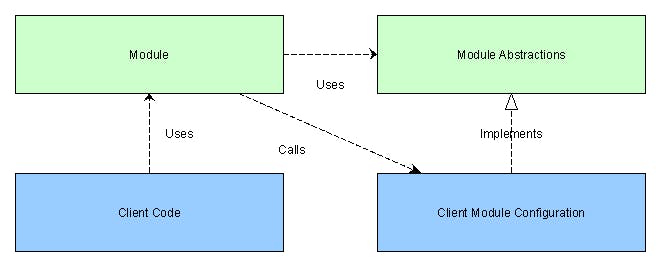
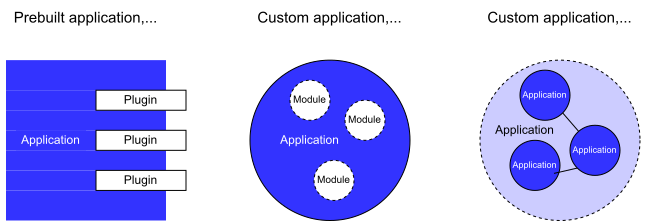
Because it’s definition is poorly phrased, the Open/Closed principle is probably the most misunderstood of the 5 SOLID principles. However it’s the one which when properly applied can save you more development effort through good architecture than any of the others. The principle as originated by Bertrand Meyer states: software entities (classes, modules, functions, etc.) should be open for extension, but closed for modification Later, when he included it in his SOLID principles, Bob Martin expressed it better: You should be able to extend the behavior of a system without having to modify that system. What this is about is best understood in the context of writing a software package or library which is used by many third parties. Essentially you want this library to be used in the widest variety of likely contexts by its consumers (open for extension), however you want to change it as little as possible, because every time you do you’re obliging your consumers to update their versions and in the worst case, fix the consequences of breaking changes. Also, this helps with reliability because ideally over time the code will become more and more well tested by use in many contexts, and less and less frequently changed so less liable to be broken by those changes. The same applies to a lesser extent to when you write code in one place in your application which is used elsewhere: if you can adapt it to different purposes by writing new code that is better than modifying it because modifying it will likely cause changes to need to be made everywhere it is used. You can see that this second principle is like the Single Responsibility Principle about minimising the consequences of future changes to your code. And just like the SRP, the way you follow this principle in practice is determined by an educated guess about how the requirements on your software are likely to change in future. In the SRP you make a judgement about decomposition and where to draw encapsulation boundaries in your code. In the OCP, you make a judgement about what in your module you will make and leave to your module’s consumers to make concrete, and what concrete functionality to provide yourself. abstract As with the SRP, this cannot be a one way street where you must write code that could never need to be modified and can always be extended. The only code that could never need to be modified is a class such as below: public class TotallyAbstract<TArg, TRes>{private Func<TArg, TRes> f; public TotallyAbstract(Func<TArg, TRes> f){this.f = f;} public TRes Apply(TArg a){return f(a);}} You’ll notice that it actually has no functionality whatsoever! Here is the opposite: you can only get it to do one thing ever and you’d have to modify it to do anything else: public class TotallyConcrete{public int Apply(){return 2 + 2;}} Any sensible module must lie in between these extremes: to do something useful it has to be partially concrete, however to be used in a range of contexts it must be partially abstract. So don’t get the extremist idea that your code should never be changed only extended! A function or program can have its functionality varied by the parameters and configuration data which it receives. The Open Closed Principle doesn’t seem to be talking about this kind of adaptation of functionality when it speaks of ‘extension’, though. This sounds like writing code not data: however the line between the two is always blurred to a greater or lesser extent. Configuration of a module can be done using data files or code. It’s part of simple programming to call functions with parameters. However, extending code with other code is more advanced. This however is possibly the most important skill to learn as a programmer, because it enables you to write less code! It does this by letting you use the same code in a wider variety of contexts. The skill here is not just in writing code which can be extended easily but also in seeing the opportunity to do so. A very powerful example of this way of working is the plug-in architecture. A classic use for this is in image editors where you can plug in filters made by third parties. The image editor knows nothing specific about any of the filters: it has a contract which is an abstraction which defines the minimum requirements for a piece of code to be used as an image filter, then it makes no further assumptions about the plugins except that they fulfil this contract. This allows the image editor without any of its code being changed to have its functionality extended by other code. Bob Martin writes about this here: . https://8thlight.com/blog/uncle-bob/2014/05/12/TheOpenClosedPrinciple.html This is of course an example of dependency inversion, the D in SOLID. In fact all extension of a module with code is a form of dependency inversion: the difference is in what kind of abstraction you use to specify the dependency which will be injected: The module has parameters in its API which allow functions to be passed in and executed in the context of the module’s operation to specify or modify its function. This is underused in object oriented programming in my view, and provides a clear and simple way to inject code which works best where this function has no need to be reused in other contexts, and is not naturally grouped with a set of related functions as in a class. Function parameters (no data) Similar to the above, except the code which is injected into the module is now in the form of a class which groups together custom methods and possibly data. This is the most recommended approach in object oriented programming, however providing a single function is simpler if appropriate, and a point usually missed is that interfaces, unlike base classes, give the module writer no chance to restrict and control how any of the functionality is provided, which could cause issues. Totally abstract class parameters (interfaces or fully abstract base classes) The client code uses class inheritance to create a subclass which inherits data and some methods from a parent class in the module, adding or changing some methods and adding data as required. Nice to use where there is a hierarchy of more specialised related classes, it can get complicated to manage and so is discouraged by many writers. Partially abstract class parameters (implementation inheritance) In fact there’s not a lot of difference between these in fundamental terms, they are all different ways of injecting client code into the module. In a functional language, you only have the first. In an object oriented language, you have all three (the first may be more or less awkward to do depending on how well function variables are implemented). Hopefully this article provides some pointers as to looking again at the way you close your code against the need to change and open it to be adapted and reused, as success in this area can reap great dividends in maintainability and efficiency. The previous article in this series on the Single Responsibility Principle is at . https://hackernoon.com/you-dont-understand-the-single-responsibility-principle-abfdd005b137 The next article in this series on the Liskov Substitution Principle is at . https://medium.com/@jim_ej/the-liskov-substitution-principle-and-why-you-might-want-to-enforce-it-6f5bbb05c06d Twitter: @jim_ej