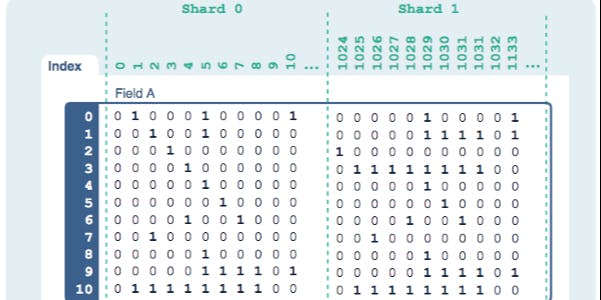
Big data is a big problem, at least getting anything useful out of it. there is about three quintillion (the next step up is sextillion or one zettabyte) bytes of data created and only about 20% of it is structured and available to easily process. Nearly all useful processing that is done relies on a philosophy that is little changed from the green bar reports we were generating during the night shift and handing out up till the turn of the century. The whole map/reduce process is overnight batch processing, you aren’t working on live data, you are working on a snapshot, which might be fine for some companies, but for others, they need to be able to make decisions on high-velocity inbound data in near/real time. Every day Your typical relational database uses a b-tree index and these are generally good for retrieving smaller subsets of data from large sets of data. They are notoriously slow when adding data as the indexes get populated, although fractal indexes like make the put process faster. This brings me to bitmap indexes, which are a radical departure from the type of indexing you are used to. They are incredibly fast and performing searches that have to combine queries using multiple columns that have low cardinality such as months of the year or shoe size as opposed to something like the distance you live from the North Pole, which has a massive number of variations. The issue with bitmap indexes has historically been that they haven’t scaled well, which brings me to . TokuDB Pilosa Pilosa is an open source bitmap indexing that is now maintained by , the same people that originally developed it while at and have gone through some organizational changes. Inspired by a conversation at a conference where the topic of bitmap indexes came up, there was a realization that this could solve a lot of their problems with massive amounts of high-velocity data that needed to be indexed and analyzed. The group spent the next several years building and perfecting their technology which resulted in 8 patents thus far (yes, it is still open source though). project Molecula Umbel Cassandra Using a data repository, cloud, and operating system agnostic approach, Pilosa acts as an additional indexing system that can be applied to an existing repository, including a flat file. Looking at the example below, if you imagine that the column headers represent Customer_ID, and the rows in Field A indicate product inventory, then each 1 represents the products purchased by each Customer_ID.. You will also notice that this is separated into shards, this is how Pilosa scales horizontally so effectively and was one of the huge technical hurdles that they solved with the project. These bitmaps are very small and are compressed in addition to that and do not need to be decompressed to read. Pilosa’s software can store a knowledge representation of underlying data in memory, making it orders of magnitude smaller and unimaginably fast. Keeping that agnostic approach in mind, you can actually have Pilosa index across data repositories to tie together disparate data sources and allow you to execute those very fast queries against all of them at once. The implications of that are really staggering when you think about it for a moment, with a performance that claims that a simple query can traverse more than 2 billion edges in one second on commodity cloud hardware, there is no reason you can’t do your critical analytics in real time. (This graph is from 2017 and there have been significant improvements since then) Some really clever applications of this technology is the ability to create a virtual data source from your underlying data and share it with a client or partner by giving them access to an API and now they can return index data, something like all XL t-shirts sold in August in Los Angeles but without giving them access to the underlying data. The implications here are tremendous, think about being able to aggregate out data from a lot of different companies in the same space into an anonymized repository that you could report on? This is another unique and powerful feature that I don’t recall seeing anywhere, Molecula refers to it as being the VMWare of data. Now, I will say that their documentation could use some beefing up, but you can get a learn about their schema language and their query language ( ) is not anything like you are used to, simple but different, and therein lies the challenge, (re)writing your code to take advantage of it. Pilosa isn’t terribly hard to install and setup, but you really want to think about what you are doing and plan it out so you are taking full advantage of it. The index rate is insanely fast, depending on the data density, you could do a billion records in a half hour because it isn’t making copies of the data. The issue is that you need to rearchitect your code to make use of it, they have available for Golang, Java, and Python. Having to redo your code isn’t necessarily a bad thing, but it is a time-consuming thing and a lot of people would love to see a magical drop-in replacement that makes all their code run faster. Molecula has set out to solve many of these challenges, with one focus being a plugin for Kafka so that you are only dealing with that pipe instead of a huge number of programs. here PQL client libraries This system is ripe for a partnership with a data visualization dashboard, it would make a great combination for a business to have a live dashboard into certain types of data that have high volatility. There is not really a point in using Pilosa until you are in the 4tb range at a minimum, so keep that in mind. If you want to learn more about bitmap indexes, I really enjoyed . this article




















![10 FinTech Trends in 2021 [Part II]](https://firebasestorage.googleapis.com/v0/b/hackernoon-app.appspot.com/o/images%2F3nhao37bBEfHA9RTQ0WNVWfXPD02-ern31d7.jpeg?alt=media&token=f48ef9e5-ec15-4bfe-93cf-9a84dfb77f84&auto=format&fit=max&w=3840)






