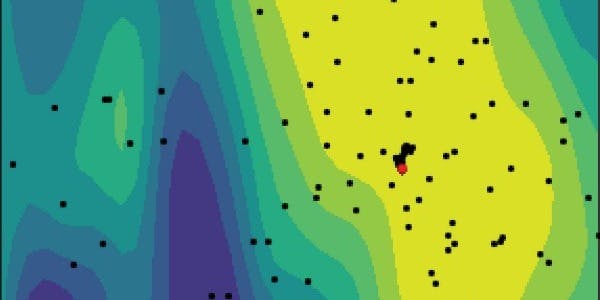
Creating a powerful predictive algorithm usually involves a certain amount of optimization. This involves tuning a model’s parameters to maximize a certain , such as the in finance. One of the most popular methods is , which is a significant improvement in computational efficiency and results over both — two other popular ways of optimizing hyperparameters. When evaluating a costly black-box function, Bayesian optimization is by far the most popular method for tuning hyperparameters. hyperparameter objective function Sharpe Ratio Bayesian optimization random search and grid search The process of developing trading algorithms differs little from model development in other fields. Data needs to be collected, cleaned, and structured. A model needs to be created and tested, and with that come the typical pitfalls of overfitting and . To measure whether a predictive model will work well, it is not enough to consider only performance over the training set — data that the model has previously seen and is referred to as “in-sample”. data leakage Models are expected to perform better in-sample than on previously unseen data — the out-of-sample set. This forms the basis of evaluating models ( ), and why it is so important to prevent data leakage, where information from the out-of-sample testing set can be inferred from the model during training. This would skew the model to perform better on the testing set than it would have if it had truly not seen that data before. which can be quite extensive A is a common financial indicator for trend strength and can be used in trading algorithms. It looks at the price of an asset at the close of a trading period and compares it with the range of prices in a number of past periods. We will use a stochastic oscillator momentum indicator as an example to illustrate the potential problems one can encounter when developing and tuning a trading algorithm on 30 minute bitcoin prices from Coinbase. stochastic oscillator We fit the stochastic oscillator from January 1st, 2019 through February 2019, and test over the next two months. A stochastic oscillator is defined as: Where high and low values are calculated over the previous k1 trading periods, and t indicates time period. To generate trading signals, it is common to consider moving averages of %K: An is a moving average that places greater importance on more recent data than a simple moving average. In the above equations, the subscript specifies the decay factor ⍺ of the EMA in terms of a span, where exponential moving average (EMA) We define an exponential moving average as the recursive function Intuitively, %D is a measure of an asset’s short-term momentum, whereas %DS is measuring the long-term momentum. Therefore, if %D > %DS, a buy signal is generated, and conversely if %D < %DS, a sell signal is generated. Based on this definition, the three tunable hyperparameters for a stochastic oscillator based trading model are k1, k2, and k3. The overfitting problem of a biased model in this scenario concerns tuning a model until the parameters specifically pick one or multiple highly successful trade(s) that maximize(s) the objective function. This becomes significantly more likely with fewer constraints during optimization and higher cadence data (for example minute open-high-low-close “candlesticks”). Therefore, it is especially important not to be misled by the model’s performance in the in-sample training set. Two constraints we chose to apply are limiting k1 > k2 > k3, k3 > 20 and The latter constraint regularizes the k parameters to prevent overfitting in-sample. After performing both regularized and unregularized Bayesian optimization over the same training set, the parameters optimized with regularization are k1=1377, k2=714, k3=20 andk1=1380, k2=770, k3=20 respectively. When looking at the in-sample trades of the two algorithms, one without k regularization and one with k regularization as specified above, it is clear that the in-sample performance is not much different — apart from slight differences in the timing of trades — both algorithms generally buy and sell at the same time. However, the conclusion suggested by in-sample performance is that the unregularized algorithm performs better. This is why it is always extremely important to compare the out-of-sample performance of algorithms. Training Period Both algorithms make two trades in the training period (in-sample), however the trades are made at slightly different times. Fig 1. The unregularized algorithm outperforms in terms of cumulative return in-sample — likely due to overfitting. Fig 2. When evaluating performance we commonly look at , to see how the funds allocated to any strategy would change if the strategy were trading live. We arbitrarily normalize the AUM to 100 at the start of any period we want to compare over. assets under management (AUM) Testing Period In the out-of-sample testing period, however, the regularized algorithm makes eight trades with the unregularized algorithm making one more Fig 3. The regularized algorithm performs marginally better in terms of cumulative returns at the end of the testing period. Fig 4. The test period shows that the factor regularized algorithm performs better, and this is supported by graphs of the objective function space of the Bayesian optimization algorithm. Fig 5. Fig 6. Please note that the decimal values of k2 and k3 are due to the optimization space constraints of the `skopt` package that we employ to enforce our k1 > k2 > k3 constraint. We express k2 in terms of k1 and k3 in terms of k2. These figures show how Bayesian optimization models the objective function based on the trial points in the hyperparameter space. For example, the graph of k1 in relation to k3 in Fig 5., shows each trial point as a black dot, and a single red dot for the most optimal point. The background colors represent the value of the objective function — in this case the — relative to the two hyperparameters of the x- and y-axis. Sharpe Ratio It is clear that the objective function of the factor-regularized model is slightly distorted by the regularization, and therefore the confidence in the chosen parameters is not as high as for the non-regularized model. However, the objective functions are largely well-behaved and similar in shape, which is indicative of a space where algorithm performance should be similar. Nevertheless, regularization helps with managing expectations based on the training and testing set performance. Conclusion The general takeaway should be that one must be careful when tuning models. In finance, there is a less strict framework for model development and testing than in the wider machine learning community. It is important to carefully investigate the optimization results and see why it is that certain parameters work better. The distribution of returns matters regarding performance evaluation. If it is just one or two highly successful trades that the optimization was able to pick out, odds are the same condition will not happen out-of-sample. That is why following a proper model development process, preventing data leakage, and regularizing model parameters is of particular importance in financial applications. To learn more about Bayesian optimization, you can . read our article about Bayesian optimization The opinions and data presented herein are not investment advice and are for informational purposes only and should not serve as the basis of any investment decision. Information is given in a summary form and does not purport to be complete. Information and data have been obtained or derived from sources believed by Blockforce Capital to be reliable, however, Blockforce Capital does not make any representation or warranty as to its accuracy or completeness. The sole purpose of this material is to inform, and in no way is intended to be an offer or solicitation to purchase or sell any security, other investment or services, or to attract any funds or deposits. Past performance does not guarantee future results.