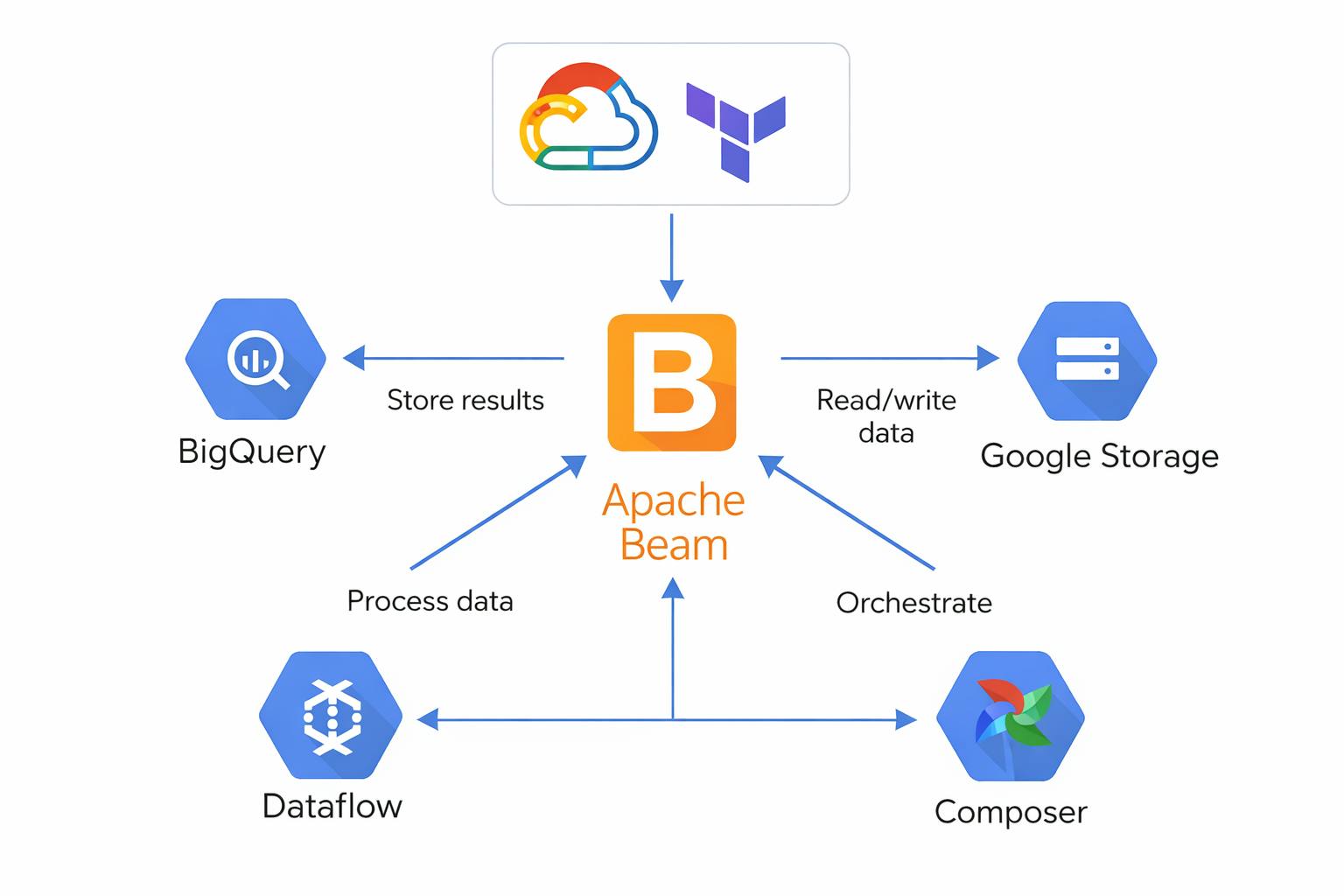
321 reads
Event Time Processing with Flink and Beam - Power of Real time Analytics
by byAbhishek Gupta@hackerabhish
byAbhishek Gupta@hackerabhish
Engineering Leader & Mentor @ Cisco. Former Architect @ PayPal. Technology Evangelist @ HackerNoon. Redefining scalable
November 8th, 2024






Engineering Leader & Mentor @ Cisco. Former Architect @ PayPal. Technology Evangelist @ HackerNoon. Redefining scalable
Story's Credibility



Engineering Leader & Mentor @ Cisco. Former Architect @ PayPal. Technology Evangelist @ HackerNoon. Redefining scalable
Story's Credibility
About Author

Engineering Leader & Mentor @ Cisco. Former Architect @ PayPal. Technology Evangelist @ HackerNoon. Redefining scalable
Comments