290 reads
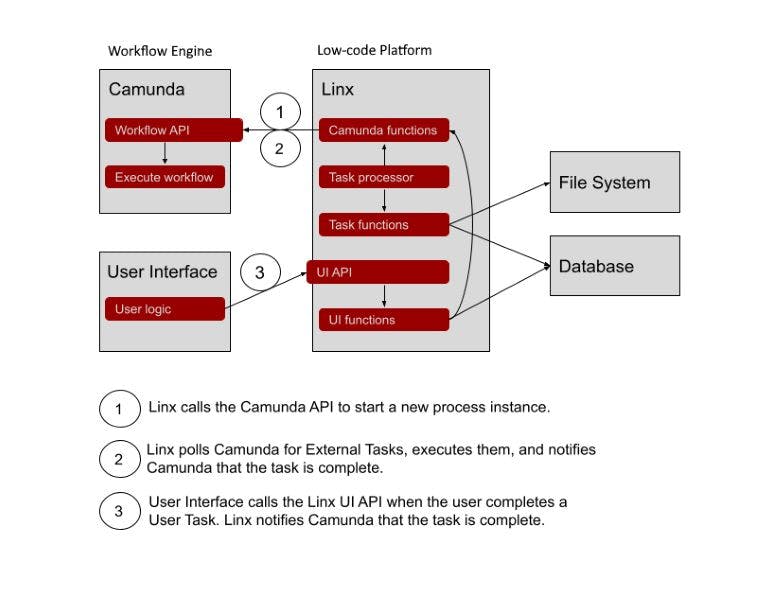
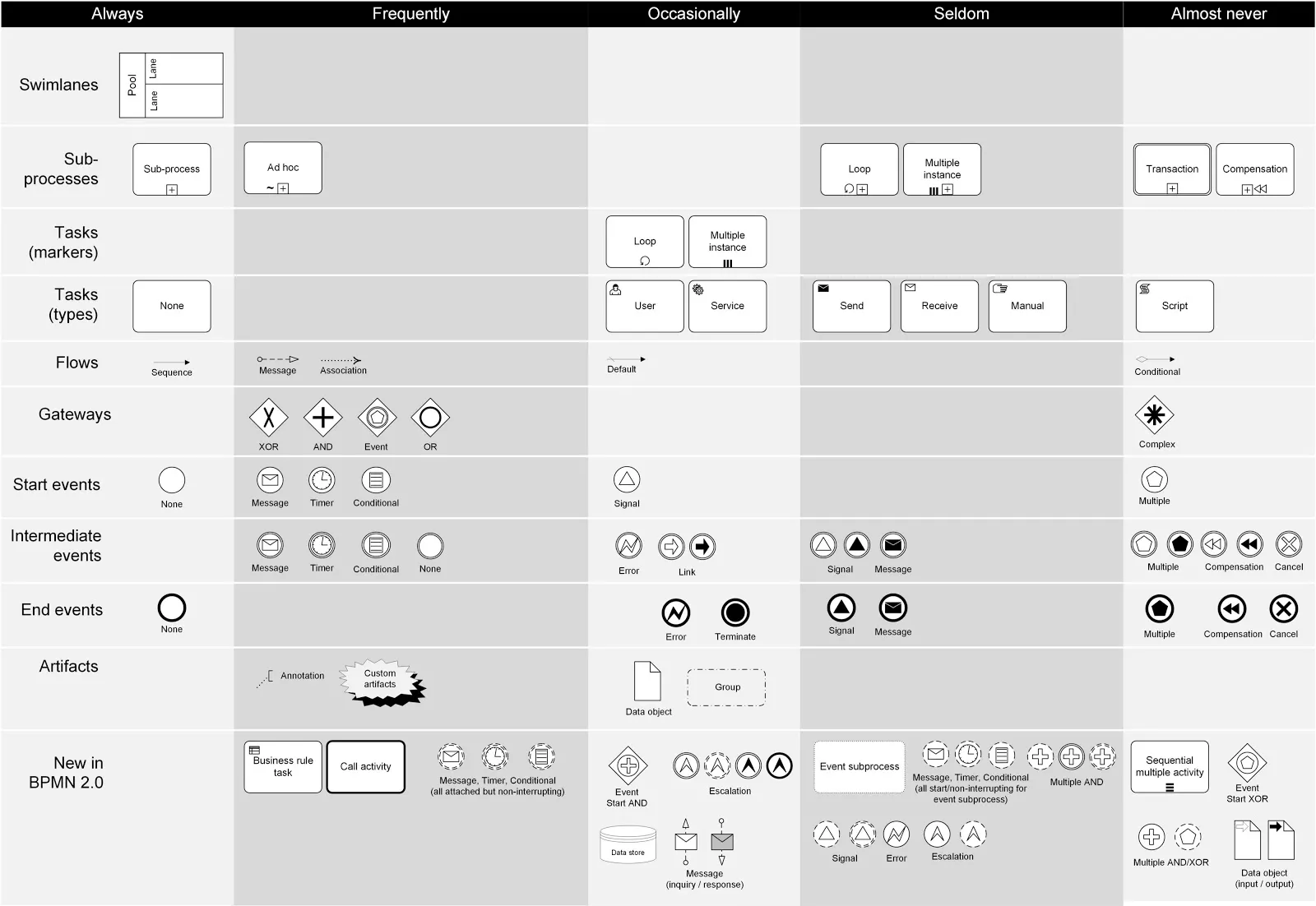
Transforming Workflow Automation: From Stateless to Stateful
by byNicolas Fränkel@nfrankel
byNicolas Fränkel@nfrankel
Dev Advocate | Developer & architect | Love learning and passing on what I learned!
May 23rd, 2024






Audio Presented by
Dev Advocate | Developer & architect | Love learning and passing on what I learned!


Dev Advocate | Developer & architect | Love learning and passing on what I learned!
About Author

Dev Advocate | Developer & architect | Love learning and passing on what I learned!
Comments