
214 reads
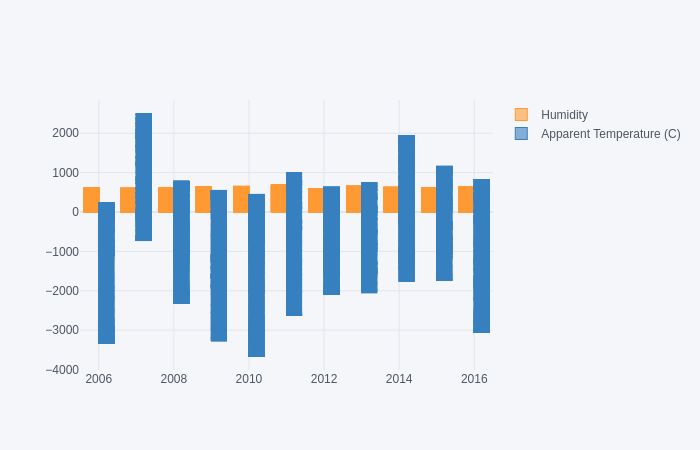
Visualization of Hypothesis on Meteorological data
by byKAVISH GOYAL@kavish
byKAVISH GOYAL@kavish
Self Taught Machine Learning Engineer and Data Scientist.Love Data driven problem and AI,ML and DS.
October 16th, 2020





Self Taught Machine Learning Engineer and Data Scientist.Love Data driven problem and AI,ML and DS.


Self Taught Machine Learning Engineer and Data Scientist.Love Data driven problem and AI,ML and DS.
About Author

Self Taught Machine Learning Engineer and Data Scientist.Love Data driven problem and AI,ML and DS.
Comments










![10 FinTech Trends in 2021 [Part II]](https://firebasestorage.googleapis.com/v0/b/hackernoon-app.appspot.com/o/images%2F3nhao37bBEfHA9RTQ0WNVWfXPD02-ern31d7.jpeg?alt=media&token=f48ef9e5-ec15-4bfe-93cf-9a84dfb77f84&auto=format&fit=max&w=3840)






