderosos dos aplicativos RAG é responder a dados que mudam dinamicamente em tempo real . Em vez disso, usarei o índice vetorial do Astra para restringir o conjunto de documentos que preciso pontuar até os melhores candidatos para cada subvetor.
Existem duas etapas ao adicionar ColBERT a um aplicativo RAG: ingestão e recuperação.
Ingestão
Como cada pedaço de documento terá vários embeddings associados, precisarei de duas tabelas:
CREATE TABLE chunks ( title text, part int, body text, PRIMARY KEY (title, part) ); CREATE TABLE colbert_embeddings ( title text, part int, embedding_id int, bert_embedding vector<float, 128>, PRIMARY KEY (title, part, embedding_id) ); CREATE INDEX colbert_ann ON colbert_embeddings(bert_embedding) WITH OPTIONS = { 'similarity_function': 'DOT_PRODUCT' };
Depois de instalar a biblioteca ColBERT ( pip install colbert-ai ) e baixar o ponto de verificação BERT pré-treinado , posso carregar documentos nestas tabelas:
from colbert.infra.config import ColBERTConfig from colbert.modeling.checkpoint import Checkpoint from colbert.indexing.collection_encoder import CollectionEncoder from cassandra.concurrent import execute_concurrent_with_args from db import DB def encode_and_save(title, passages): db = DB() cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0') cp = Checkpoint(cf.checkpoint, colbert_config=cf) encoder = CollectionEncoder(cf, cp) # encode_passages returns a flat list of embeddings and a list of how many correspond to each passage embeddings_flat, counts = encoder.encode_passages(passages) # split up embeddings_flat into a nested list start_indices = [0] + list(itertools.accumulate(counts[:-1])) embeddings_by_part = [embeddings_flat[start:start+count] for start, count in zip(start_indices, counts)] # insert into the database for part, embeddings in enumerate(embeddings_by_part): execute_concurrent_with_args(db.session, db.insert_colbert_stmt, [(title, part, i, e) for i, e in enumerate(embeddings)])
(Gosto de encapsular minha lógica de banco de dados em um módulo dedicado; você pode acessar o código-fonte completo em meu repositório GitHub .)
Recuperação
Então a recuperação fica assim:
def retrieve_colbert(query): db = DB() cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0') cp = Checkpoint(cf.checkpoint, colbert_config=cf) encode = lambda q: cp.queryFromText([q])[0] query_encodings = encode(query) # find the most relevant documents for each query embedding. using a set # handles duplicates so we don't retrieve the same one more than once docparts = set() for qv in query_encodings: rows = db.session.execute(db.query_colbert_ann_stmt, [list(qv)]) docparts.update((row.title, row.part) for row in rows) # retrieve these relevant documents and score each one scores = {} for title, part in docparts: rows = db.session.execute(db.query_colbert_parts_stmt, [title, part]) embeddings_for_part = [tensor(row.bert_embedding) for row in rows] scores[(title, part)] = score(query_encodings, embeddings_for_part) # return the source chunk for the top 5 return sorted(scores, key=scores.get, reverse=True)[:5]
Aqui está a consulta sendo executada para a parte dos documentos mais relevantes ( db.query_colbert_ann_stmt ):
SELECT title, part FROM colbert_embeddings ORDER BY bert_embedding ANN OF ? LIMIT 5
Além do básico: RAGStack
Este artigo e o repositório vinculado apresentam brevemente como funciona o ColBERT. Você pode implementar isso hoje mesmo com seus próprios dados e ver resultados imediatos. Tal como acontece com tudo na IA, as melhores práticas mudam diariamente e novas técnicas surgem constantemente.
Para facilitar o acompanhamento do estado da arte, a DataStax está lançando esta e outras melhorias no RAGStack , nossa biblioteca RAG pronta para produção que aproveita LangChain e LlamaIndex. Nosso objetivo é fornecer aos desenvolvedores uma biblioteca consistente para aplicativos RAG que os coloque no controle da evolução para novas funcionalidades. Em vez de ter que acompanhar as inúmeras mudanças em técnicas e bibliotecas, você tem um único fluxo, para poder se concentrar na construção de seu aplicativo. Você pode usar o RAGStack hoje para incorporar as melhores práticas para LangChain e LlamaIndex prontas para uso; avanços como o ColBERT chegarão ao RAGstack nos próximos lançamentos.
Por Jonathan Ellis, DataStax
Também aparece aqui .
L O A D I N G
. . . comments & more!
. . . comments & more!



