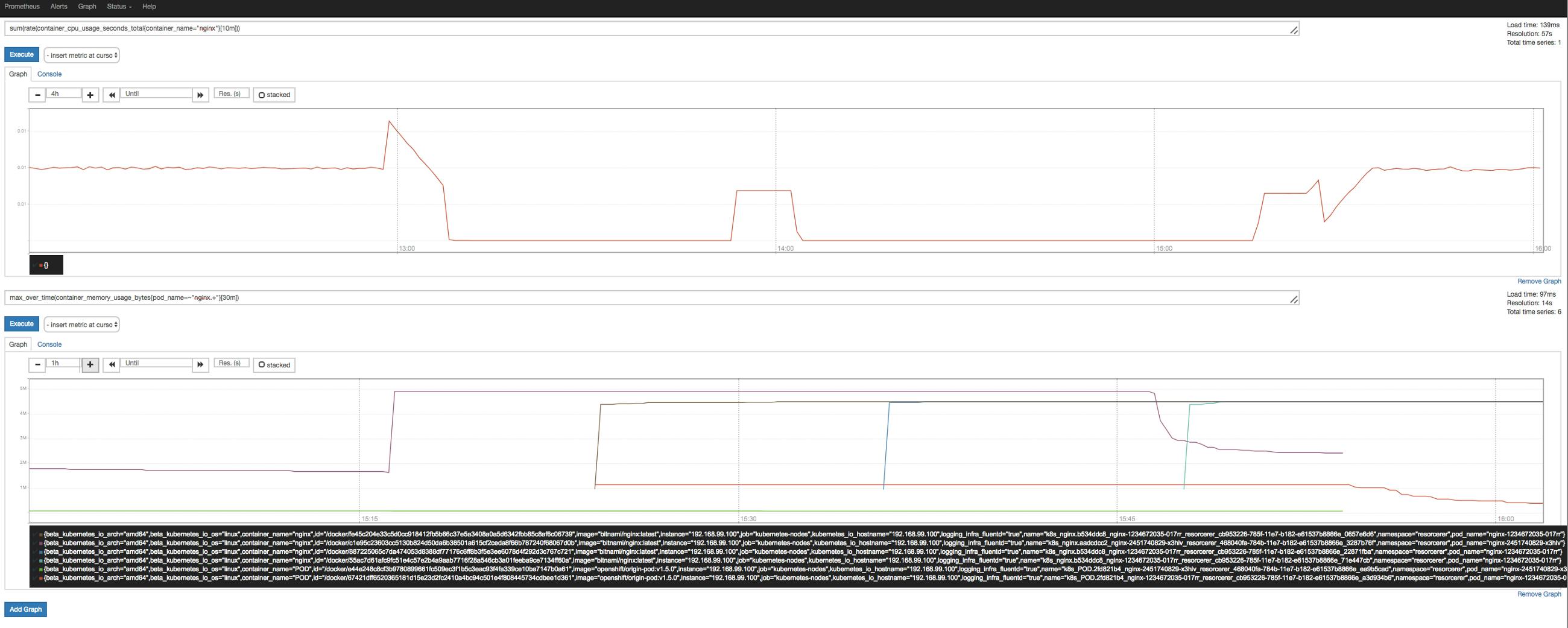
Couple of months ago, we were tackling challenges with scalability of system and were in pursuit of finding right orchestration tools which can help in scaling systems quickly. This draft is outline of things we have tried and learned along the way, most of things might sound familiar to you. A Quick glance of things we came across while building fleets on Kubernetes. We started exploring popular project managed by Google for orchestration management, for DevOps. Starting with two weeks of learning curves, we get our working staging system in (kubernetes in short) and did small working setup to visualize the power of this orchestration framework. Kubernetes kubes Microservices Microservice architectures have been trending because its architectural style aims to tackle the problems of managing modern application by decoupling software solutions into smaller functional services that are expected to fail. This help in quick recovery from failure on smaller functional units in contrast to making recovery from big monolithic software systems. Microservices helps in making your release cycle faster even because you will be focusing on smaller changes in single app instead of pushing code changes in bigger software systems that has multiple dependencies. Containers Microservice architectures got a big tide in 2013 when Docker inc. released Docker technology. gave perfect alternatives to virtual machines and drove software packaging methods in a more developer friendly way. Docker containers are comparatively smaller than virtual machines (VMs). It shares underlying host OS resources, we can spin up hundreds of these small units in order of milliseconds. Their smaller size helps in faster packaging, testing and even deployments because of its portable nature. Docker containers Docker’s container-based platform allows highly portable workloads. Docker containers can run on a developer’s local laptop, on physical or virtual machines in a data center, on cloud providers, or in a mixture of environments. We started with (GCE) to get things work quickly. We started with a cluster with few , each Node with configuration and in to run stateless components. Google Container Engine 10’s of Nodes 12 vCore 30 GB default pool Before going in depth, we need some (concepts/tools/theory) to onboard into container ship and sail out for cruise. gears We are dividing gears that we need to know into two parts, i.e. first will be and second will focused on . Docker Kubernetes Part — I (Understanding Docker at Dock) Stateless and stateful components In computing, a stateless protocol is a communication protocol in which no information is retained by either sender or receiver. The sender transmits a packet to the receiver and does not expect an acknowledgment of receipt. A UDP connection-oriented session is a stateless connection because neither systems maintains information about the session during its life.In contrast, a protocol that requires keeping of the internal state on the server is known as a stateful protocol. A TCP connection-oriented session is a ‘stateful’ connection because both systems maintain information about the session itself during its life. Understanding containerization concept Container provides operating system-level virtualization through a virtual environment that has its own process and network space, instead of creating a full-fledged virtual machine . This enables the kernel of an operating system to allow the existence of multiple isolated user-space instances, instead of just one. (https://en.wikipedia.org/wiki/Virtual_machine) Writing good Dockerfile for modules Dockerfile is set of instructions used by Docker to build an image. Containers are created using docker images, which can be built either by executing commands manually or automatically through Dockerfile. Docker achieves this by creating safe, LXC (i.e. Linux Containers) based environments for applications called “ ”. docker containers * Writing optimized Dockerfile, understanding order of commands. Each command that we run in Dockerfile is executed as a layer and subsequent command will be build on top of previous layer. Each layer is managed in cache by Docker tool. Docker manages cache itself to reuse layer of previously build Docker images to save time & disk. “one process per container” is frequently a good rule of thumb, it is not a hard and fast rule. Running a single process inside a Docker container Use your best judgment to keep containers as clean and modular as possible. Understanding remote for storing/pushing our locally built docker images, here we have used (GCR) for docker image management. Docker container registry Google container registry Pushing and Pulling Images to GCR ( ) Push images to Docker Cloud ( ) https://cloud.google.com/container-registry/docs/pushing-and-pulling https://docs.docker.com/docker-cloud/builds/push-images/ Part — II ( Understanding Kubernetes in Ocean ) Learning basics of kubernetes & work flow training Kubernetes is an open-source platform for automating deployment, scaling, and operations of application containers across clusters of hosts, providing container-centric infrastructure — Kubernetes.io What are Pods ? How container runs inside a pod? * Pods are the atomic unit on the Kubernetes platform. A Pod is a Kubernetes abstraction that represents a group of one or more application containers (such as Nginx or redis), and some shared resources for those containers. Pod Overview : Images by Kubernetes.io What are Nodes ? (also known as worker or minion) * A Pod always runs inside a Node. A Node is a worker machine in Kubernetes and may be either a virtual or a physical machine, depending on the cluster. Node is controlled by Kubernetes Master. Kubernetes manages scheduling of pods in Nodes running in a cluster. Node Overview : Images by Kubernetes.io What are Deployments ? * We use Deployments to create new resources, or replace existing ones by new ones by means of configuration defined. You can think of it as a supervisor of pods management. What is replication controller and Replica sets ? * A ReplicationController and Replica Sets ensures that a specified number of pod “replicas” are running at any one time. In other words, it makes sure that a pod or homogeneous set of pods are always up and available. If there are too many pods, it will kill some. If there are too few, it will start more. In above file, you can see keyword, this is being managed by replication utility. yaml replicas What is Kubernetes master ? * The controlling services in a Kubernetes cluster are called the master, or control plane, components. For example, master components are responsible for making global decisions about the cluster (e.g., scheduling), and detecting and responding to cluster events (e.g., starting up a new pod when a replication controller’s ‘replicas’ field is unsatisfied). Kubernetes provides a REST API supporting primarily CRUD operations on (mostly) persistent resources, which serve as the hub of its control plane. Kubernetes Ecosystem consists of mutiple components . What are services ? * A Kubernetes Service is an abstraction which defines a logical set of Pods and a policy by which to access them. The set of Pods targeted by a Service is (usually) determined by a Label Selector. Service keep on looking for pods which has specific labels assigned and keep tracks of those pods for request offloading. Service Overview : Images by Kubernetes.io How to debug or get cluster info from command-line ? * is a command line interface for running commands against Kubernetes clusters. kubectl How do we run containers in GCE ? We have number of which manages scaling pods up/down depending upon processing that we need. run containers inside available in a cluster. We need to follow proper versioning of modules to distinguish what is running inside your system and this helps in rollback releases in case of issues in production. deployments Pods Node How about services/APIs we need to expose ? - There comes kubes . We have plenty of APIs we need to expose to outside world. To make it happen, we have couple of kube services exposed using tcp loadbalancer which has been assigned public IP. Internally, these services keeps on doing service discovery using to find pods and attach it to this service, pods having same label will be targeted by a service. Its same concept of how we manage loadbalancer on cloud, attach VMs to a loadbalancer to offload incoming traffic. services label selector Resources running inside Kube ship knows each other very well. Each services/pods can communicate by names assigned to each. Instead of using IPs (private) assigned to each of them, you can use names given as FQDN. It’s a good practise to use names instead of IPs because of dynamic nature of network resource allocation since resources get destroyed and created again in a container lifecycle management. Kube-DNS maintains all list of IPs internally assigned and helps finding resources by names. ? How to decide what resources you should allocate to your pods resources Each container has its own requirements of resources (ie, etc), there comes & in kubes. This helps in keeping your nodes healthy. Many times due to bad limits or not defining limits, your pods can go crazy at utilization. They might eat any of the sources and can lead to node starvation which makes the Node unhealthy and it goes in state due to resource exhaustion. We faced this multiple times at early stage but now we have fine tuned each pods’ resources based on its hunger behaviour. CPU, RAM, disk, network requests limits [Not Ready] How to define Node resources in kubernetes cluster? Depends on container type (which is running inside a ), you can define different . Suppose you have modules named ``` , and ``` , all of them needs ``` ``` each to run, then you can have to run them. In this case, i will allocate following config for my Node pool. pod Node pools Core.X Core.Y Core.Z 2 core, 2 GB Standard Node Pool - Name : Standard Pool — Pool Size : 2 — Node Config: 4 Core, 4 GB — Node Pool Resource : 8 Core, 8 GB — : 6 Core, 6 GB (75 % used Core & RAM) Utilization Now, lets say i have high memory eater modules. let call them ``` ``` , all of them needs ``` ``` each to run, then you need to run them. In this case, i will allocate different config for my Node pool. Mem.X, Mem.Y and Mem.Z 0.5 core, 4 GB High memory Node Pool - Name : HighMem Pool- Pool Size : 2- Node Config : 1 Core, 8 GB- Node Pool Resource : 2 Core, 16 GB- : 1.5 Core, 12 GB (75 % used Core & RAM) Utilization So, based on your Node pool type ( ), you can deploy your pods in different Node pools by using nodeSelector in kubes. https://cloud.google.com/container-engine/docs/node-pools How we monitor Kubernetes ? We can run custom monitoring setup to keep an eye on Nodes. You can run [heapster]( ), ie. responsible for compute resource usage analysis and monitoring of container clusters, hooked with [influxdb]( ) that consumes reporting pushed by heapster and can be visualized in [grafana]( ). https://github.com/kubernetes/heapster https://github.com/influxdata/influxdb https://grafana.com/ Monitoring in Grafana Some configuration in GCE should be taken care, like . If you are running RabbitMQ, Redis or any other message queue as service that needs uptime, better you turn off autoupgrade because kubernetes new version release will schedule all your node for maintenance, however it rolles updates one by one but could affect your production system. Else, if you are fully stateless, you can keep default or skip this warning! Note : autoupgrade kubernetes version https://cloud.google.com/container-engine/docs/node-auto-upgrade gcloud beta container node-pools update <NODEPOOL> — cluster <CLUSTER> — zone <ZONE> — no-enable-autoupgrade Pretty much all above understandings are based on what I learned in last six months of kubernetes running in production. Container management is easy to adapt and lot of new observation is yet to be discovered as we go along the way. Looking at deployments today, Kubernetes is absolutely fantastic in Auto-pilot and doing self-healing jobs itself. We are running more than in cluster together and processing and are pushing more to handle. 1000 pods 10’s of Billions of API calls per month Conclusion : Kubernetes has lifted lot of server management and helped in faster depployments & scaling system. Adaptability is much quicker, most of security and other concerns is being managed by Google. Kubernetes aims to offer a better orchestration management system on top of clustered infrastrcuture. Development on Kubernetes has been happening at storm-speed, and the community of Kubernauts ( https://kubernetes.io/community/ ) has grown bigger. D aemon Blog : https://sunnykrgupta.github.io/managing-fleet-on-kubernetes.html _Posts and writings by Sunny KUMAR_sunnykrgupta.github.io Daemon Blog - Managing fleet on Kubernetes