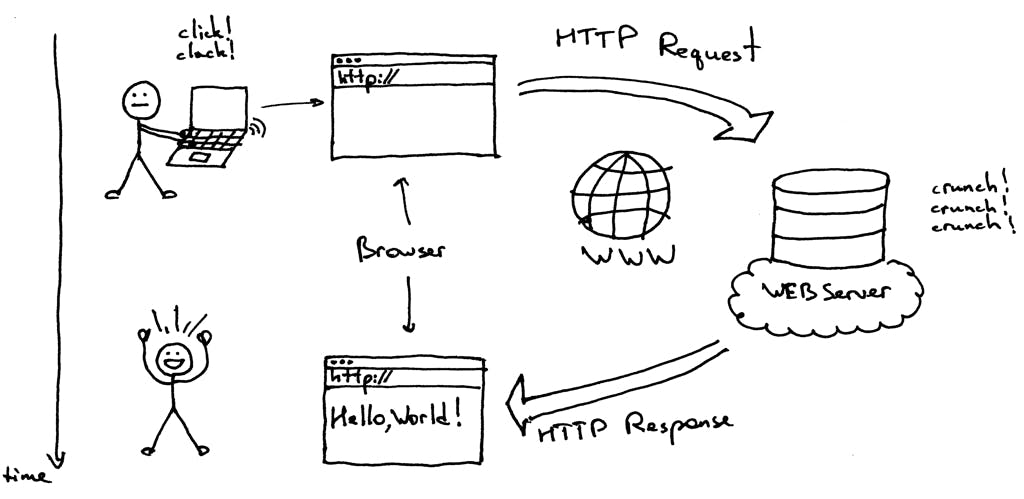
It’s easy to take the intricacies of the web for granted as we seamlessly browse through various websites daily. We enter a URL into our browser, and within seconds, a whole website appears. But have you ever stopped to wonder about the technology and processes that make this possible? This article delves into the various components and technologies that make the seemingly effortless experience of accessing the web a reality. Also, You don’t need to know how the web works to write code. But it will help you to understand the whole system. What happens when we try to access a website We know our website’s code is not stored on our computer. We need to get the code into our computer or browser where it is kept to visit the website. How does this happen? The process is quite simple. When we enter a URL into our browser, the browser sends a request for the necessary data to the server. The server then responds by sending back the code and data for the website. The browser interprets the codes and displays the website for us to view. This process is known as the model or client-server architecture. request-response What are clients and servers? Clients are those devices connected to the internet, like our phones or computers connected to the mobile network or wi-fi. The client is where all the user interaction happens. In the web’s context, a client is typically a web-accessing software like a browser, such as Chrome, Firefox, or Safari, that requests web pages and other resources from a server. The client (web browser) receives the code for the website and then renders it for the user to view. Though we access the website from the browser, we can treat the whole device as a client of the client-server architecture. On the other end of the spectrum are Servers, specialized computers designed to store and manage data, websites, and web applications. These servers are called such because they serve up code or data in response to requests made by clients. A server waits for requests to come in from clients, processes the request, and then sends back the requested information. There are various types of servers, such as web servers, file servers, and database servers, each with its specific function. In this article, we will focus on web servers primarily. What is a URL, and how does it get resolved? A URL (Uniform Resource Locator) is a string of characters that specifies the location of a resource on the internet. URLs are used to identify and locate web pages, images, videos, and other resources on the World Wide Web. URLs typically contain several parts, including a protocol, domain name, and path. The protocol is the method used to transfer data over the internet. The most common protocol used for the web is HTTP (Hypertext Transfer Protocol) or HTTPS (HTTP Secure), a more secure version of HTTP that encrypts data for added security. The domain name is the unique name that identifies a website or web server on the internet. To access a website, the name is typed into the browser’s address bar. For example, “github.com” is the domain name of Github’s website. The path indicates the location of the resource within the server. This URL part usually includes the file name or folder containing the resource, such as “about” or “contact.” For example, “github.com/about” is the path for the about page of the website “github.com.” Optionally, the URL may also include a query string, a set of characters added to the end of the URL that contains additional information or parameters for the resource. It’s interesting to note that the domain name we enter into the browser is not the actual physical address of the website. Every website and device connected to the internet has a unique IP address, a numerical label that is often difficult to remember. To make it easier to remember, we use domain names. When an URL is entered, the browser first sends a request to the DNS (Domain Name System) server, which matches the domain name to the corresponding IP address of the website. This is called DNS Lookup. This process is facilitated by your internet service provider and returns the IP address, including the port number of the server being accessed. Establishing protocols When we enter a web address and get the actual IP address of the website in the browser, a connection known as a TCP/IP socket is established between the browser and the server. This connection remains active while files are being transferred from the server to the client. TCP (Transmission Control Protocol) and IP (Internet Protocol) are two of the main protocols that make up the internet protocol (IP) suite. Together, they provide the foundation for communication on the internet. TCP (Transmission Control Protocol) is one of the core protocols of the internet protocol suite (TCP/IP), which is used to establish and maintain connections between devices on a network. The primary function of TCP is to ensure the reliable delivery of data between devices. TCP breaks down data into small chunks called packets before they are sent over the network. Each packet is labeled with a TCP header, which includes the source and destination port numbers, and an IP header which consists of the source and destination IP addresses, to identify it. Each packet also contains a sequence number that allows the receiving device to reassemble the packets in the correct order. If a packet is lost or corrupted during transmission, TCP will automatically retransmit the packet to ensure that all packets are received correctly. This protocol also provides flow control and congestion control. Flow control ensures that the sender does not overwhelm the receiver by sending too much data at once, and congestion control ensures that the network does not become overloaded by too much traffic. It is a connection-oriented protocol that establishes a virtual connection between the sender and receiver before exchanging any data. Once a connection is established, both parties can exchange data in a reliable and orderly manner. TCP is widely used in many applications, including web browsing, email, file transfer, and online gaming. It is a reliable and efficient protocol that ensures data is delivered correctly and in the right order, making it an essential part of the internet infrastructure. On the other side, IP addresses and routes packets between devices on a network. It assigns a unique IP address to each device connected to the internet. When data is sent from one device to another, the IP protocol determines the destination address and the best route for the data to take. Its job is to send and route all the packets through the internet. TCP and IP work together to provide reliable, efficient communication on the internet. IP addresses and routes data packets, while TCP ensures that the data is delivered correctly and in the proper order. These are communication protocols or the internet’s fundamentals control system that defines and sets the rules for how data travels across the web. Communication Protocol sets the rules for how two or more parties communicate within them. Once the connection is established, the communication process begins with an HTTP request sent from the browser. HTTP, or Hypertext Transfer Protocol, is the standard protocol for transmitting data over the internet and is the backbone of the World Wide Web. It enables the browser to send requests to a web server and receive the server’s response. HTTP is based on a request-response model we discussed before, in which a client (such as a web browser) sends a request to a server, and the server sends a response. HTTP Request has a few parts, which include the start line(HTTP method + request target + HTTP version), HTTP request header, and request Body. The most common HTTP methods are GET, which requests a resource from the server, and POST, which sends data to the server to be processed. There are also PUT and Patch methods that are used to modify data. HTTP sits on top of the TCP/IP protocol stack. It’s usually used with the SSL/TLS (Secure Sockets Layer/Transport Layer Security) protocols to provide secure and encrypted communication over the internet. When the server receives the request, it processes it and sends back an HTTP Response. The HTTP Response is composed of several parts: The start line includes the HTTP version, status code, and message. The HTTP version indicates which version of the HTTP protocol is being used. The status code is a three-digit numerical code that indicates the outcome of the request. The status message is a brief text description of the status code. The HTTP response header contains additional information about the response, such as the type of content in the response body, the date and time the response was sent, and the server’s name. The response body contains the actual data or HTML file that was requested. The backend developer is responsible for specifying the data included in the response header. This data can include things like the content type, date and time, and server name. In the response body, we get the data or HTML file requested in the original request. If the server cannot locate the requested page, it will send an HTTP 404 error message indicating that the page could not be found. What happens next after our browser receives the response? When a web browser receives an HTML (Hypertext Markup Language) document from a web server, it parses the document to convert it into a visual representation that can be displayed to the user. The process of parsing an HTML document involves the following steps: The browser begins by reading the HTML code from top to bottom, line by line. As it reads through the code, the browser looks for tags, which are used to define the structure and layout of the document. For example, the <html> tag indicates the start of an HTML document, and the <head> and <body> tags indicate the beginning of the head and body sections of the document, respectively. The browser understands how to interpret the code by an HTML parsing algorithm. As the browser encounters tags, it creates corresponding elements in the Document Object Model (DOM), a tree-like representation of the HTML document. The browser uses it to understand how the page should be rendered and displayed. Each element in the DOM corresponds to a single tag in the HTML code, and we can manipulate those elements by scripting language like JavaScript. The browser scans the document for additional assets to render the page correctly. These assets can include CSS files, JavaScript files, images, and other multimedia files. When the browser encounters a reference to an asset in the HTML document, it will send an additional request to the server to retrieve that asset. The browser will repeat this process for each asset that it encounters. For example, if the HTML document links. For a CSS file, the browser will request the server to retrieve that file. The CSS file will then be parsed and used to apply the visual styles to the elements defined in the HTML. Similarly, if there are images on the page, the browser will send a request to the server for each image and render them on the page. It’s important to note that the browser will only download and parse the assets necessary for the current viewport or the visible part of the webpage. This is called Lazy Loading. As the user scrolls down the page, the browser will download and parse additional assets as they are needed. This downloading and parsing of additional assets can impact the web page’s performance, as it can take time to retrieve and process these files. Therefore, developers need to optimize the loading of these assets to ensure that the page loads quickly and efficiently. It’s important to understand that HTML doesn’t provide information on how a website should appear visually. It only defines the structure and tells the browser the different parts of the content, like headings, images, and paragraphs. CSS (Cascading Style Sheets) provides visual styling and presentation information for a web page. CSS allows developers to specify the font, color, size, and position of elements on a web page, as well as other visual properties. CSS can be linked to an HTML document and will be used to apply the styles to the elements defined in the HTML. The browser also uses JavaScript to add dynamic functionality to web pages, like form validation and interactive elements. Once the parsing process is complete, the browser renders the visual representation of the HTML document, which the user can interact with and view in the browser window. The parsing process is complex, but it is done quickly and efficiently by modern web browsers, allowing users to interact seamlessly with web pages. After parsing everything, the connection gets closed. This is it for now! However, many other complex processes and technologies make the internet function. This article should give you an overview of the essential parts of the web, but keep in mind that there is much more to learn and explore in the field of the web. Also published here. If you enjoyed reading this, feel free to connect with me on or check out my . Twitter other articles Happy Learning!