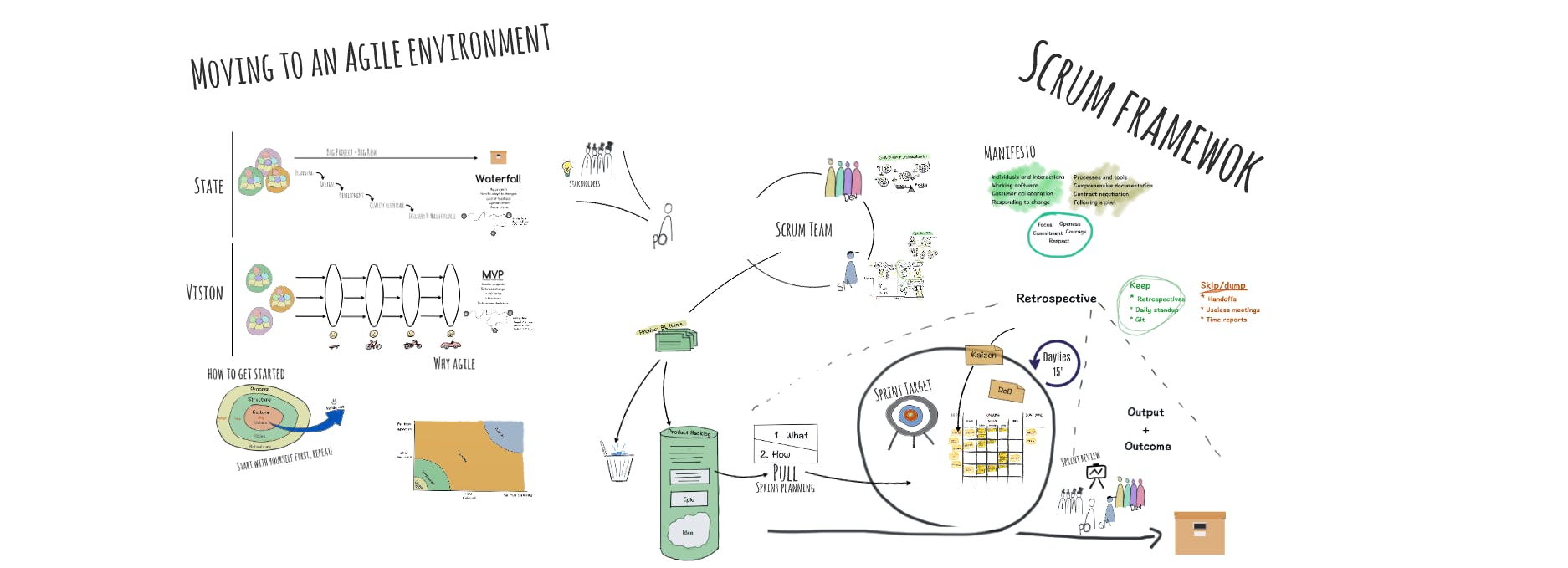
Dear reader, I came across with this article to tell you about an experience that I’ve been living since a few months now — the experience of moving from a waterfall to an environment. I’m not an Agile nor a Scrum guru, but I’ll be giving you what I have been learning both from my experience and what I’ve been retrieving from some books and articles. This is part 3 of 3. agile I’ve been talking to you about and Scrum in parts and , essentially about what I’ve grabbed from , articles, blog posts, videos… you name it. But from all of this I’ve found some gaps, some little pieces that didn’t fit together or some “rules by the book” that we’ve found not a good fit for our team. Agile I II books Remember, Don’t try to follow all the “rules” blindly. Tweak your approach the way it best suits your purpose but honestly, if you are tweaking it too much… Probably you didn’t get something right. agile is supposed to be agile! I’ll cover the topics that I found more important for me and our team but it doesn’t mean you’ll face the exact same issues. If you’re facing some other kind of issue feel free to reach me, maybe I can help you out. teams Cross functional In part (section “Development team”) I’ve said that dev teams should be . That titles and roles must be removed and the mindset is . This means, there’s no “back-end” nor “front-end developer”. II cross functional “I’m a team member who is responsible for delivering this work and I cannot do it alone” Ok, I get it. The goal is to everyone to be capable of delivering an user story autonomously with no “hands-off”. This would make things much simpler to manage but… It doesn’t work for us. We’ve tried in the first sprints and it was a mess. We’re currently working in a new mobile application using which is and in the server side we have an API built with Java. I must say that me and Java don’t “hold hands down the road” and this is valid both for me as for other front-end developers in the team, and the same can be said about our back-end developers and JavaScript, more specifically React in this case. React Native JavaScript So… cross-functionality… We would be affecting severely our team’s performance/velocity if we all tried to develop both the back and front end. But we decided to give it a try. We’ve built 2 Scrum teams with 5 developers each (3 JS skilled and 2 Java skilled devs), keeping Java developers focused on back-end matters and JS developers on front. But it didn’t take much time to fail… The first grooming sessions were just… bad. How could I give an estimation about a back-end task? They already have tons of modules and services that they can reuse, different SQL and Mongo databases and I know nothing about them. How can I know the effort to accomplish a certain story? And how can they measure a front-end task? They don’t know React, probably never heard about Redux until the beginning of this project and we have to build a very modular architecture to support multiple brands and customisations, something they never did. There’s just too much to learn in both sides, it would be irresponsible to keep with the “cross-functional” mindset. So we rearranged these 2 teams and now one is the front-end team and the other is the back-end. Each one has its own stories and sprint backlogs. This makes team management much harder to do, because Scrum Masters and Product owner have to keep syncing the two teams in order to follow the same path. We try the “back-end” team to be always one sprint ahead of the “front-end” team, so the front-end developers can consume the API and build their UIs. But this isn’t always true… Sometimes the items’ priority in the product backlog change and a new user story it putted on the top of the product backlog. This means that both teams will be working in this same story in the next sprint. In cases like these, one member of each dev team sit together for a couple of minutes and discuss what will be the “service signature”. They’ll define: The API endpoint The HTTP method The request data structure The response data structure (both for success and failure scenarios) Once this is defined, the front-end developer can mock the API’s response and build the UI. Once the back-end developments are closed the front-end developer only has to delete the mock and perform the . request DoD — Definition of done At this time I’m sure you’ll already know what DoD is. Simply a set of conditions that must be met so a certain story can be marked as done! Here’s an example of DoD: Meet linter rules Test coverage above 80% Code review UX review Documentation So far, so good, right? Nothing wrong here. But how do you make sure that all these conditions are actually met? Based on the reviewer(s) approval? At the beginning we would say “Sure. That’s exactly why we have pull requests and code review”. Well… Today I’m not so sure about it. Ok, the reviewer(s) has an important role here, he’s the man who has the final word, “Merged or condemned!” but we can make his life a little easier. We’ve made it introducing . Now, no one can perform a with linter issues and with a test coverage below 80% is not possible (unless you force it to). (Besides this, we’ll start also to validate commit messages in order to achieve a cleaner git history and automatic change logs thanks to and ). git hooks git commit git push commitizen conventional-changelog This ensures the developer that at least these conditions are already met when performing the pull request and frees the reviewer of the checking the test coverage and linting. (I must confess, I’ve made more than one pull request with linting issues). Sprint target, story points, team velocity Ok, how do you define your ? Based on your . sprint target team velocity And how you define your ? Based on how much you usually accomplish in each sprint. team velocity story points And how much points have we achieved? Simple, grab all the stories marked as (DoD) sum it all together and there’s your velocity. ! done And no, “almost done” is not the same as “done” And here’s the problem we’ve faced. “ ” Hmmm, I have this story that only needs this tiny little change and it is done. Should I consider it in this sprint’s velocity? “ ” This story has 8 points, should I consider 6 points as done in this sprint and the remaining 2 shifts to the next one? These might be silly doubts but hey! Like I’ve said… I’m not a scrum guru, we’re just getting started. What we’ve found is that you keep record of the team’s velocity based on the velocity in the last N sprints. It is an average so… It doesn’t matter if the story is “almost done”. It doesn’t go into that sprint velocity, it shifts the whole 8 points into the next sprint and is marked as when it is in fact In terms of “the last N sprints average” you’ll get the exact same result. done done! What about outliers? That sprint that went terribly bad, or half the team was on vacations? How does this affects the team velocity? I believe we all have some of these. Christmas for instance, those 1 to 2 weeks where the office is almost empty. The velocity of that sprint will be terrible when compared with the previous one, right? So simply discard it. Don’t take it into account on the overall’s velocity. A single sprint in the past 2 or 3 months shouldn’t affect the velocity that badly, the goal of keeping the sprint velocity is to make estimations about “how much can we do until this date?”, or “how much time will it take until we achieve these goals?”. That “Christmas sprint” won’t help you to achieve a better estimation. Ok, team velocity? Check! But how about those guys in the office during the “Christmas sprint”? They still need a sprint target, a sprint review and retrospective. But we don’t have half the team in this sprint, does this means that the sprint target must be half of the previous ones? 70%, 60%? Well, I’m sure it is possible to manage, even with only half a team. But we thought “Hmmm… Maybe it is a little overwhelming to have all this in this sprint”. So we’ve changed our strategy a little. For that specific sprint we’ll just forget Scrum! That’s right. No sprint planning and no sprint target. We’ll follow this time and we’ll see how it goes. Dev team members simply go to the product backlog and grab one of the stories on the top of it. As simple as that. kanban Potentially shippable product and CI/CD Yeah… The potentially shippable product (PSP) is that that you must achieve in the end of each sprint. And when I say “working version” I mean it! “Bug free” and ready to be deployed in production! But how to achieve it? working version To achieve an agile environment the most important thing you need is definitely an healthy mindset, people trusting and believing in it. But you also need some tools to help you on your day-to-day work. And one of these tools that I would consider indispensable to achieve your PSP would be a setup. Continuous Integration/Continuous Delivery (CI/CD) There is much to talk about CI/CD but I will not go in much detail. In fact, if you’re curious about how to perform a simple setup for a web project you can take a look at “ ”. CI/CD with GitHub, Travis CI and Heroku Our CI/CD is a little different from the one presented in the above mentioned article since it is a mobile application (both Android and iOS using ) but in the end of the day what we have is a setup that: React Native Clones the project (git) Performs linting and tests (if it fails the delivery is not done) Builds the project Publish it (the “delivery”) This enables us to have our project delivered at the end of each sprint. This delivery always happens in a “Demo” environment and only goes to production when the Product Owner decides to. The thing is… Does unit, integration and end2end tests ensure that our new version is really a PSP? It helps for sure but the answer would be “No”. You need quality assurance (QA). Until today what we had in the company was a development period followed by a “certification” period where bug fixes may happen. This doesn’t fit with agile, with our new “Sprint” approach. So the goal is to have someone who follows the team development during the sprint and writes and performs acceptance tests, this can be a QA specialised guy (preferred) or even a dev team member. The important is to be someone who didn’t participate on that development. In our team we aim to have a QA specialised guy but this is still a WIP. These were the biggest issues that we’ve faced these last months. We are only starting with Scrum but I believe we’re doing ok. The purpose of the articles is not only to show you what Scrum is and how to implement it. It is also for me to have the opportunity of hearing from you. Maybe I’m doing something wrong, or there’s a better way to deal with some specific issue. My hope in this cases is to have your feedback and to have the opportunity to learn and to make our environment a little better every day. Hope these articles have helped you in some way. (In case you’ve missed it, here’s part and ). I II Thank you , , Rúben Freitas and for your input on this one! Aurélio Pita Diogo Cardoso TRS