
3,399 reads
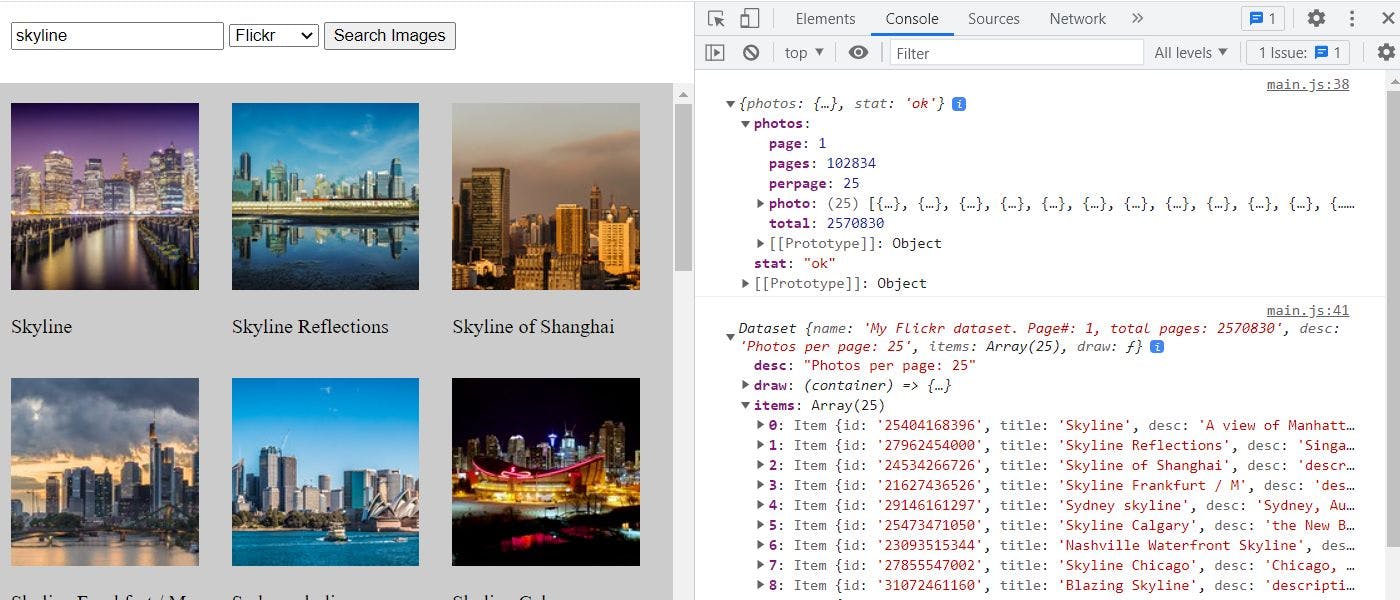
Using JSON Mapping to Work with APIs of Various Image Services
by
December 2nd, 2021





Audio Presented by



About Author

Software Developer
Comments

TOPICS





Related Stories












10 Threats to an Open API Ecosystem
Jul 18, 2022
Software Developer
Jul 18, 2022
Jul 18, 2022