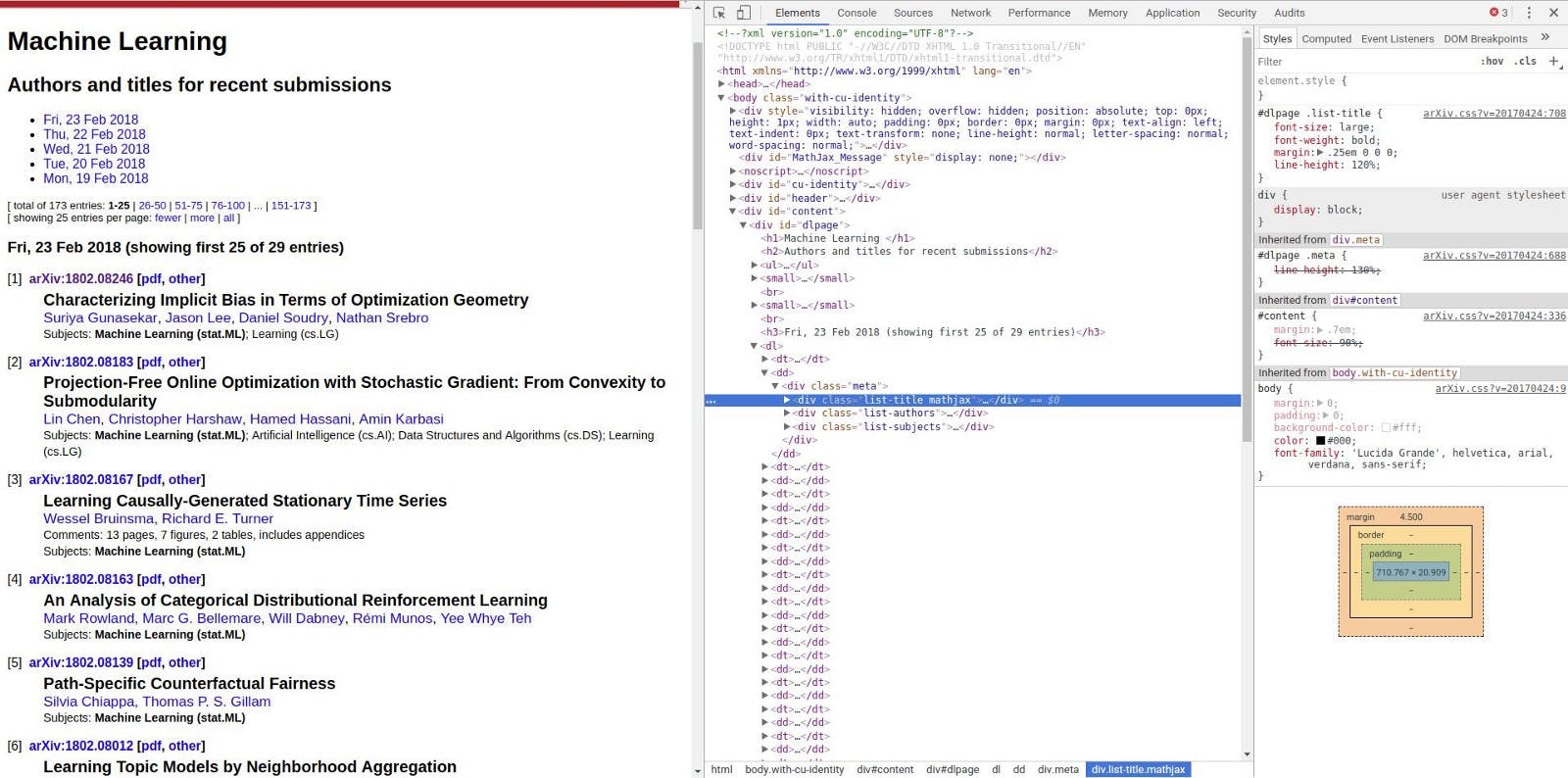
I often find myself in a situation where I need to get data from a that has no API or RSS feed. There exists many different web scraping libraries but I’m unsatisfied, I want something capable of: website . I have so I prefer using CSS selectors than XPath. Using CSS selectors worked as a fullstack developer . Most of the times I don’t need something very complex or advanced, I just need to make a simple scraper very quickly. Creating a working scraper in almost no time This motivated me to create a simple scraping library called (the Italian word for scraper). Here are its main features: Raschietto CSS Selectors Single line getting and parsing of an HTML page Simple and extensible methods for matching elements in the page Prebuilt matchers for common tasks (for example extracting links and images) The library is currently in beta (but is sufficiently stable) and supports only Python3 (adding Python2 support is quite straightforward). I’m sharing this library because I think it can speed up the process of building simple scrapers and because its small codebase (<170 lines of code) can be useful for learning purpose. You can install it with: pip install raschietto Scraping arXiv As an example to learn how to use and to showcase its capabilities I will guide you trough the scraping of an arXiv webpage. Please note that arXiv has so its data can be easily accessed without the need for scraping, but we will still scrape it for educational purpose. raschietto a very nice RSS feed We will focus on . the page that contains the latest machine learning papers The page with Chrome dev tools opened As a starting point we begin with just getting the titles of the latest papers. Since raschietto uses CSS selectors this task is quite easy. Using Chrome we can copy the CSS selector that will select a specific element using the dev tools. Just place the mouse on the desired element (in the DOM view)> right click > Copy > Copy selector How to get a CSS selector with Chrome dev tools We get the following selector: #dlpage > dl > dd:nth-child(2) > div > div.list-title.mathjax This selector is specific to that title element so it will not select other title elements. By looking at the HTML code of the page we can modify it to get a simpler selector that will select all the desired elements: .meta .list-title If we are unsure about the correctness of our selector we can test it using the console (in the dev tools) The code for getting the titles of the papers with raschietto is straightforward and self explanatory We are using two raschietto components: is a class that contains all the main functionalities of the library. In this example we are using it to get and parse an HTML page Raschietto is a class that encapsulates the matching logic. As a default it return the inner text of the matched element(s), we will later see how to change this behavior. Matcher We now get as a result a list of titles that all start with “Title: ” to remove this first 7 characters we can use the mapping capability of the Matcher class The only change we made is adding the mapping argument to our matcher. This is a function that takes 2 arguments: the matched element, and the containing page. We use a Raschietto function to map the matched element to its inner text and then use python slicing to remove the first 7 characters, obtaining the cleaned up list of titles. We now wish to do something more advanced: we want to match both the title and list of authors for each paper. To achieve this we need to: Match all the “.meta” elements For each matched element get the contained paper title For each matched element get the contained list of authors The mapping capability of the Matcher class make this task really simple, we just need to match all “.meta” elements and map them to a containing the title and the list of authors. dict With just a few lines of code we have created a nice scraper! Of course this is not enough for us: we also want to get the link to the paper. This may seem problematic because of the structure of the arXiv page. I’m terrible at drawing The title and the link are contained by different elements and it is not useful to use their first common parent because it contains all the papers elements. To get the link we have to: Match the “.meta” element Select its parent (the “dd” element) Select the element right before the “dd” element (so we get the “dt” element) Match the “a” element that links to “https://arxiv.org/abs/<paper id>” Extract the from the matched link href We already went through step 1. To achieve step 2 and 3 we can leverage the fact that the “el” parameter passed to the mapping function is an instance of so we can use lxml methods to get the “dt” elemen by selecting the previous element of the parent of . lxml HtmlElement el dt = el.getparent().getprevious() To complete step 4 and 5 we can use a prebuilt matcher that matches links , extracts the from each of them and make each url absolute (for example it maps “/abs/1802.08246” to the absolute url “https://arxiv.org/abs/1802.08246”). Matching links is quite common when scraping so I’ve included this matcher in the raschietto library. This matcher has also a parameter that, when specidied, will tell the matcher to keep only the results that begins with the given string. Using this matcher the code for our task is very short: href startswith link_matcher = Matcher.link(".list-identifier > a", startswith="https://arxiv.org/abs/") With this changes we get the final version of our arXiv scraper Notice that we passed the argument to the to let it know the source url of the element (otherwise is impossible to make the url absolute) page link_matcher Conclusions With just 15 lines of elegant code (empty lines don’t count) we developed a working scraper capable of extracting information from a webpage. We were easily able to group the matched elements, overcome the problem of “no useful common parent” and extract the needed information from each element without writing a lot of code. I truly hope you like this small library. If you have some questions about it feel free to ask them in the comments. If you want to collaborate to development of the library don’t hesitate to contact me :) You can find more information about me, all my projects and all my posts on my website https://matteo.ronchetti.xyz