






















Jan 01, 1970
974 Lesungen
Wie ColBERT Entwicklern hilft, die Grenzen von RAG zu überwinden
Zu lang; Lesen
Erfahren Sie mehr über ColBERT, eine neue Methode zur Bewertung der Passagenrelevanz mithilfe eines BERT-Sprachmodells, das die Probleme beim Abrufen dichter Passagen im Wesentlichen löst.
Retrieval Augmented Generation (RAG) ist mittlerweile ein Standardbestandteil generativer künstlicher Intelligenz (KI)-Anwendungen. Die Ergänzung Ihrer Bewerbungsaufforderung mit relevantem Kontext aus einer Vektordatenbank kann die Genauigkeit erheblich erhöhen und Halluzinationen reduzieren. Das bedeutet, dass eine steigende Relevanz in Vektorsuchergebnissen einen direkten Zusammenhang mit der Qualität Ihrer RAG-Anwendung hat.
Es gibt zwei Gründe, warum RAG weiterhin beliebt und zunehmend relevant ist, auch wenn große Sprachmodelle (LLMs) ihr Kontextfenster vergrößern :
Sowohl die Reaktionszeit als auch der Preis von LLM steigen linear mit der Kontextlänge.
LLM-Studenten haben immer noch Probleme mit der Recherche und Argumentation in großen Kontexten.
Aber RAG ist kein Zauberstab. Insbesondere das gebräuchlichste Design, Dense Passage Retrieval (DPR), stellt sowohl Abfragen als auch Passagen als einen einzigen Einbettungsvektor dar und nutzt direkte Kosinusähnlichkeit , um die Relevanz zu bewerten. Das bedeutet, dass DPR stark darauf angewiesen ist, dass das Einbettungsmodell über die nötige Schulung verfügt, um alle relevanten Suchbegriffe zu erkennen.
Leider haben Standardmodelle mit ungewöhnlichen Begriffen, einschließlich Namen, zu kämpfen, die in ihren Trainingsdaten nicht häufig vorkommen. DPR reagiert außerdem tendenziell überempfindlich auf die Chunking-Strategie, was dazu führen kann, dass eine relevante Passage übersehen wird, wenn sie von vielen irrelevanten Informationen umgeben ist. All dies stellt für den Anwendungsentwickler eine Belastung dar, „es gleich beim ersten Mal richtig zu machen“, da ein Fehler normalerweise dazu führt, dass der Index von Grund auf neu erstellt werden muss.
Lösen Sie die Herausforderungen von DPR mit ColBERT
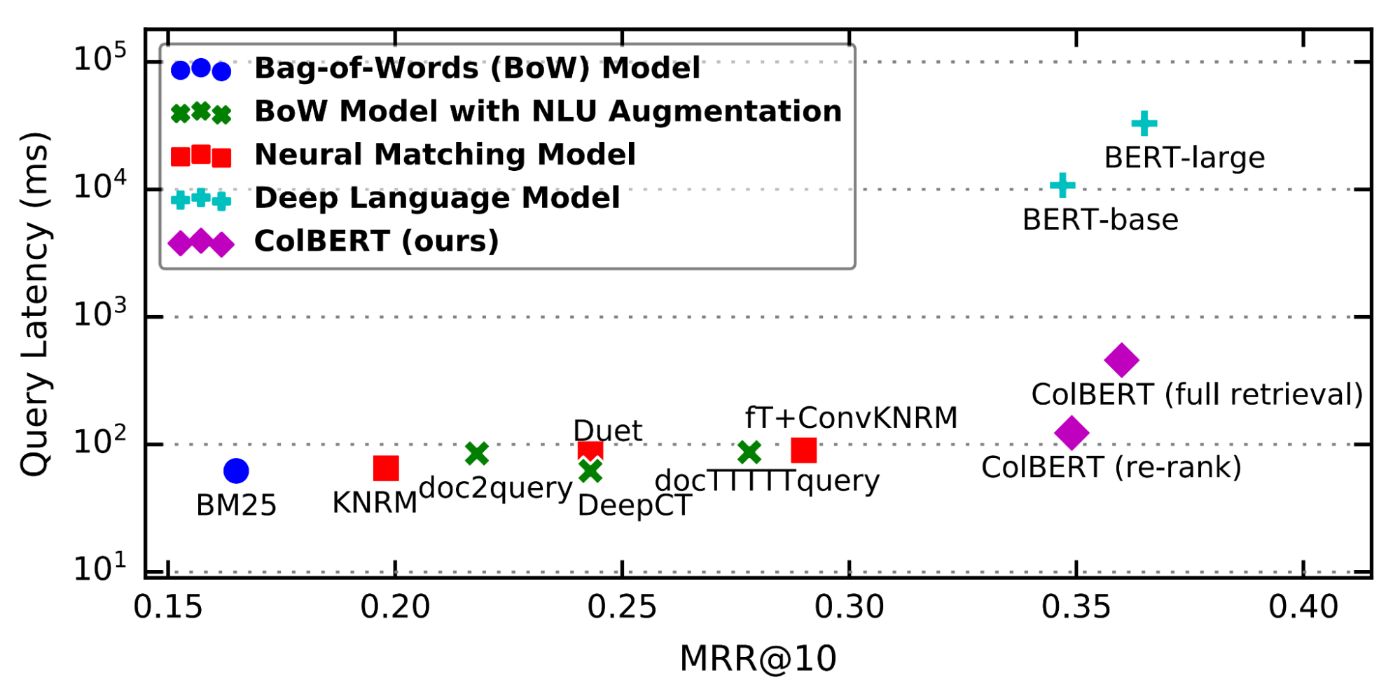
ColBERT ist eine neue Methode zur Bewertung der Passagenrelevanz mithilfe eines BERT- Sprachmodells, das die Probleme mit DPR im Wesentlichen löst. Dieses Diagramm aus dem ersten ColBERT-Artikel zeigt, warum es so spannend ist:
Dabei wird die Leistung von ColBERT mit anderen hochmodernen Lösungen für den MS-MARCO-Datensatz verglichen. (MS-MARCO ist eine Reihe von Bing-Abfragen, für die Microsoft die relevantesten Passagen manuell bewertet hat. Dies ist einer der besseren Abruf-Benchmarks.) Unten und rechts ist besser.
Kurz gesagt, ColBERT übertrifft das Feld der meist deutlich komplexeren Lösungen deutlich, allerdings auf Kosten einer geringfügigen Erhöhung der Latenz.
Um dies zu testen, habe ich eine Demo erstellt und über 1.000 Wikipedia-Artikel sowohl mit ada002 DPR als auch mit ColBERT indiziert. Ich habe festgestellt, dass ColBERT bei ungewöhnlichen Suchbegriffen deutlich bessere Ergebnisse liefert.
Der folgende Screenshot zeigt, dass DPR den ungewöhnlichen Namen von William H. Herndon, einem Mitarbeiter von Abraham Lincoln, nicht erkennt, während ColBERT den Hinweis im Springfield-Artikel findet. Beachten Sie auch, dass ColBERTs Nr. 2-Ergebnis für einen anderen William gilt, während keines der DPR-Ergebnisse relevant ist.
ColBERT wird oft im dichten Fachjargon für maschinelles Lernen beschrieben, ist aber eigentlich sehr einfach. Ich zeige, wie man den ColBERT-Abruf und die Bewertung auf DataStax Astra DB mit nur wenigen Zeilen Python und Cassandra Query Language (CQL) implementiert.
Die große Idee
Anstelle der herkömmlichen, auf einzelnen Vektoren basierenden DPR, die Passagen in einen einzigen „Einbettungs“-Vektor umwandelt, generiert ColBERT einen kontextbeeinflussten Vektor für jedes Token in den Passagen. ColBERT generiert auf ähnliche Weise Vektoren für jedes Token in der Abfrage.
(Tokenisierung bezieht sich auf die Aufteilung von Eingaben in Bruchteile von Wörtern, bevor sie von einem LLM verarbeitet werden. Andrej Karpathy, ein Gründungsmitglied des OpenAI-Teams, hat gerade ein herausragendes Video darüber veröffentlicht, wie das funktioniert .)
Dann ist die Punktzahl jedes Dokuments die Summe der maximalen Ähnlichkeit jeder Abfrageeinbettung mit einer der Dokumenteinbettungen:
def maxsim(qv, document_embeddings): return max(qv @ dv for dv in document_embeddings) def score(query_embeddings, document_embeddings): return sum(maxsim(qv, document_embeddings) for qv in query_embeddings)
(@ ist der PyTorch-Operator für Skalarprodukte und das gebräuchlichste Maß für Vektorähnlichkeit .)
Das ist alles – Sie können die ColBERT-Bewertung in vier Python-Zeilen implementieren! Jetzt verstehen Sie ColBERT besser als 99 % der Leute, die auf X (früher bekannt als Twitter) darüber posten.
Der Rest der ColBERT-Artikel befasst sich mit:
- Wie optimieren Sie das BERT-Modell, um die besten Einbettungen für einen bestimmten Datensatz zu generieren?
- Wie begrenzen Sie die Anzahl der Dokumente, für die Sie die hier gezeigte (relativ teure) Punktzahl berechnen?
Die erste Frage ist optional und nicht Gegenstand dieses Artikels. Ich werde den vorab trainierten ColBERT-Kontrollpunkt verwenden. Aber die zweite Möglichkeit ist mit einer Vektordatenbank wie DataStax Astra DB unkompliziert.
ColBERT auf Astra DB
Es gibt eine beliebte Python-All-in-One-Bibliothek für ColBERT namens RAGatouille ; Es wird jedoch ein statischer Datensatz vorausgesetzt. Eine der leistungsstarken Funktionen von RAG-Anwendungen ist die Reaktion auf sich dynamisch ändernde Daten in Echtzeit . Stattdessen werde ich den Vektorindex von Astra verwenden, um die Menge der Dokumente, die ich bewerten muss, auf die besten Kandidaten für jeden Subvektor einzugrenzen.
Beim Hinzufügen von ColBERT zu einer RAG-Anwendung gibt es zwei Schritte: Aufnahme und Abruf.
Einnahme
Da jedem Dokumentblock mehrere Einbettungen zugeordnet sind, benötige ich zwei Tabellen:
CREATE TABLE chunks ( title text, part int, body text, PRIMARY KEY (title, part) ); CREATE TABLE colbert_embeddings ( title text, part int, embedding_id int, bert_embedding vector<float, 128>, PRIMARY KEY (title, part, embedding_id) ); CREATE INDEX colbert_ann ON colbert_embeddings(bert_embedding) WITH OPTIONS = { 'similarity_function': 'DOT_PRODUCT' };
Nach der Installation der ColBERT-Bibliothek ( pip install colbert-ai ) und dem Herunterladen des vorab trainierten BERT-Checkpoints kann ich Dokumente in diese Tabellen laden:
from colbert.infra.config import ColBERTConfig from colbert.modeling.checkpoint import Checkpoint from colbert.indexing.collection_encoder import CollectionEncoder from cassandra.concurrent import execute_concurrent_with_args from db import DB def encode_and_save(title, passages): db = DB() cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0') cp = Checkpoint(cf.checkpoint, colbert_config=cf) encoder = CollectionEncoder(cf, cp) # encode_passages returns a flat list of embeddings and a list of how many correspond to each passage embeddings_flat, counts = encoder.encode_passages(passages) # split up embeddings_flat into a nested list start_indices = [0] + list(itertools.accumulate(counts[:-1])) embeddings_by_part = [embeddings_flat[start:start+count] for start, count in zip(start_indices, counts)] # insert into the database for part, embeddings in enumerate(embeddings_by_part): execute_concurrent_with_args(db.session, db.insert_colbert_stmt, [(title, part, i, e) for i, e in enumerate(embeddings)])
(Ich kapsele meine DB-Logik gerne in einem dedizierten Modul; Sie können auf die vollständige Quelle in meinem GitHub-Repository zugreifen.)
Abruf
Dann sieht der Abruf so aus:
def retrieve_colbert(query): db = DB() cf = ColBERTConfig(checkpoint='checkpoints/colbertv2.0') cp = Checkpoint(cf.checkpoint, colbert_config=cf) encode = lambda q: cp.queryFromText([q])[0] query_encodings = encode(query) # find the most relevant documents for each query embedding. using a set # handles duplicates so we don't retrieve the same one more than once docparts = set() for qv in query_encodings: rows = db.session.execute(db.query_colbert_ann_stmt, [list(qv)]) docparts.update((row.title, row.part) for row in rows) # retrieve these relevant documents and score each one scores = {} for title, part in docparts: rows = db.session.execute(db.query_colbert_parts_stmt, [title, part]) embeddings_for_part = [tensor(row.bert_embedding) for row in rows] scores[(title, part)] = score(query_encodings, embeddings_for_part) # return the source chunk for the top 5 return sorted(scores, key=scores.get, reverse=True)[:5]
Hier ist die Abfrage, die für den Teil mit den relevantesten Dokumenten ausgeführt wird ( db.query_colbert_ann_stmt ):
SELECT title, part FROM colbert_embeddings ORDER BY bert_embedding ANN OF ? LIMIT 5
Über die Grundlagen hinaus: RAGStack
Dieser Artikel und das verlinkte Repository stellen kurz vor, wie ColBERT funktioniert. Sie können dies noch heute mit Ihren eigenen Daten umsetzen und sofortige Ergebnisse sehen. Wie bei allem in der KI ändern sich die Best Practices täglich und es entstehen ständig neue Techniken.
Um es einfacher zu machen, mit dem neuesten Stand der Technik Schritt zu halten, integriert DataStax diese und andere Verbesserungen in RAGStack , unserer produktionsbereiten RAG-Bibliothek, die LangChain und LlamaIndex nutzt. Unser Ziel ist es, Entwicklern eine konsistente Bibliothek für RAG-Anwendungen zur Verfügung zu stellen, die ihnen die Kontrolle über die Umstellung auf neue Funktionen gibt. Anstatt mit den unzähligen Änderungen an Techniken und Bibliotheken Schritt halten zu müssen, verfügen Sie über einen einzigen Stream, sodass Sie sich auf die Erstellung Ihrer Anwendung konzentrieren können. Sie können RAGStack noch heute nutzen, um Best Practices für LangChain und LlamaIndex sofort zu integrieren; Fortschritte wie ColBERT werden in kommenden Versionen zu RAGstack kommen.
Von Jonathan Ellis, DataStax
Erscheint auch hier .
L O A D I N G
. . . comments & more!
. . . comments & more!