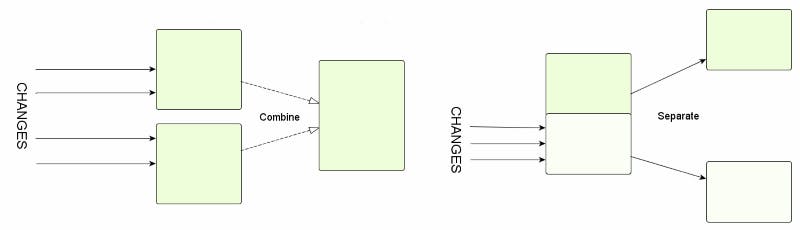
The Single Responsibility Principle is the key software engineering principle which determines how we should modularise code in object oriented programming. Formulated by Robert Martin and hammered home relentlessly by him over the years, the power of the principle and his efforts in promulgating it as the S of the SOLID group of principles have resulted in this being something that anyone who claims to know anything about software engineering will be familiar with. To save you looking it up on Wikipedia, its definition there is that a class should only have one responsibility, which is further defined by Martin as ‘one reason to change’ It’s been talked about in many contexts by many people, but I want to talk about what I see as a more and more common misapplication and misunderstanding of this principle. I was seeing people doing what is to me obviously bad structuring of their code and then justifying it as being in line with the SRP. This prompted me to research further to try and find out what was really going on, and this article is the result. The Symptoms To pick an example, if you look at on refactoring services, he is suggesting refactoring a class with two methods into two classes of one method each, so as to reduce the number of services injected into its constructor. He implies that this is a simplifying operation, in line with the SRP, when it increases the number of classes to manage as well as adding an interface, in the process of which he adds 7 lines of boilerplate code. There are many examples like this by many authors. this article by Mark Seeman A good example of the result of this in practice is described in . The author describes how the code base he is working on has become more difficult to understand and debug, how encapsulation has been destroyed by the need to make everything public in order for the class fragments to be able to communicate, and how using dependency injection has been made impractical by having to inject so many microscopic services in order to get any work done. this StackExchange question Those responding to this question suggest he’s not really understanding what the SRP really means, that he should use ‘common sense’, or bypass his actual problem to tell him he’s not using the SRP right because he has so many services to inject (ignoring the reason for this, that the services are so small). Intuitively, it seems to be wrong that our unit of organisation and encapsulation should be used to encapsulate a single method, or even one or two very short methods. In that case, why even bother with classes, and why not go back to procedural coding? I think it is fair to describe such a thin class as this as a code smell. In specific cases it might be justified but you need to be sure of why you would do this. To be fair to Mark Seeman, he may not be suggesting in practice that a class with a single method is a good idea, he may just be using a very simple example to get his point across. However it would be advisable to warn people of this as in the real world, the StackExchange example shows what happens when the wrong idea is got. But if you look at the SRP as described by Wikipedia and as it is usually quoted, getting down to one responsibility or one reason to change is only going to mean reducing the size of your classes. So it’s hardly surprising when we have a dominant software engineering principle that tells us to break up classes and no principle that balances this in the opposite direction, that code bases wind up fragmented. But is that really what the SRP says? The SRP is not a one-way street So where we are now is that in the software engineering world, people who are following the rules as given will think, you can’t have too small a class. This is what you could call a one-way street. There are a number of these trends in software engineering right now and I find them all worrying. Something I’ve noticed about these one way streets is that often when you go back to what the originator of the principle actually said, they are more nuanced and balanced than their disciples. So I went back to look in detail at what Robert Martin actually says. In many of his articles and YouTube lecture recordings he will illustrate what he means about ‘reasons to change’ with examples like a class for an employee which has methods for calculating and reporting pay, or a class which has data manipulation and data persistence operations. He also talks about a reason to change being related to a function in the business which is served by the software: in these cases the classes should be split up because the business function needing reports and the business function defining how salaries are calculated are different. On the face of it, he would seem to be saying that the SRP is just about where a class has functionality that belongs in two different layers or modules, it should be split. But when people who are claiming to follow the SRP show what they do with it, they are doing something more general, forgetting Martin’s explanation and using it to cut up any class that does ‘more than one thing’, like Mark Seeman. Things got clearer when I read in which Martin goes into what he is thinking in rather more depth than usual. In this he gives ‘another wording for the SRP’: this article Gather together the things that change for the same reasons. Separate those things that change for different reasons. It can’t be overstated how much has been left out by the loss of this ‘gather together the things that change for the same reasons’. I can only assume it has been lost because Martin and teachers of new coders like him have wanted to correct the naïve tendency to clump everything together into megaclasses, but haven’t seen such a need to teach the avoidance of atomisation. What was even more fascinating was the reference in Martin’s article to an which is an amazing piece of work, despite the level of technology having advanced considerably since when it was written. I highly recommend reading it. When I did it was clear where Martin was coming from in the original formulation of the SRP. academic article from 1972 The SRP is about limiting the impact of change This article talks about two separate ways of modularising a text processing system. The first was to modularise procedurally or as it says, according to a flowchart. In this structure, the modules are built so that the first passes its results to the second and so on. The second was to modularise the system according to likely sources of change. Any change required of a code system will naturally need changes to the body of the code at a number of different points. If the system is structured following the principle of ‘gather together those things that change for the same reasons’, you will minimise the number of modules (classes) that need to change. This allows you to hide the change as much as possible behind encapsulation boundaries, thus stopping the change cascading out into the rest of the system, and reducing what needs retesting because it might be broken. The article discusses in details the advantages of this second approach to modular structure. Martin describes the benefits of ‘separate those things that change for different reasons’. Two sections of code which change for different reasons held within the same encapsulation module have nothing to stop them being closely coupled and therefore in the example where a class has its feet in the UI and the business logic, a change to the UI could break the business logic. I’d add to this the simple but important advantage with regard to change that these rules of structure give is that they minimise the number of locations and different files you need to search for in the code in order to make your changes. Consideration of these two complementary rules provides us with the balanced criteria for separating code into classes (or modules) which we need to avoid code becoming atomised. Some different examples The hard thing to remember about the SRP is that it is based on likely patterns of change, not dependency or functional relationships within the code. Neither the internal structure nor the external function and requirements of the code are key, rather the nature of the business environment in which the code is undergoing change. Martin constantly makes reference to these factors when giving examples of use of the SRP however other commentators almost never do. If they don’t, they are doing something which isn’t using the SRP. A classic example used by Martin himself and others is the Active Record pattern. In this pattern, a class contains properties for the fields in a database record plus persistence-related actions like GetFromId, Save etc. This is always cited as a violation of the SRP. However it depends on the context. If for whatever reason, you are not using object-relational mapping, and the same developers are controlling the code and the database, the Active Record pattern has advantages under the SRP. This is because a very common form of change is the addition, alteration, or removal of fields from what is stored in the database. The Active Record encapsulates all concerns relating to the storage of the data it holds. It makes it easy to hide the relationship between the externally exposed data and the internal database structure from the rest of the program. If you use some alternatives, for instance some kind of Mapper class which also has to know about the record fields, this causes the impact of a change like the addition of a field to be spread. Another example which would appear to be against the SRP from a naïve point of view, is the location of all service construction and initialisation of an application which uses dependency injection in one class. Any change in the service injection requirements of a class will imply a change here. This is certainly a class that is doing more than one thing in a naïve interpretation. However it follows the SRP because configuration changes are generally clustered together. For instance, changing the identity management system on a website would require a group of related changes to what services were registered in the IoC container. Conclusion The SRP is a widely quoted justification for refactoring. This is often done without full understanding of the point of the SRP and its context, leading to fragmentation of code bases with a range of negative consequences. Instead of being a one-way street to minimally sized classes, the SRP is actually proposing a balance point between aggregation and division. The next article in the series on the Open/Closed Principle is at . https://hackernoon.com/why-the-open-closed-principle-is-the-one-you-need-to-know-but-dont-176f7e4416d