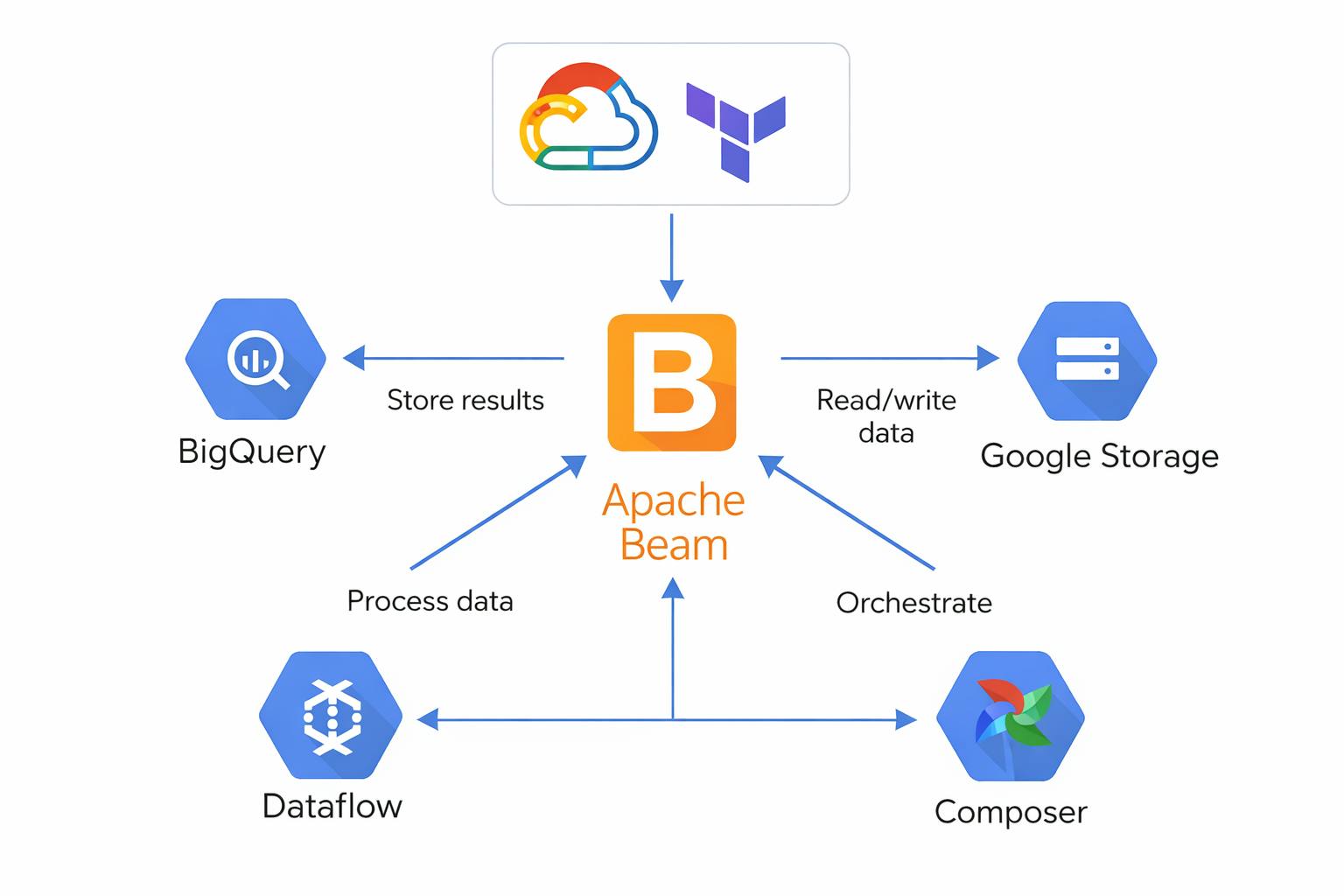
In modern fraud detection systems, a critical challenge emerges: how do you achieve both lightning-fast response times and unwavering reliability? Most architectures force you to choose between speed and consistency, but there's a sophisticated solution that delivers both. Traditional event-driven systems excel at immediate processing but struggle with sparse activity patterns and external query requirements. When events don't arrive, these systems can leave aggregations incomplete and state stale - a significant liability in financial services where every millisecond and every calculation matters. This post explores hybrid event-based aggregation - an architectural pattern that combines the immediate responsiveness of event-driven systems with the reliability of timer-based completion. We'll examine real-world implementation challenges and proven solutions that have processed billions of financial events in production. hybrid event-based aggregation The Core Challenge: When Event-Driven Systems Fall Short Event-driven architectures have transformed real-time processing, but they reveal critical limitations in fraud detection scenarios. Understanding these constraints is essential for building robust financial systems. Problem 1: The Inactivity Gap Consider a fraud detection system that processes user behavior patterns. When legitimate users have sparse transaction activity, purely event-driven systems encounter a fundamental issue. Figure 1: Pure event-driven systems struggle with sparse user activity, leading to incomplete aggregations Figure 1: Pure event-driven systems struggle with sparse user activity, leading to incomplete aggregations Without subsequent events to trigger completion, aggregation state persists indefinitely, creating several critical issues: Stale State Accumulation: Outdated calculations consume memory and processing resourcesLogical Incorrectness: Temporary spikes trigger persistent alerts that never reset automaticallyResource Leaks: Unclosed aggregation windows create gradual system degradation Stale State Accumulation: Outdated calculations consume memory and processing resources Stale State Accumulation Logical Incorrectness: Temporary spikes trigger persistent alerts that never reset automatically Logical Incorrectness Resource Leaks: Unclosed aggregation windows create gradual system degradation Resource Leaks Problem 2: The External Query Challenge Real-world fraud systems must respond to external queries regardless of recent event activity. This requirement exposes another fundamental limitation of pure event-driven architectures. Figure 2: External systems requesting current state may receive stale data when no recent events have occurred Figure 2: External systems requesting current state may receive stale data when no recent events have occurred When external systems query for current risk scores, they may receive stale data from hours-old events. In fraud detection, where threat landscapes evolve rapidly, this staleness represents a significant security vulnerability and operational risk. The Hybrid Solution: Dual-Trigger Architecture The solution lies in combining event-driven responsiveness with timer-based reliability through a dual-trigger approach. This architecture ensures both immediate processing and guaranteed completion. dual-trigger approach Core Design Principles The hybrid approach operates on four fundamental principles: Event-Triggered Processing: Immediate reaction to incoming data streamsTimer-Triggered Completion: Guaranteed finalization of aggregations after inactivity periodsState Lifecycle Management: Automatic cleanup and resource reclamationQuery-Time Consistency: Fresh state available for external system requests Event-Triggered Processing: Immediate reaction to incoming data streams Event-Triggered Processing Timer-Triggered Completion: Guaranteed finalization of aggregations after inactivity periods Timer-Triggered Completion State Lifecycle Management: Automatic cleanup and resource reclamation State Lifecycle Management Query-Time Consistency: Fresh state available for external system requests Query-Time Consistency Production Architecture: Building the Hybrid System Let's examine the technical implementation of a production-ready hybrid aggregation system. Each component plays a crucial role in achieving both speed and reliability. Event Ingestion Layer Figure 3: Event ingestion layer with multiple sources flowing through partitioned message queues to ensure ordered processing Figure 3: Event ingestion layer with multiple sources flowing through partitioned message queues to ensure ordered processing Key Design Decisions: Key Design Decisions: Partitioning Strategy: Events partitioned by User ID ensure ordered processing per userEvent Time vs Processing Time: Use event timestamps for accurate temporal reasoningWatermark Handling: Manage late-arriving events gracefully Partitioning Strategy: Events partitioned by User ID ensure ordered processing per user Partitioning Strategy Event Time vs Processing Time: Use event timestamps for accurate temporal reasoning Event Time vs Processing Time Watermark Handling: Manage late-arriving events gracefully Watermark Handling 2. Stream Processing Engine (Apache Beam Implementation) # Simplified Beam pipeline structure def create_fraud_detection_pipeline(): return ( p | 'Read Events' >> beam.io.ReadFromPubSub(subscription) | 'Parse Events' >> beam.Map(parse_event) | 'Key by User' >> beam.Map(lambda event: (event.user_id, event)) | 'Windowing' >> beam.WindowInto( window.Sessions(gap_size=300), # 5-minute session windows trigger=trigger.AfterWatermark( early=trigger.AfterProcessingTime(60), # Early firing every minute late=trigger.AfterCount(1) # Late data triggers ), accumulation_mode=trigger.AccumulationMode.ACCUMULATING ) | 'Aggregate Features' >> beam.ParDo(HybridAggregationDoFn()) | 'Write Results' >> beam.io.WriteToBigQuery(table_spec) ) # Simplified Beam pipeline structure def create_fraud_detection_pipeline(): return ( p | 'Read Events' >> beam.io.ReadFromPubSub(subscription) | 'Parse Events' >> beam.Map(parse_event) | 'Key by User' >> beam.Map(lambda event: (event.user_id, event)) | 'Windowing' >> beam.WindowInto( window.Sessions(gap_size=300), # 5-minute session windows trigger=trigger.AfterWatermark( early=trigger.AfterProcessingTime(60), # Early firing every minute late=trigger.AfterCount(1) # Late data triggers ), accumulation_mode=trigger.AccumulationMode.ACCUMULATING ) | 'Aggregate Features' >> beam.ParDo(HybridAggregationDoFn()) | 'Write Results' >> beam.io.WriteToBigQuery(table_spec) ) 3. Hybrid Aggregation Logic The core of our system lies in the HybridAggregationDoFn that handles both event and timer triggers: HybridAggregationDoFn Figure 4: State machine showing the dual-trigger approach - events trigger immediate processing while timers ensure guaranteed completion Figure 4: State machine showing the dual-trigger approach - events trigger immediate processing while timers ensure guaranteed completion Implementation Pattern: Implementation Pattern: class HybridAggregationDoFn(beam.DoFn): USER_STATE_SPEC = beam.transforms.userstate.BagStateSpec('user_events', beam.coders.JsonCoder()) TIMER_SPEC = beam.transforms.userstate.TimerSpec('cleanup_timer', beam.transforms.userstate.TimeDomain.PROCESSING_TIME) def process(self, element, user_state=beam.DoFn.StateParam(USER_STATE_SPEC), cleanup_timer=beam.DoFn.TimerParam(TIMER_SPEC)): user_id, event = element # Cancel any existing timer cleanup_timer.clear() # Process the event and update aggregation current_events = list(user_state.read()) current_events.append(event) user_state.clear() user_state.add(current_events) # Calculate aggregated features aggregation = self.calculate_features(current_events) # Set new timer for cleanup (e.g., 5 minutes of inactivity) cleanup_timer.set(timestamp.now() + duration.Duration(seconds=300)) yield (user_id, aggregation) @beam.transforms.userstate.on_timer(TIMER_SPEC) def cleanup_expired_state(self, user_state=beam.DoFn.StateParam(USER_STATE_SPEC)): # Finalize any pending aggregations current_events = list(user_state.read()) if current_events: final_aggregation = self.finalize_features(current_events) user_state.clear() yield final_aggregation class HybridAggregationDoFn(beam.DoFn): USER_STATE_SPEC = beam.transforms.userstate.BagStateSpec('user_events', beam.coders.JsonCoder()) TIMER_SPEC = beam.transforms.userstate.TimerSpec('cleanup_timer', beam.transforms.userstate.TimeDomain.PROCESSING_TIME) def process(self, element, user_state=beam.DoFn.StateParam(USER_STATE_SPEC), cleanup_timer=beam.DoFn.TimerParam(TIMER_SPEC)): user_id, event = element # Cancel any existing timer cleanup_timer.clear() # Process the event and update aggregation current_events = list(user_state.read()) current_events.append(event) user_state.clear() user_state.add(current_events) # Calculate aggregated features aggregation = self.calculate_features(current_events) # Set new timer for cleanup (e.g., 5 minutes of inactivity) cleanup_timer.set(timestamp.now() + duration.Duration(seconds=300)) yield (user_id, aggregation) @beam.transforms.userstate.on_timer(TIMER_SPEC) def cleanup_expired_state(self, user_state=beam.DoFn.StateParam(USER_STATE_SPEC)): # Finalize any pending aggregations current_events = list(user_state.read()) if current_events: final_aggregation = self.finalize_features(current_events) user_state.clear() yield final_aggregation 4. State Management and Query Interface Figure 5: Multi-tier state management with consistent query interface for external systems Figure 5: Multi-tier state management with consistent query interface for external systems State Consistency Guarantees: State Consistency Guarantees: Read-Your-Writes: Queries immediately see the effects of recent eventsMonotonic Reads: Subsequent queries never return older stateTimer-Driven Freshness: Timers ensure state is never more than X minutes stale Read-Your-Writes: Queries immediately see the effects of recent events Read-Your-Writes Monotonic Reads: Subsequent queries never return older state Monotonic Reads Timer-Driven Freshness: Timers ensure state is never more than X minutes stale Timer-Driven Freshness 5. Complete System Flow Figure 6: End-to-end system architecture showing data flow from event sources through hybrid aggregation to fraud detection and external systems Figure 6: End-to-end system architecture showing data flow from event sources through hybrid aggregation to fraud detection and external systems Advanced Implementation Considerations Watermark Management for Late Events Figure 7: Timeline showing event time vs processing time with watermark advancement for handling late-arriving events Figure 7: Timeline showing event time vs processing time with watermark advancement for handling late-arriving events Late Event Handling Strategy: Late Event Handling Strategy: Grace Period: Accept events up to 5 minutes lateTrigger Configuration: Process immediately but allow late updatesState Versioning: Maintain multiple versions for consistency Grace Period: Accept events up to 5 minutes late Grace Period Trigger Configuration: Process immediately but allow late updates Trigger Configuration State Versioning: Maintain multiple versions for consistency State Versioning Conclusion Hybrid event-based aggregation represents a significant advancement in building production-grade fraud detection systems. By combining the immediate responsiveness of event-driven processing with the reliability of timer-based completion, organizations can build systems that are both fast and reliable. The architecture pattern described here addresses the core limitations of pure event-driven systems while maintaining their performance benefits. This approach has been proven in high-scale financial environments, providing a robust foundation for modern real-time fraud prevention systems. Key benefits include: Sub-10ms response times for critical fraud decisionsGuaranteed state consistency and completionScalable processing of millions of events dailyAutomated resource management and cleanup Sub-10ms response times for critical fraud decisions Sub-10ms response times Guaranteed state consistency and completion Guaranteed state consistency Scalable processing of millions of events daily Scalable processing Automated resource management and cleanup Automated resource management As fraud techniques become more sophisticated, detection systems must evolve to match both their speed and complexity. Hybrid event-based aggregation provides exactly this capability. This architecture has been successfully deployed in production environments processing billions of financial events annually. The techniques described here are based on real-world implementations using Apache Beam, Google Cloud Dataflow, and modern stream processing best practices. This architecture has been successfully deployed in production environments processing billions of financial events annually. The techniques described here are based on real-world implementations using Apache Beam, Google Cloud Dataflow, and modern stream processing best practices.