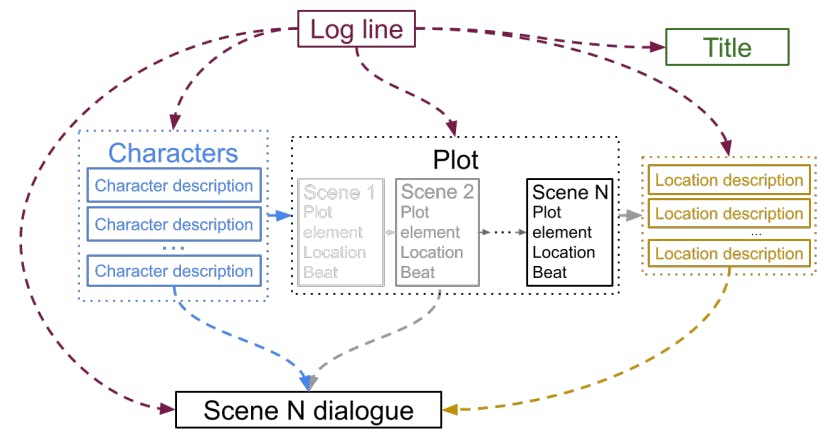
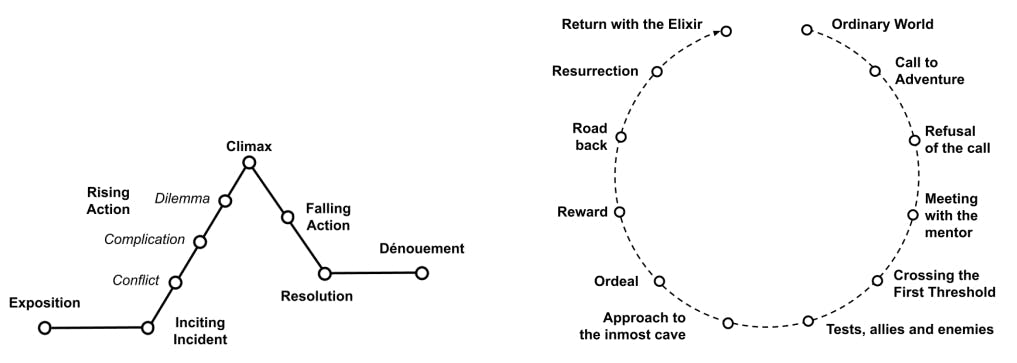
From teleplay to technology, we weave a narrative tapestry that dances between writing, CGI, and "action!"
Story's Credibility


From teleplay to technology, we weave a narrative tapestry that dances between writing, CGI, and "action!"
Story's Credibility
About Author

From teleplay to technology, we weave a narrative tapestry that dances between writing, CGI, and "action!"
Comments