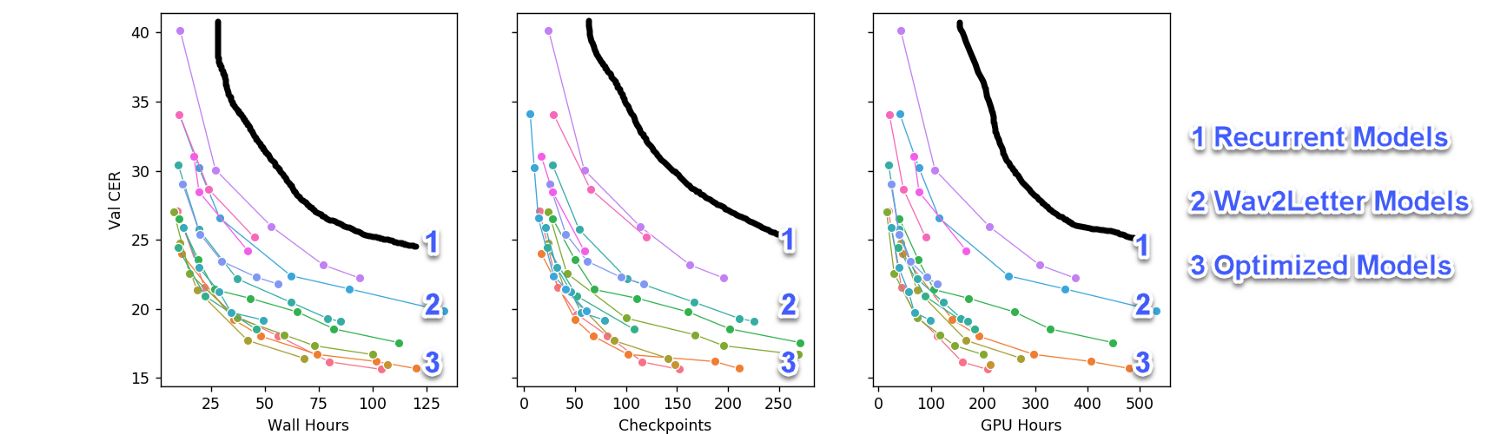
Speech-to-text (STT), also known as automated-speech-recognition (ASR), has a long history and has made amazing progress over the past decade. Currently, it is often believed that only large corporations like Google, Facebook, or Baidu (or local state-backed monopolies for the Russian language) can provide deployable “in-the-wild” solutions. Original TOC Related Work and Inspiration Open Speech To Text (Russian) Making a Great Speech To Text Model Model Benchmarks and Generalization Gap Further Work Abstract Speech-to-text (STT), also known as automated-speech-recognition (ASR), has a long history and has made amazing progress over the past decade. Currently, it is often believed that only large corporations like Google, Facebook, or Baidu (or local state-backed monopolies for the Russian language) can provide deployable “in-the-wild” solutions. This is due to several reasons: High compute requirements that are usually used in papers erect artificially high entry barriers; Speech requiring significant data due to the diverse vocabulary, speakers, and compression artifacts; A mentality where practical solutions are abandoned in favor of impractical, yet state of the art (SOTA) solutions. In this piece we describe our effort to alleviate these concerns, both globally and for the Russian language, by: Introducing the diverse 20,000 hour published under CC-NC-BY license; Open STT dataset Demonstrating that it is possible to achieve competitive results using only TWO consumer-grade and widely available GPUs; Offering a plethora of design patterns that democratize entry to the speech domain for a wide range of researchers and practitioners. Introduction Following the success and the democratization (the so-called , i.e. the reduction of hardware requirements, time-to-market and minimal dataset sizes to produce deployable products) of computer vision, it is logical to hope that other branches of Machine Learning (ML) will follow suit. The only questions are, when will it happen and what are the necessary conditions for it to happen? “ ” ImageNet moment In our opinion, the ImageNet moment in a given ML sub-field arrives when: The architectures and model building blocks required to solve 95% of standard “useful” tasks are widely available as standard and tested open-source framework modules; Most popular models are available with pre-trained weights; Knowledge transfer from standard tasks using pre-trained models to different everyday tasks is solved; The compute required to train models for everyday tasks is minimal (e.g. 1–10 GPU days in STT) compared to the compute requirements previously reported in papers (100–1000 GPU days in STT); The compute for pre-training large models is available to small independent companies and research groups; If the above conditions are satisfied, one can develop new useful applications with reasonable costs. Also democratization occurs — one no longer has to rely on giant companies such as Google as the only source of truth in the industry. If you would like to know more about the philosophy of our work and why we opted for online publications instead of conferences / peer reviewed papers - please follow this . link Related Work and Inspiration For our experiments we have chosen the following stack of technologies: Feed-forward neural networks for acoustic modelling (mostly grouped 1D convolutions with and transformer blocks); squeeze and excitation loss (CTC loss); Connectionist temporal classification Composite tokens consisting of graphemes (i.e. alphabet letters) as modelling units (opposed to phonemes); Beam search with a pre-trained language model (LM) as a decoder. There are many ways to approach STT. Discussing their drawbacks and advantages is out of scope here. Everything in this article is said about an end-to-end approach using mostly graphemes (i.e. alphabet letters) and neural networks. In a nutshell — to train an end-to-end grapheme model you just need a lot of small audio files with corresponding transcriptions, i.e. file.wav and transcription.txt. You can also use CTC loss, which alleviates the requirement to have time-aligned annotation (otherwise you will need either to provide an alignment table by yourself or learn alignment within your network). A common alternative to CTC loss is the standard categorical cross-entropy loss with attention, but it trains slowly by itself and it is usually used together with CTC loss anyway. This “stack” was chosen for a number of reasons: Scalability. You can scale your compute by adding GPUs; Future proofing. Should a new neural network block become mainstream, it can be integrated and tested within days. Migrating to another framework is also easy; Simplicity. Namely using Python and PyTorch you can focus on experimentation and not solving legacy constraints; Flexibility. Building proper code in Python you can test new features (i.e. speaker diarization) in days; By not using attention in the decoder nor phonemes or recurrent neural networks we achieve faster convergence and need less maintenance for our models; Open Speech To Text (Russian) All publicly available supervised English datasets that we know of are smaller than 1,000 hours and have very limited variability. , a seminal STT paper, suggests that you need at least 10,000 hours of annotation to build a proper STT system. 1,000 hours is also a good start, but given the generalization gap (discussed below) you need around 10,000 hours of data in different domains. DeepSpeech 2 Typical academic datasets have the following drawbacks: Too ideal. Recorded in studio or too clean compared to real world applications; Too narrow of a domain. Difficulty in STT follows this simple formula: noise level * vocabulary size * number of speakers; Mostly only English. Though projects like alleviate this constraint to some extent, you cannot reliably find a lot of data in languages other than German and English. Also Common Voice is probably more suitable for speaker identification task more than speech-to-text because their texts are not very diverse; Common Voice Different compression. Wav files have little to no compression artifacts and therefore don’t represent real world sound bytes that are compressed in different ways; Because of these drawbacks, about 6 months ago we decided to collect and share an unprecedented spoken corpus in Russian. We targeted 10,000 hours at first. To our knowledge this is unprecedented even for the English language. We have seen an to do work similar to ours, but despite the government funding, their datasets are not publicly available. attempt Recently we released a of the dataset. It includes the following domains: 1.0-beta version Our data-collection process was the following: Collect some data then clean it using heuristics; Train some models and use those models to further clean the data; Collect more data and use alignment to align transcripts with audio; Train better models and use those models to further clean the data;Collect more data and manually annotate some data; Repeat all the steps. You can find and you can . our corpus here support our dataset here Though this is already substantial, we are not yet done. Our short term plan is: Do some housekeeping, clean the data more, and clean-up some legacy code; Migrate to .ogg in order to minimize data storage space while maintaining quality; Add several new domains (courtroom dialogues, medical lectures and seminars, poetry). PS. We did all of this, our dataset was even featured on azure datasets, now we are planning in releasing pre-trained models for 3 new languages: English / German / Spanish. Making a Great Speech To Text Model To build a great STT model, it needs the following characteristics: Quick inference; Parameter-efficient;Easy to maintain and improve; Does not require a lot of compute to train, a 2 x 1080Ti machine or less should suffice; We take these as our goals, and describe how we fulfilled them below. Traditionally models are selected by benchmarking them on a couple of fixed “ideal” unseen validation datasets. In the previous sections we explained why this is sub-optimal if you have real world usage in mind and the only datasets available are academic datasets. Given limited resources to properly compare models you need a radically different approach, which we present in this section. Also keep in mind that there is no “ideal” validation dataset when you are dealing with real in-the-wild data — you need to . validate on each domain separately Usually when reporting some results on some public dataset (e.g. ImageNet), researchers allegedly run full experiments with different hyper-parameters from scratch until convergence. Also, a good practice is to run the so-called ablation tests, i.e. experiments that test whether or not additional features of a model were actually useful by comparing the performance of the model with and without those features. In real life, practitioners cannot afford themselves the luxury of running hundreds or thousands of experiments from scratch till convergence or building some fancy reinforcement learning code to control experiments. Also, the dominance of over-parameterized methods in the literature and the availability of enterprise oriented toolkits discourages researchers from deeply optimizing their pipelines. When you explore the hardware options, in the professional or cloud segment there is a bias towards expensive and impractical solutions. Read more to learn about our model selection methodology. here Overall Progress Made Initially we started with a fork of . The original Deep Speech 2 model is based on a deep LSTM or GRU recurrent network, which are slow. The above image illustrates the optimizations we were able to add to the original pipeline. More specifically, we were able to do the following without hurting model performance: Deep Speech 2 in PyTorch Reduce the model size around 5x; Speed up its convergence 5–10x; The small (25M-35M params) final model can be trained on 2x1080 Ti GPUs instead of 4; The large model still requires 4x1080 Ti but has a bit lower final CER (1–1.5 percentage point lower) compared to the small model. The above chart only has convolutional models, which we found to be much faster than their recurrent counterparts. We started on the process to getting these results as follows: Used an existing implementation of Deep Speech 2; Run a few experiments on LibriSpeech, where we noticed that RNN models are typically very slow compared to their convolutional counterparts; Added a plain Wav2Letter inspired model, which was actually underparameterized for Russian, so we increased the model size; Noticed that the model was okay, but very slow to train, so we tried to optimize the training time. So, we then explored the following ideas to improve things: Idea 1 — Model Stride; Idea 2 — Compact Regularized Networks; Idea 3 — Using Byte-Pair Encoding; Idea 4 — Better Encoder; Idea 5 — Balance Capacity — Never Use 4 GPUs Again; Idea 6 — Stabilize the Training in Different Domains, Balance Generalization; Idea 7 — Make A Very Fast Decoder; Please follow this to learn about each of these ideas in detail. link Model Benchmarks and Generalization Gap In real life it is expected that if the model is trained on one domain, there will be a significant generalization gap on another. But is there a generalization gap in the first place? If there is, then what are the main differences between domains? Can you train one model to work fine on many reasonable domains with decent signal-to-noise ratio? There is a generalization gap, and you can even deduce which ASR systems were trained on which domains. Also, with the ideas above, you can train a model that will perform decently even on unseen domains. According to our observations, these are the main differences that cause the generalization gap between domains: Overall noise level; Vocabulary and pronunciation; The codecs or hardware used to compress audio; This benchmark includes both an acoustic model and a language model. The acoustic model is run on GPU, the results are accumulated, and then language model post-processing is run on multiple CPUs For more detailed benchmarks, some thoughts on production usage and benchmark analysis please go . For up-to-date and updated benchmarks please go (Russian) here here . Further Work Here is a list of ideas, that we tested (some of which even worked), but we decided in the end that their complexity does not justify the benefits they provide: Getting rid of gradient clipping. Gradient clipping takes from 25% to 40% of batch time. We tried various hacks to get rid of it, but could not do it without suffering a severe drop in convergence speed; ADAM, Novograd and other new and promising optimizers. In our experience, they worked only with simpler non speech related domains or toy datasets; Sequence-to-sequence decoder, double supervision. These ideas work. Attention-based decoders with categorical cross-entropy loss instead of CTC are notoriously slow starters (you add speech decoding to the already burdensome task of alignment). Hybrid networks did not perform much better to justify their complexity. This probably just means that hybrid networks require a lot of parameter fine-tuning; Phoneme-based and phoneme-augmented methods. Though these helped us regularize a few over-parametrized models (100–150M params), they proved not very useful for smaller models. Surprisingly an extensive tokenization study by Google ; arrived at the similar result Networks that increase in width gradually. A common design pattern in computer vision, so far such networks converged worse that their counterparts with the same network width; Usage of . At first glance, this did not work, but maybe more time was needed to make it work; IdleBlocks Try any sort of tunable filters instead of STFT. We tried various implementations of tunable STFT filters and SincNet filters, but in most cases we could not even stabilize the training of the models with such filters; Train a pyramid-shaped model with different strides. We failed to achieve any improvement here;Use model distillation and quantization to speed up inference. At the moment when we tried native quantization in PyTorch it was still in beta and ; did not support our modules yet Add complementary objectives like speaker diarization or noise cancelling. Noise cancelling works, but it proved to be more of an aesthetic use; Author Bio Alexander Veysov is a Data Scientist in Silero, a small company building NLP / Speech / CV enabled products, and author of Open STT. Silero has recently shipped its own Russian STT engine. Previously he worked in a then Moscow-based VC firm and Ponominalu.ru, a ticketing startup acquired by MTS (major Russian TelCo). He received his BA and MA in Economics in Moscow State University for International Relations (MGIMO). You can follow his channel in telegram (@snakers41). Originally published at https://thegradient.pub on March 28, 2020. Acknowledgments Thanks to Andrey Kurenkov and Jacob Anderson from The Gradient for their contributions to this piece. Citation For attribution in academic contexts or books, please cite this work as Alexander Veysov, “Toward’s an ImageNet Moment for Speech-to-Text”, The Gradient, 2020. BibTeX citation @article{veysov2020towardimagenetstt, author = {Veysov, Alexander}, title = {Toward’s an ImageNet Moment for Speech-to-Text}, journal = {The Gradient}, year = {2020}, howpublished = {\url{ https://thegradient.pub/towards-an-imagenet-moment-for-speech-to-text/ } }, } Originally published at https://thegradient.pub on March 28, 2020. All citations and references preserved as they were in the original article. HN also does not have handy table-of-contents features, so I will leave the original links as well. Where appropriate, I will provide a link to the original part of the article. I will also provide links to more up-to-date benchmarks. Also soon we will be releasing pre-trained models for English / German / Spanish.


















![What Are Convolution Neural Networks? [ELI5]](https://hackernoon.imgix.net/images/69s32rn.jpg?auto=format&fit=max&w=3840)








