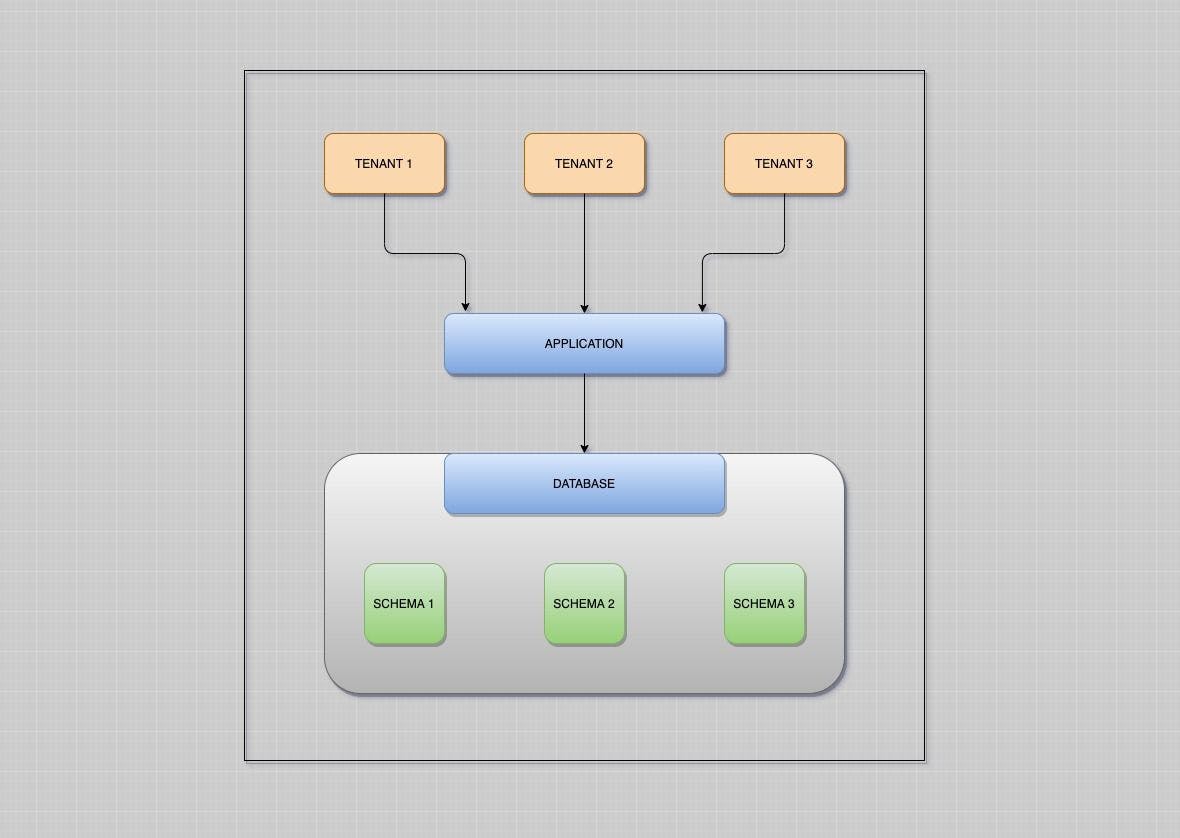
Before we dive into the main theme of this article, Let’s first talk a bit about what multi-tenancy is. As per Wikipedia, "The term “ software multi tenancy ” refers to a software architecture in which a single instance of the software runs on a server and serves multiple tenants. A tenant is a group of users who share a common access with specific privileges to the software instance." The most common use case for multi-tenant systems is SaaS-based applications, which use different levels of data isolation depending on the domain of the application. Let’s say, you have a product that you want to provide to several organisations, so that their users can login to the platform and use the service. The simplest solution would be to copy your codebase for each organisation and deploy them separately. It seems intuitive but hard to maintain as there is an overhead of managing multiple servers. Whenever your dev team needs to add a new feature, there needs to be a series of deployments to be followed. With a , this problem could easily be addressed resulting in a consistent codebase as now the team has to maintain only a single codebase. In line with our example, the tenants could be the organisations using our product. multi-tenant architecture There are several architectures that could be followed to achieve multi-tenancy at the database layer including: Separate database per tenant Separate schema per tenant Shared schema for tenants There are tons of articles available over the internet to help to understand the concept of multi-tenancy. Here we are going to talk about one specific type of multi-tenancy i.e. Schema-based Multi-Tenancy and how exactly PostgreSQL implements it. In this type of multi-tenancy, we create multiple schemas in the same database to provide data isolation to the tenants. At runtime, depending on the criteria to resolve the tenant, requests are redirected to the specific schema. There could be a number of ways to do it for example unique subdomains etc. Without much talking, let’s fire up the terminal and see how it works. Open the Postgres console psql postgres Create a new database using the command below CREATE database test; Check out the schema search path SHOW search_path; This search path determines which schemas will be looked upon to search a table or relation starting left to right and the result set will be returned based on the table which is found first. Now, let us create a new tenant or in Postgres terms a new schema. CREATE schema tenant_one; To switch to the new schema let us modify the schema search path. SET search_path TO tenant_one, public; Create a new table for users now CREATE table users (name varchar, age int); You can list the tables using the below commands. \dt This will list all the tables in the current schema. Ok now, let’s create another schema and switch over to it. CREATE schema tenant_two; SET search_path TO tenant_two, public; List the tables. \dt As you can see there are no tables here, you might be wondering where the users table we created earlier went. It resides under the schema tenant_one and currently our search path is set to search in tenant_two and public schema only. Let’s create a new table here as well. CREATE table users (name varchar, age int); Now, we should be able to see the users table. \dt Let us go ahead and create a new record in the users' table. Insert into users values (‘tenant_two user’, ); 21 List the record we just created. Select * users; from Modify the schema search path again and switch to tenant_one to get the list of users. SET search_path TO tenant_one, public; Select * users; from The record we created earlier is not shown since we updated the schema search path. Insert into users values (‘tenant_one_user’, ) Select * users; 22 from We should be able to get the list now. Feel free to update the schema path and play around. What happens if both the schemas are present in the search path? In this case, Postgres will give us the results from the schema in which the table is found first starting left to right. SET search_path TO public, tenant_one, tenant_two; Select * users; from As you can see, tenant_one’s user is the record list. Let’s modify the search path again and check the results. SET search_path TO tenant_two, public, tenant_one; Select * users; from This time tenant_two’s user shows up as the relation would be found in tenant_two first and the result set is returned. This was a basic idea of how schema based lookups are done. There are many libraries available which provide support to handle multiple tenants in your application. If you’re from the Ruby world, I highly recommend checking out the gem. You can specify whether you want to use Schema based multi tenancy or create a separate database per tenant depending on the underlying Database your application is talking to. Apartment Also published on: https://iamradioactive.medium.com/schema-based-multi-tenancy-with-postgres-3438a0403b2e