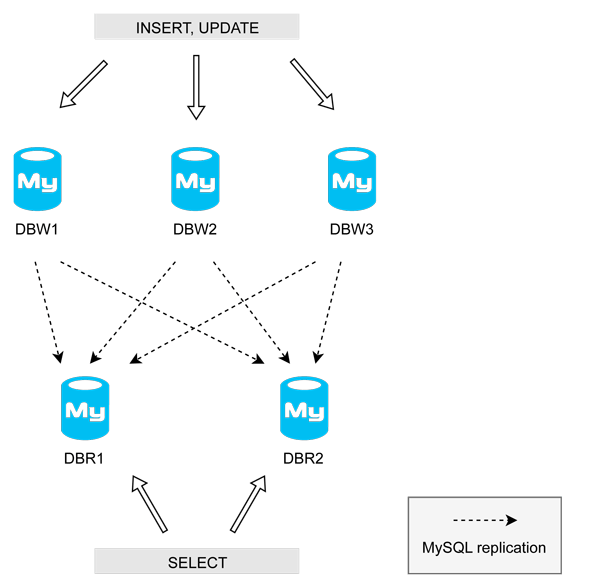
TL;DR we shard writes and avoid conflicts using an increment offset on PKs each data center contains local write servers we use multi-source replication on read servers so they contain all the data from all data centers, partitioned by month At the beginning, things were simple We were using : one master for writing, and a few slaves for reading. Besides (more on that later), it worked fine. And then you scale. And then it fails! The master is a SPOF — “ ingle oint f ailure”. MySQL replication lag S P O F Whether the process failed, the VM crashed, or we had to do maintenance on the server, having only one “master” to write to meant that the service was down for minutes. And this was not acceptable. The first thing we implemented was : there was the “stats” cluster (one master + N slaves), the “calls” cluster, the “customers” cluster, and so on. This allowed easier maintenance of the servers, as we could work on one cluster without impacting the others. sharding based on the “type” of data But there was still a SPOF in each cluster: the master. Options To get rid of the master-slave architecture where the master is a SPOF, we needed a solution where we could write on any node, failing over to another node if the previous one was not available. For reading, we needed a solution where we could run queries against “federated” data (reading from every node). This is not as simple as it sounds. When working on distributed systems, you have to work with: onsistency C vailability A artition tolerance P Yes, the . CAP theorem What should happen if you update a row on a node, and at the same time you update the same row on another node? Data reconciliation is hard (and sometimes impossible). What if you have a network failure, and the data is not consistent between the nodes? Which one do you trust? We looked at many technologies. There was the ‘master-master’ topology. MySQL Cluster was a good candidate. There was also Galera cluster, tungsten replicator, MySQL proxy… (At the time, MySQL group replication was not production ready). We also looked at the NoSQL world. Cassandra, MongoDB, HBase… but: we had a strong knowledge of MySQL in the team we were confident with it, it was stable, we knew how to run it we wanted to change our code as little as possible New technologies are sexy for sure. But stability and maintenance are key when you run a business. Note: there are many solutions now, especially if you are “in the cloud” and starting from scratch. The solution we expose here works pretty well if you have an existing MySQL infrastructure, an existing code base, people that have experience with MySQL, and the need to scale without changing the whole storage layer. Our solution There are two kinds of data we work with: data: carriers, phone numbers, routing profiles, dialcodes, etc. The data changes rarely, we must keep it “forever” (besides mandatory removal in respect of GDPR and other regulations), and it grows very slowly over time. “permanent” data: calls, SMS, API requests, events, webhooks, logs. . Written once. May be updated within hours. “usage” Grows very rapidly For the permanent data, we use a master-master topology. Nothing fancy here. We always write on the same master. If it fails, or if we need to do maintenance, we switch to another master. The story here is for the usage data. We call this the because we split reads/writes. “DBRW” architecture How it works Our implementation is pretty simple: when we need to insert data, (*). If it is not available, or if the error lets us failover, we try another write server. Boom! we choose a write server randomly The SPOF is gone! Write servers contain only the data that has been written on them. Their data is replicated asynchronously on the read servers. Read servers federate data from all the write servers, using multi-source replication. We apply the same rule for connection than with the write servers: we choose one server randomly (*), and fail over if it is not available. (*) Our system is a bit more clever: it avoid servers that are in maintenance or marked down by the supervision, the “random” is weighted, and we always try servers in the same datacenter first. We and on write servers. We on read servers. INSERT UPDATE SELECT Write servers Data purged daily, they need a limited storage space only We use very fast SSDs to get the best performance No indexes besides the primary key (so inserting is very fast) A server can be shut down for maintenance, it does not affect the system Read servers Same schema + indexes + partitions by month Indexes allow fast search queries (but take space) Partitions let us move data between disks, or discard old data in milliseconds Increment offsets explained Read servers receive and “merge” data from all write servers, by leveraging multi-source replication. To avoid conflicts on primary keys, we use an increment + on the write servers. For example: increment offset server DBW1 (increment 20, offset 1): 1, 21, 41, 61, 81 server DBW2 (increment 20, offset 2): 2, 22, 42, 62, 82 server DBW3 (increment 20, offset 3): 3, 23, 43, 63, 83 This way, INSERTs are not subject to conflict. When we need to UPDATE, . Write servers retain data for just a few days, older data is purged. Fortunately, once written, the , or it is within hours. we need to do it on the server that has the data usage data is rarely updated Obviously, this architecture does NOT work for data that needs to be updated continuously over time! To know which server holds the data with the primary key, all we need to do is apply a modulo of the increment, and it will give us the offset, thus the server. Example : (DBW1) or (DBW2). 41 mod 20 = 1 62 mod 20 = 2 Advantages of this architecture Any server can be turned off without impacting the service Write servers are light, and extremely fast (no indexes) Works well on a multi data center topology: ➡️ Write servers can be placed “locally” in each data center ➡️ Read servers can be “remote” as the MySQL replication works well on a WAN Read servers contain all the data, so search queries work as expected Maintenance on read servers is quite easy with the partitions Scaling writes is easy Cons Read servers require a lot of space (“vertical scaling”) but partitions makes it easy The primary key of write servers replicated and aggregated on read servers is not contiguous, and is not in order, because it is incremented independently on each write server We have been using this architecture for years, and it has been working great so far. Implementation Implementing the read/write split can be tricky. In our case, most of our projects had a “datastore” layer, in which we could easily implement the split, and the . sharding The most important part is not to forget to when doing updates, or if/when replication lag is an issue. read your own writes Recommended reading is a good book, unfortunately not up to date with the latest version of MySQL High performance MySQL , although not MySQL specific, is a great read Designing data-intensive applications is truely awesome The Percona blog Originally published at blog.callr.tech on August 29, 2018.