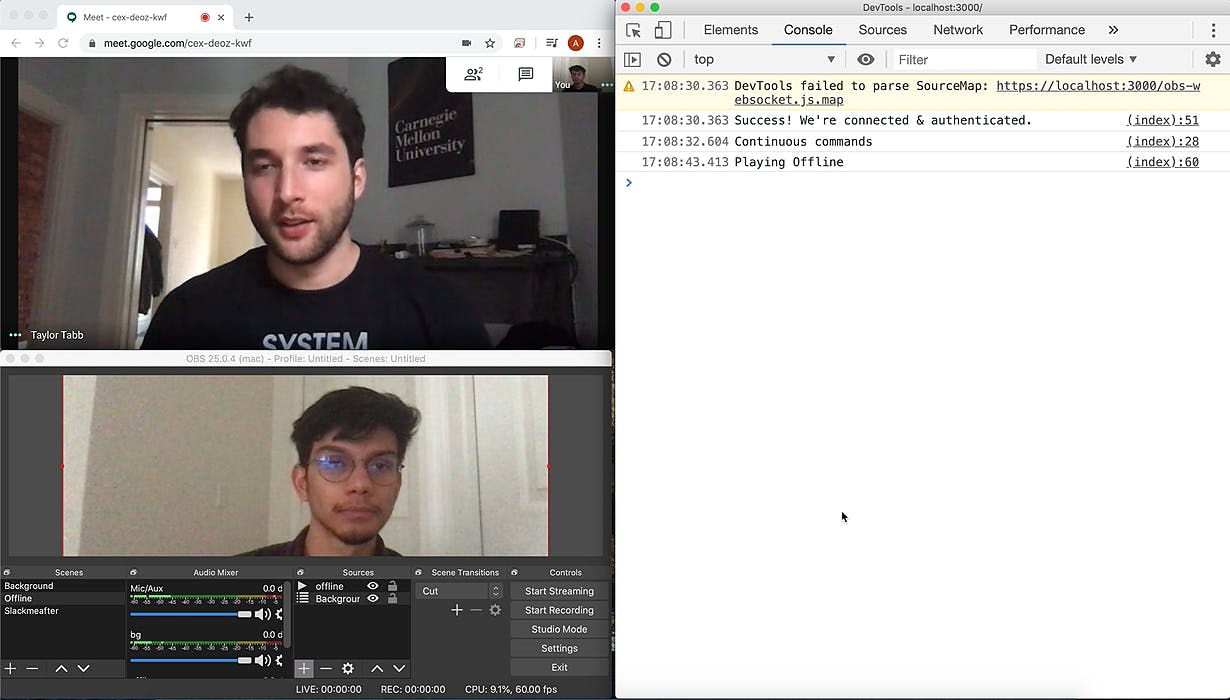
EDIT: Edit: I put the instructions on Github! Added my code to This morning I stumbled onto a talking about a guy ( ) who made a digital AI twin that replaced him on a Zoom call and would participate in conversation. Gizmodo article Matt Reed I thought this was awesome and wanted to take it a step further — Matt’s system works by listening to what was said on the call and parsing out the key word/phrases with this awesome . Then it uses Artyom’s Speech Synthesizer to speak out the responses while changing the image to a different head pose or mouth position. Artyom Library Pretty damn cool. Then I started to think of all the things I usually say on calls. Especially now that I’m working from home a lot more — stuff like “Hey are you still there” “Your connections’ breaking up” “What do you think” “Do you agree ?” So I thought of what my responses would be to those. After doing some research and digging into . I made a version of my own. I detect keywords and playback time using the same Artyom library, but instead of images, I use prerecorded clips. Matts’ code I started off by recording a few clips of myself, I needed a background video so I recorded a 5 second clip of myself just watching the screen. Then I recorded my answers to some of those questions above. I then tried to find a virtual camera solution that would let me play these clips. I ultimately settled on ; however setting that up ended up being a little more work then I thought — luckily had me covered with a Plugin for OBS that let me use it as a virtual camera. I then added all the clips I recorded above into OBS. OBS johnboiles Next I created a simple webpage that would listen for audio from Google Hangouts or Zoom and would tell OBS what scene what to play based on the questions I was asked during the call using an obs websocket library After some re-records and code suggestions from Matt himself! I called a friend (Thanks Taylor Tabb!), changed my source to the virtual camera feed and started recording! Quarantine Day 22 amirite?