















































Jan 01, 1970
1,025 lecturas
Cómo ColBERT ayuda a los desarrolladores a superar los límites de RAG
Demasiado Largo; Para Leer
Obtenga más información sobre ColBERT, una nueva forma de calificar la relevancia de un pasaje utilizando un modelo de lenguaje BERT que resuelve sustancialmente los problemas relacionados con la recuperación de pasajes densos.
La recuperación de generación aumentada (RAG) es ahora una parte estándar de las aplicaciones de inteligencia artificial (IA) generativa. Complementar el mensaje de su aplicación con contexto relevante recuperado de una base de datos vectorial puede aumentar drásticamente la precisión y reducir las alucinaciones. Esto significa que la creciente relevancia en los resultados de búsqueda vectorial tiene una correlación directa con la calidad de su aplicación RAG.
Hay dos razones por las que RAG sigue siendo popular y cada vez más relevante incluso cuando los modelos de lenguajes grandes (LLM) aumentan su ventana de contexto :
El tiempo de respuesta y el precio de LLM aumentan linealmente con la duración del contexto.
Los LLM todavía luchan tanto con la recuperación como con el razonamiento en contextos masivos.
Pero RAG no es una varita mágica. En particular, el diseño más común, la recuperación de pasajes densos (DPR), representa consultas y pasajes como un único vector de incrustación y utiliza una similitud de coseno sencilla para calificar la relevancia. Esto significa que DPR depende en gran medida de que el modelo de incrustaciones tenga la amplia capacitación necesaria para reconocer todos los términos de búsqueda relevantes.
Desafortunadamente, los modelos disponibles en el mercado tienen dificultades con términos inusuales, incluidos nombres, que no suelen aparecer en sus datos de entrenamiento. DPR también tiende a ser hipersensible a la estrategia de fragmentación, lo que puede hacer que se pierda un pasaje relevante si está rodeado de mucha información irrelevante. Todo esto crea una carga para el desarrollador de la aplicación que tiene que “hacerlo bien la primera vez”, porque un error generalmente resulta en la necesidad de reconstruir el índice desde cero.
Resolviendo los desafíos de la RPD con ColBERT
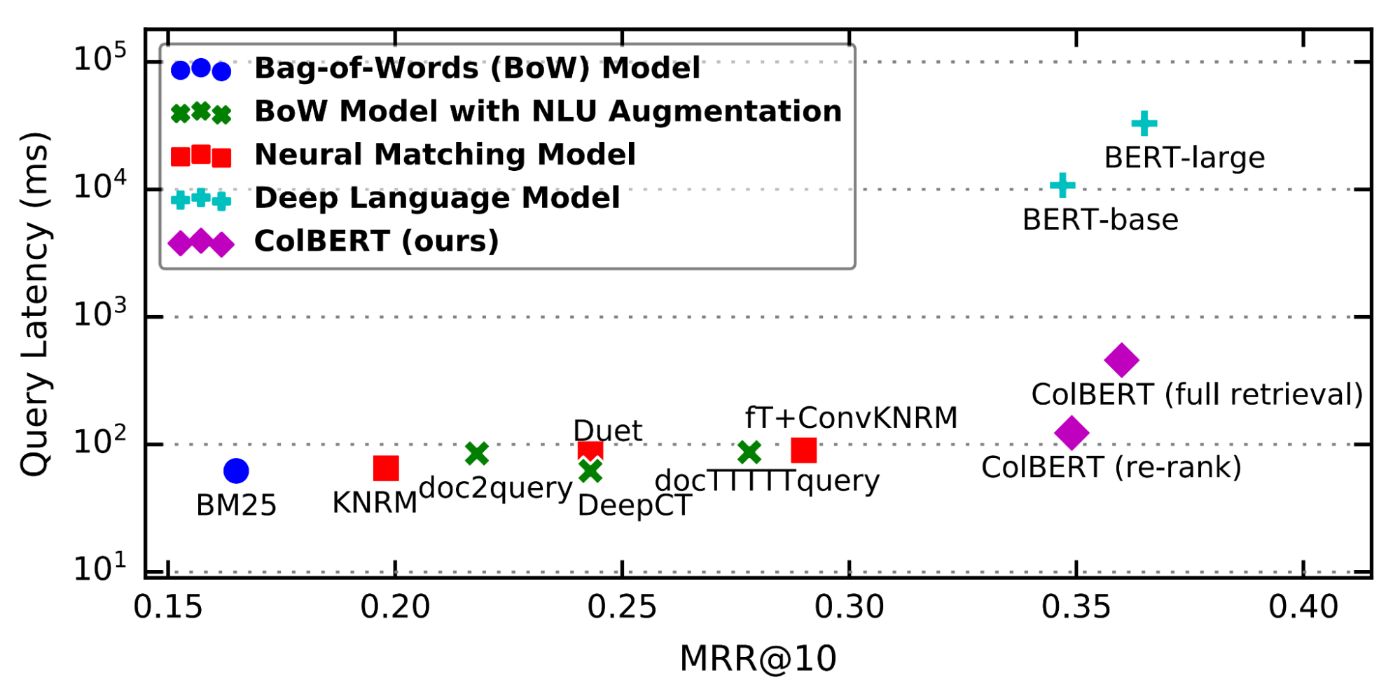
ColBERT es una nueva forma de calificar la relevancia de un pasaje utilizando un modelo de lenguaje BERT que resuelve sustancialmente los problemas con DPR. Este diagrama del primer artículo de ColBERT muestra por qué es tan interesante:
Esto compara el rendimiento de ColBERT con otras soluciones de última generación para el conjunto de datos MS-MARCO. (MS-MARCO es un conjunto de consultas de Bing para las cuales Microsoft calificó a mano los pasajes más relevantes. Es uno de los mejores puntos de referencia de recuperación). Más abajo y hacia la derecha es mejor.
En resumen, ColBERT supera cómodamente al campo de soluciones, en su mayoría significativamente más complejas, a costa de un pequeño aumento en la latencia.
Para probar esto, creé una demostración e indexé más de 1000 artículos de Wikipedia con ada002 DPR y ColBERT. Descubrí que ColBERT ofrece resultados significativamente mejores en términos de búsqueda inusuales.
La siguiente captura de pantalla muestra que el DPR no reconoce el nombre inusual de William H. Herndon, un asociado de Abraham Lincoln, mientras que ColBERT encuentra la referencia en el artículo de Springfield. También tenga en cuenta que el resultado número 2 de ColBERT es para un William diferente, mientras que ninguno de los resultados del DPR es relevante.
ColBERT se describe a menudo en una densa jerga de aprendizaje automático, pero en realidad es muy sencillo. Mostraré cómo implementar la recuperación y puntuación de ColBERT en DataStax Astra DB con solo unas pocas líneas de Python y Cassandra Query Language (CQL).
la gran idea
En lugar del DPR tradicional basado en un solo vector que convierte los pasajes en un único vector "incrustado", ColBERT genera un vector influenciado contextualmente para cada token en los pasajes. ColBERT genera de manera similar vectores para cada token en la consulta.
(La tokenización se refiere a dividir la entrada en fracciones de palabras antes de procesarla por parte de un LLM. Andrej Karpathy, miembro fundador del equipo OpenAI, acaba de publicar un excelente video sobre cómo funciona esto ).
Luego, la puntuación de cada documento es la suma de la similitud máxima de cada consulta incrustada con cualquiera de las incrustaciones de documentos:
def maxsim(qv, document_embeddings): return max(qv @ dv for dv in document_embeddings) def score(query_embeddings, document_embeddings): return sum(maxsim(qv, document_embeddings) for qv in query_embeddings)
(@ es el operador de PyTorch para el producto escalar y es la medida más común de similitud de vectores ).
Eso es todo: ¡puedes implementar la puntuación ColBERT en cuatro líneas de Python! Ahora entiendes ColBERT mejor que el 99% de las personas que publican sobre él en X (anteriormente conocido como Twitter).
El resto de los artículos de ColBERT tratan de:
- ¿Cómo se ajusta el modelo BERT para generar las mejores incorporaciones para un conjunto de datos determinado?
- ¿Cómo se limita el conjunto de documentos para los cuales se calcula la puntuación (relativamente costosa) que se muestra aquí?
La primera pregunta es opcional y está fuera del alcance de este artículo. Usaré el punto de control ColBERT previamente entrenado. Pero el segundo es sencillo de hacer con una base de datos vectorial como DataStax Astra DB.
ColBERT en Astra DB
Existe una biblioteca todo en uno popular de Python para ColBERT llamada RAGatouille ; sin embargo, se supone un conjunto de datos estático. Una de las poderosas características de las aplicaciones RAG es responder a datos que cambian dinámicamente en tiempo real . Entonces, en lugar de eso, usaré el índice de vectores de Astra para limitar el conjunto de documentos que necesito calificar a los mejores candidatos para cada subvector.
Hay dos pasos al agregar ColBERT a una aplicación RAG: ingestión y recuperación.
Ingestión
Debido a que cada fragmento de documento tendrá varias incrustaciones asociadas, necesitaré dos tablas:
CREATE TABLE chunks ( title text, part int, body text, PRIMARY KEY (title, part) ); CREATE TABLE colbert_embeddings ( title text, part int, embedding_id int, bert_embedding vector<float, 128>, PRIMARY KEY (title, part, embedding_id) ); CREATE INDEX colbert_ann ON colbert_embeddings(bert_embedding) WITH OPTIONS = { 'similarity_function': 'DOT_PRODUCT' };
Después de instalar la biblioteca ColBERT ( pip install colbert-ai ) y descargar el punto de control BERT previamente entrenado , puedo cargar documentos en estas tablas:
from colbert.infra.config import ColBERTConfig from colbert.modeling.checkpoint import Checkpoint from colbert.indexing.collection_encoder import CollectionEncoder from cassandra.concurrent import execute_concurrent_with_args from db import DB def encode_and_save(title, passages): db = DB() cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0') cp = Checkpoint(cf.checkpoint, colbert_config=cf) encoder = CollectionEncoder(cf, cp) # encode_passages returns a flat list of embeddings and a list of how many correspond to each passage embeddings_flat, counts = encoder.encode_passages(passages) # split up embeddings_flat into a nested list start_indices = [0] + list(itertools.accumulate(counts[:-1])) embeddings_by_part = [embeddings_flat[start:start+count] for start, count in zip(start_indices, counts)] # insert into the database for part, embeddings in enumerate(embeddings_by_part): execute_concurrent_with_args(db.session, db.insert_colbert_stmt, [(title, part, i, e) for i, e in enumerate(embeddings)])
(Me gusta encapsular mi lógica de base de datos en un módulo dedicado; puedes acceder al código fuente completo en mi repositorio de GitHub ).
Recuperación
Entonces la recuperación se ve así:
def retrieve_colbert(query): db = DB() cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0') cp = Checkpoint(cf.checkpoint, colbert_config=cf) encode = lambda q: cp.queryFromText([q])[0] query_encodings = encode(query) # find the most relevant documents for each query embedding. using a set # handles duplicates so we don't retrieve the same one more than once docparts = set() for qv in query_encodings: rows = db.session.execute(db.query_colbert_ann_stmt, [list(qv)]) docparts.update((row.title, row.part) for row in rows) # retrieve these relevant documents and score each one scores = {} for title, part in docparts: rows = db.session.execute(db.query_colbert_parts_stmt, [title, part]) embeddings_for_part = [tensor(row.bert_embedding) for row in rows] scores[(title, part)] = score(query_encodings, embeddings_for_part) # return the source chunk for the top 5 return sorted(scores, key=scores.get, reverse=True)[:5]
Aquí está la consulta que se ejecuta para la parte de los documentos más relevantes ( db.query_colbert_ann_stmt ):
SELECT title, part FROM colbert_embeddings ORDER BY bert_embedding ANN OF ? LIMIT 5
Más allá de lo básico: RAGStack
Este artículo y el repositorio vinculado presentan brevemente cómo funciona ColBERT. Puede implementar esto hoy con sus propios datos y ver resultados inmediatos. Como ocurre con todo lo relacionado con la IA, las mejores prácticas cambian a diario y constantemente surgen nuevas técnicas.
Para facilitar el mantenimiento de los últimos avances, DataStax está implementando esta y otras mejoras en RAGStack , nuestra biblioteca RAG lista para producción que aprovecha LangChain y LlamaIndex. Nuestro objetivo es proporcionar a los desarrolladores una biblioteca coherente para aplicaciones RAG que les permita controlar el avance hacia nuevas funciones. En lugar de tener que mantenerse al día con los innumerables cambios en técnicas y bibliotecas, tiene un flujo único, por lo que puede concentrarse en crear su aplicación. Puede utilizar RAGStack hoy para incorporar las mejores prácticas para LangChain y LlamaIndex listas para usar; Avances como ColBERT llegarán a RAGstack en próximos lanzamientos.
Por Jonathan Ellis, DataStax
También aparece aquí .
L O A D I N G
. . . comments & more!
. . . comments & more!



