243 reads
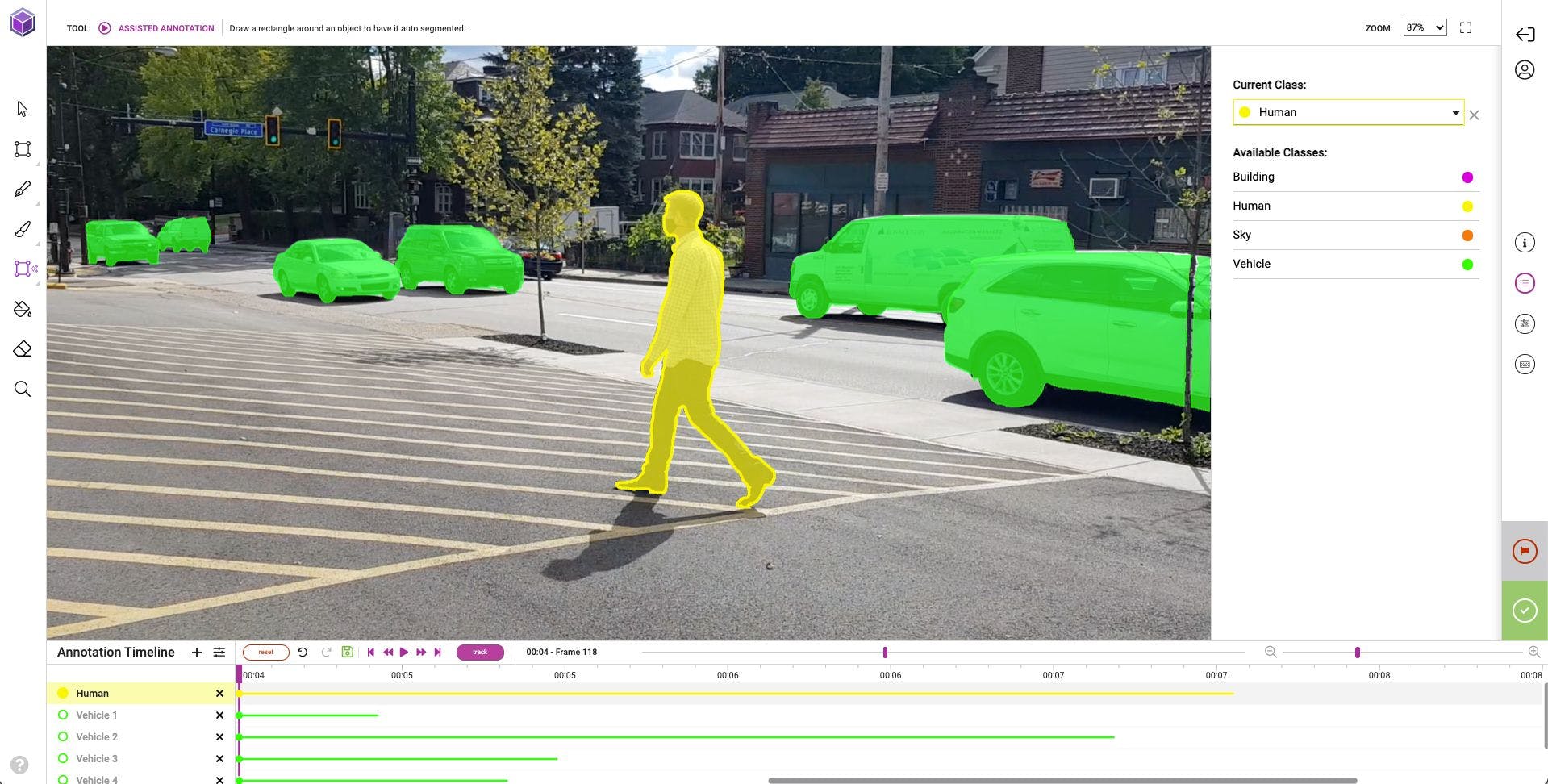
Top 3 Advantages of Video Annotation
by byInnotescus@innotescus
byInnotescus@innotescus
Innotescus is a collaborative video and image annotation platform built to streamline Computer Vision development.
May 2nd, 2021






Innotescus is a collaborative video and image annotation platform built to streamline Computer Vision development.


Innotescus is a collaborative video and image annotation platform built to streamline Computer Vision development.
About Author

Innotescus is a collaborative video and image annotation platform built to streamline Computer Vision development.
Comments