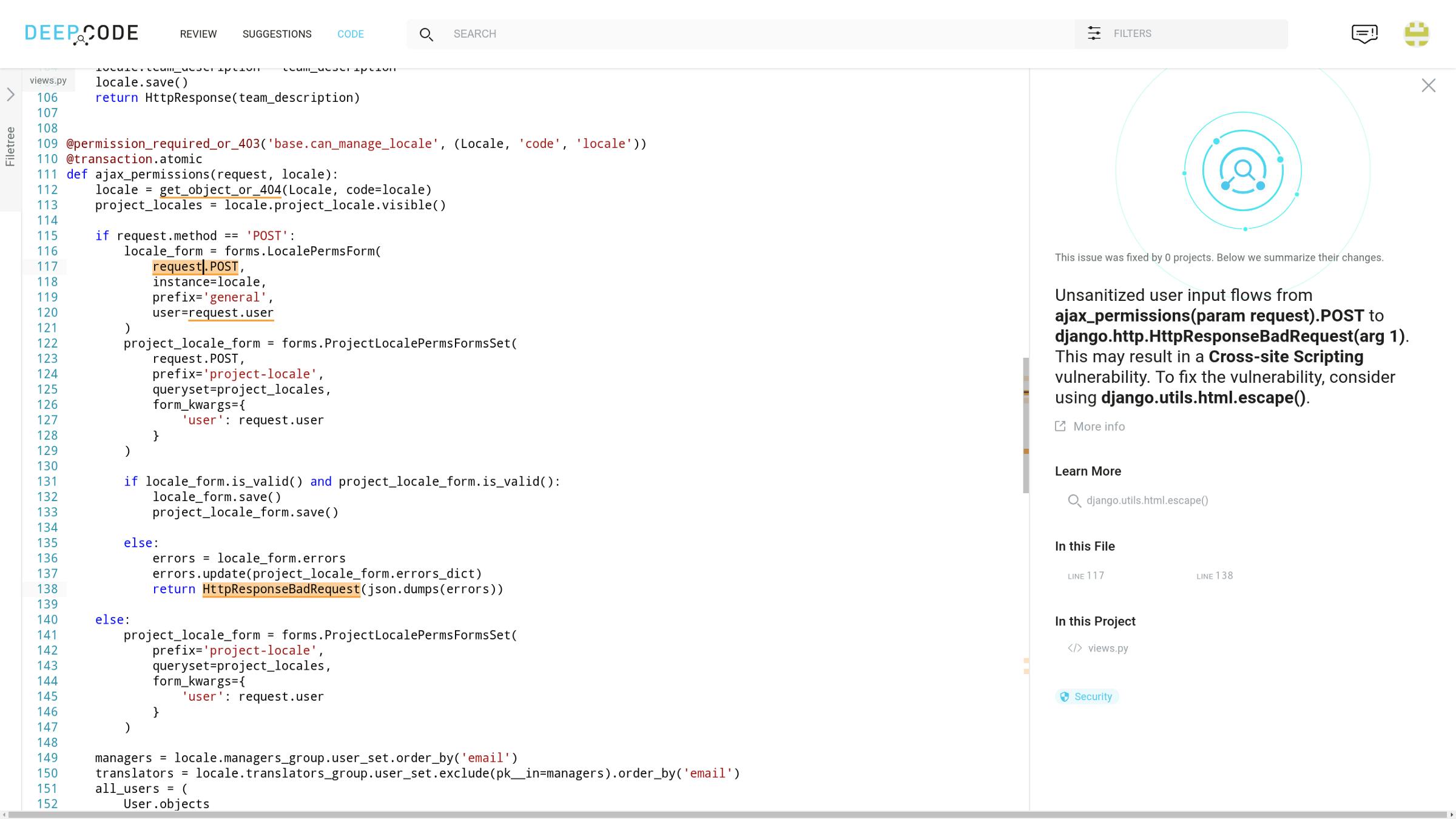
TL;DR In January 2019 we released a tool that significantly raises the bar for detecting security vulnerabilities in Python code. We built a fully automated system that couples data flow analysis algorithms with a novel ML component and detects many more new security issues than traditional approaches. After running it on several Open Source repositories, we found and reported 35 critical security vulnerabilities from the list. Here’s a motivating screenshot that shows one of them: OWASP Top Ten One of the XSS vulnerabilities that we found and reported The interest towards Information Security and, in particular Web Applications security, is steadily growing over the past years. Unfortunately so does the threat level posed by security vulnerabilities that are silently awaiting to be exploited by attackers. This fact obviously puts an additional burden on developers’ shoulders, which a code review tool relieve. That is why we decided to make a big push to improve detection of security issues. This blog post covers how we did it. must When it comes to detecting all these scary vulnerabilities like Cross-Site Scripting (XSS), SQL Injection (SQLi), Path Traversal (PT), Remote Code Execution (RCE), etc. probably the most used code analysis technique is called . I guess its popularity comes from the simplicity of the core idea, which very simply put sounds like: “check that all user input is properly escaped before it reaches a critical (from the security point of view) piece of code ”. Taint Analysis So, if I ask you to exploit this super-complicated snippet of code and you think “hmm, user input from the HTTP request gets into the variable and then into the call, so if I set it to , then will get executed in victim’s browser”, then you already know how it works. If not, here’s an informal description of the technique in less than a hundred words. name django.http.HttpResponse <script>evil_code</script> evil_code Taint Analysis emphasizes three categories of objects (variables, function calls, etc.): — contain user input (e.g. ) Sources request.GET.get(“name”) — transform user input from unsafe to safe (e.g. ) Sanitizers django.utils.html.escape() — trigger security vulnerabilities if an attacker’s input reaches them (e.g. ) Sinks django.http.HttpResponse() The analysis validates that all data flows from a source to a sink pass through a sanitizer. If not, then each unsanitized flow is reported as a potential vulnerability. One of the main limitations of Taint Analysis is its dependence on the specification of sources, sinks and sanitizers. Such a specification has to be manually compiled by a “security expert”, who must be very familiar with both the project code base and all the used third party frameworks. Ideally, the expert would then write down all the sources, sinks and sanitizers present in the code and let the taint tool do its job. It is not hard to see that this approach has some obvious downsides. First, imagine how much work it is to manually assemble this security specification. One would have to go through tons of documentation and/or code of both the project and the frameworks. Now think of this famous quote by Larry Wall, which says that “laziness and impatience are two true virtues of a great programmer”, and feel some pity for the poor fellow assigned to the task. Second, each missed entity in the list is a potentially neglected vulnerability. Humans are notorious for making mistakes, especially when it comes to routine jobs like this. Can you trust the completeness of the obtained list? Third, this is not a one-time effort. This process has to be incrementally redone every time a framework gets updated or the project starts using a different one or its own code changes significantly. This considerably increases the cost of maintaining the project. Fourth, this approach does not scale. Each project and each framework are unique, which means that the security specifications can’t be 100% successfully reused. These four basically mean that the traditional approach will not work efficiently for a tool like our , that is run daily on thousands of different projects. We simply do not have an army of security consultants that would work on specifications for each project. Code Review We solved this problem the DeepCode way — we learned the answer from Open Source code. We built a system that analyzes publicly available code, collects stats about all encountered APIs, neatly combines them in a model and infers new sources, sinks and sanitizers in a fully automated way. It also predicts the vulnerability types for sinks and provides suggestions on which sanitizer to use to fix the issue. Clearly our new approach helps against limitations 1, 3 and 4 listed above. But what about the second (and main) one? To check the quality of our inferred specification, we exposed it to the ultimate challenge — a bug hunt. We ran the on multiple Open Source repositories hosted on GitHub. We specifically targeted web applications that are meant to be (or already are) used by multiple (honest and malicious) users. publicly available version of our analyzer This experiment resulted in the following list of vulnerabilities that were discovered and fixed. It also proved that our tool is capable of finding interesting, non-trivial and sometimes unexpected bugs. A more detailed description with cool examples deserves its own blog post, which will hopefully come out soon. So, for now let us just conclude with presenting the GitHub pull requests/issues we filed. (XSS = Cross-Site Scripting, SQLi = SQL Injection, PT = Path Traversal, RCE = Remote Code Execution) Multiple XSS in mozilla/pontoon Mutliple SQLi in earthgecko/skyline XSS in earthgecko/skyline XSS in DataViva/dataviva-site SQLi in DataViva/dataviva-site SQLi in lmfdb/LMFDB Multiple XSS in lmfdb/LMFDB Multiple XSS in gestorpsi/gestorpsi Multiple SQLi in sharadbhat/VideoHub RCE in UDST/urbansim Mutliple XSS in viaict/viaduct XSS in MLTSHP/mltshp Multiple XSS in kylewm/woodwind XSS in kylewm/silo.pub Multiple XSS in anyaudio/anyaudio-server SQLi in MinnPost/election-night-api PT in mitre/multiscanner SQLi in PadamSethia/shorty Curious to see how many vulnerabilities we can find in your project? Looking for CVEs in Open Source? Or simply not yet convinced that it works? Well, then see you at . P.S. https://www.deepcode.ai/