




17,081 reads
Unlocking Azure: How to Build a Highly Flexible SQL Database Infrastructure
by Social Discovery GroupOctober 9th, 2023



















Too Long; Didn't Read
SDG tips on making SQL database infrastructure in Azure as flexible, efficient, and reliable as possible.

It’s not a secret that in recent years Infrastructure as a Service and Platform as a Service have become increasingly widespread on various projects due to their capabilities, particularly resource efficiency and flexibility. As a result, Microsoft spent a lot of time and effort creating a user-friendly environment in which SQL can be used.
Social Discovery Group team uses a variety of databases including SQL to power our products. With a portfolio of 40+ global services that help to meet and connect worldwide, our user base includes over 250 million people across the globe. To guarantee the reliability of our products for the users, we keep part of the key infrastructure in the cloud. This helps to enhance its resilience, security, and flexibility.
We’re quite experienced in deploying server and service databases on various platforms, including Kubernetes clusters. However, we faced the need to make a part of the related SQL databases infrastructure in the Azure cloud as flexible, efficient, and reliable as possible. There are 3 ways to use SQL in the Microsoft Azure cloud:
- Azure SQL Database
- Azure SQL Managed Instance
- SQL Server on Azure Virtual Machines
After the research, we’ve decided to use Azure SQL databases. Just to clarify for those who have never heard of so-called Azure SQL databases, they are managed cloud databases provided as part of Microsoft Azure.
I have highlighted the following benefits:
- There is no need to worry about updates or end-of-life support;
- Easy configuration and deployment;
- Speed of deployment (and therefore development) and scalability;
- High availability;
- Fault tolerance;
- Ease of backup;
- Cost optimization;
- An integrated Microsoft Azure monitoring system.
Now let's talk about things step by step and take a look at the process of deploying and creating a database. This can be done using a Power Shell script or the Azure CLI, but for the sake of clarity, I look at the process using the portal's graphical interface. To do this, go to Azure SQL, click 'Create', and select 'SQL Databases'.




We specify the resource group, select whether there is an existing server or create a new one (indicating the administrator’s name and data), and come up with a name for the database. I’d recommend choosing DTU (database transaction unit) based bundled packages with a balanced mix of compute and storage resources for our common workloads.


There are also some tabs for settings: Network, Security, Additional settings, and Tags; for a minimum standard configuration, these can be left unchanged by default. Then we wait for the database to be created. This completes the minimum setup, and the base is done.


The size of the database resources can be changed super easily, literally with a click, and in case of insufficient resources, we can set the parameters we need in terms of size and performance.
Then you can connect to your database in any way you prefer from the outside, without forgetting to add your IP address or subnet, or to allow all connections in the firewall of the server on which this database is hosted.


It’s convenient to connect and further manage through SQL Server Management Studio (SSMS), but it is also possible to do so through other tools and the Azure portal itself.
In addition to a public connection point, you can also create a private one by adding a server to the required subnet and configuring private DNS zones.
Speaking about fault tolerance, here we see a very convenient and intuitive implementation of failover, a group of protecting servers based in different regions.


In Azure, it’s possible to add and remove databases on servers in a failover group, forced failover, and automatic failover mode.


You can see this in the screenshot below. Let's come up with a name for the failover group and put the server into failover. Synchronization of the specified databases will start automatically. The second server will be in read-only mode. In the event of a failure, traffic is automatically switched to the second region, and the primary and secondary servers automatically switch places.




But failover will not help if there is a data-level problem in the databases themselves. For sure in this case, you need to create backups. It’s possible to configure backups both within the portal and through third-party tools or, for example, Azure DevOps (in the pipeline you can use the SqlAzureDacpacDeployment + AzureFileCopy task). Within the portal, backups are configured on the Backups tab and the necessary storage policies are set.
If you prefer to use third-party backup tools, I would recommend considering Azure DevOps or SQL package tools.

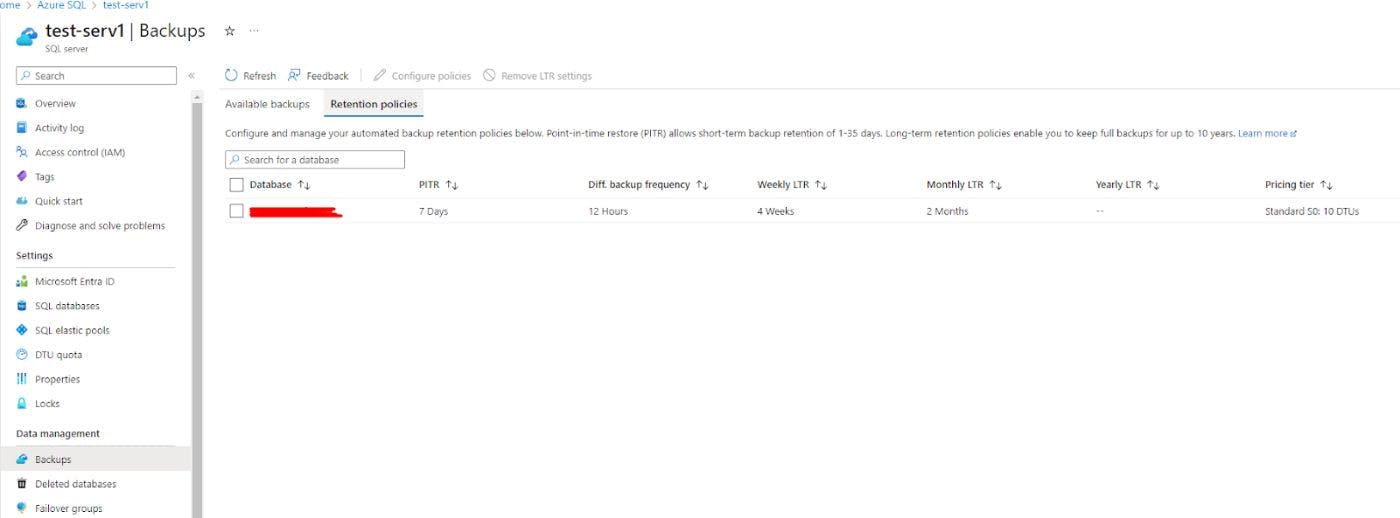
The recovery process on the portal itself is not very convenient in my opinion. The first thing you notice is the long recovery time for simple test databases. For example, it took me more than half an hour to restore a 30MB basic-size database from yesterday's backup! After contacting Microsoft Azure support, I was advised to use PowerShell scripts for recovery and notified that the database size should be at least S3 for the recovery process, and later the size could be reduced. Below I’m going to present some of my scripts and developments on this subject, they can be improved and enhanced but I am sure many of you can find them useful.
I'll take you step by step:
- In case you don't have PowerShell ISE installed on Windows, download it here:
https://github.com/PowerShell/Pohell/releases/download/v7.3.0/PowerShell-7.3.0-win-x64.msi https://github.com/PowerShell/PowerShell/releases/download/v7.3.0/PowerShell-7.3.0-win-x86.msi - Next, you need to install the Azure module: Install-Module Az
- After installing the AZ module, import the AZ module: Import-Module Az
- Once imported, you can connect to your Azure account: Connect-AzAccount. A popup will appear to log into your Azure account, then you will be connected
- Run the PowerShell script itself.
“ #Variables in use
$Database = Get-AzSqlDatabase -ResourceGroupName "Test" -ServerName "test-serv1" -DatabaseName "dbforscript"
$TargetDB = "dbforscript_new"
$PITRtimedate = "2022-12-02 10:00:00Z" ##вам нужно увидеть действительную дату и время на портале
$PITRSLO = "S3"
$PITRNEWSLO = "S0"
$PITRedition = "Standard"
$failoverGroupRG = "Test"
$failoverGroupS = "test-serv1"
$failoverGroupDB = "dbforscript"
$removedbfromfgRG = "Test"
$removedbfromfgS = "test-serv1"
$removedbfromfgDB = "XXXXX"
$dropreplicaRG = "Test"
$dropreplicaS = "test-serv2"
$dropreplicaDB = "dbforscript"
$sourcedbRG = "Test"
$sourcedbS = "test-serv1"
$sourcedbDBname = "dbforscript"
$sourcedbDBNEWname = "dbforscript_old"
$TargetDBNEWname = "dbforscript" “
1 - This code initiates a database restore with a different name. If the original name of the database being restored is "dbforscript", then the name of the restored database will be dbforscript_new. The restored database will be SLO version S3 or higher, which is the recommended way to perform this action, the variable for this is $PITRSLO = "S3", you can use S3 or higher. After this we will reset the SLO level to the original one, this is for recovery only.
“Restore-AzSqlDatabase -FromPointInTimeBackup -PointInTime $PITRtimedate -ResourceGroupName $Database.ResourceGroupName -ServerName $Database.ServerName -TargetDatabaseName $TargetDB -ResourceId $Database.ResourceID -Edition $PITRedition -ServiceObjectiveName $PITRSLO”
2 - This code will remove the source database from the failover group: source database: dbforscript.
“$failoverGroup = Get-AzSqlDatabase -ResourceGroupName $failoverGroupRG -ServerName $failoverGroupS -DatabaseName $failoverGroupdb | Remove-AzSqlDatabaseFromFailoverGroup -ResourceGroupName $removedbfromfgRG -ServerName $removedbfromfgS -FailoverGroupName $removedbfromfgDB”
3 - This code will remove the replica database from the server where it is located: dbforscript on the test-serv2 server.
“Remove-AzSqlDatabase -ResourceGroupName $dropreplicaRG -ServerName $dropreplicaS -DatabaseName $dropreplicaDB”
4 - This code will rename the original database to a different name: after the renaming, dbforscript will be dbforscript_old.
“Set-AzSqlDatabase -ResourceGroupName $sourcedbRG -DatabaseName $sourcedbDBname -ServerName $sourcedbS -NewName $sourcedbDBNEWname”
5 - This code will rename the restored database to the original database name, renaming dbforscript_new to dbforscript.
“Set-AzSqlDatabase -ResourceGroupName $Database.ResourceGroupName -DatabaseName $TargetDB -ServerName $Database.ServerName -NewName $TargetDBNEWname”
6 - This code will return your database SLO level to the previous (original) S0 value. if your database is basic, please you can upgrade from S0 to basic after in the portal.
“Set-AzSqlDatabase -ResourceGroupName $Database.ResourceGroupName -DatabaseName $TargetDBNEWname -ServerName $Database.ServerName -Edition $PITRedition -RequestedServiceObjectiveName $PITRNEWSLO -MaxSizeBytes 10737418240”
7 - The last code adds the restored database to the failover group, which already has the original name (since we changed it in the previous code).
“$failoverGroup = Get-AzSqlDatabase -ResourceGroupName $failoverGroupRG -ServerName $failoverGroupS -DatabaseName $TargetDBNEWname | Add-AzSqlDatabaseToFailoverGroup -ResourceGroupName $failoverGroupRG -ServerName $failoverGroupS -FailoverGroupName $removedbfromfgDB”
You can consider adding the - ErrorAction Stop parameter after the command. This will prevent the following commands from being executed in the event of an error, and there will be no snowballing.
Also, you can add Get-Date at the beginning and end of the script to calculate the execution time. In my case, a database of about 3.3 GB was restored by such a script in less than 6 minutes.
If you wish, you can surely optimize the script, add it via Azure DevOps, reduce the number of variables, or hardcode something, but I have tried to describe it in as much detail as possible and in a way that everyone can understand.
Database monitoring on Azure and the ability to integrate with various systems, such as Datadog, deserves special attention. Monitoring is quite convenient, but not without nuances (at the time of writing, for example, read-only users could only see monitoring for one database, not all at once... well here are the shades).
In conclusion, our team has successfully optimized expenses while also addressing concerns related to updates and support discontinuation. We achieved improvements in performance, resilience, development speed, and flexibility. Additionally, the implementation of scripts has notably enhanced our ability to recover swiftly when needed.

L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
TOPICS
Languages












THIS ARTICLE WAS FEATURED IN...



RELATED STORIES



AI Tools for Video Ads: 3 Hands-On Techniques #ai
Jan 22, 2024




Top 10 AI Development Companies in USA #future-of-ai
Mar 06, 2023

