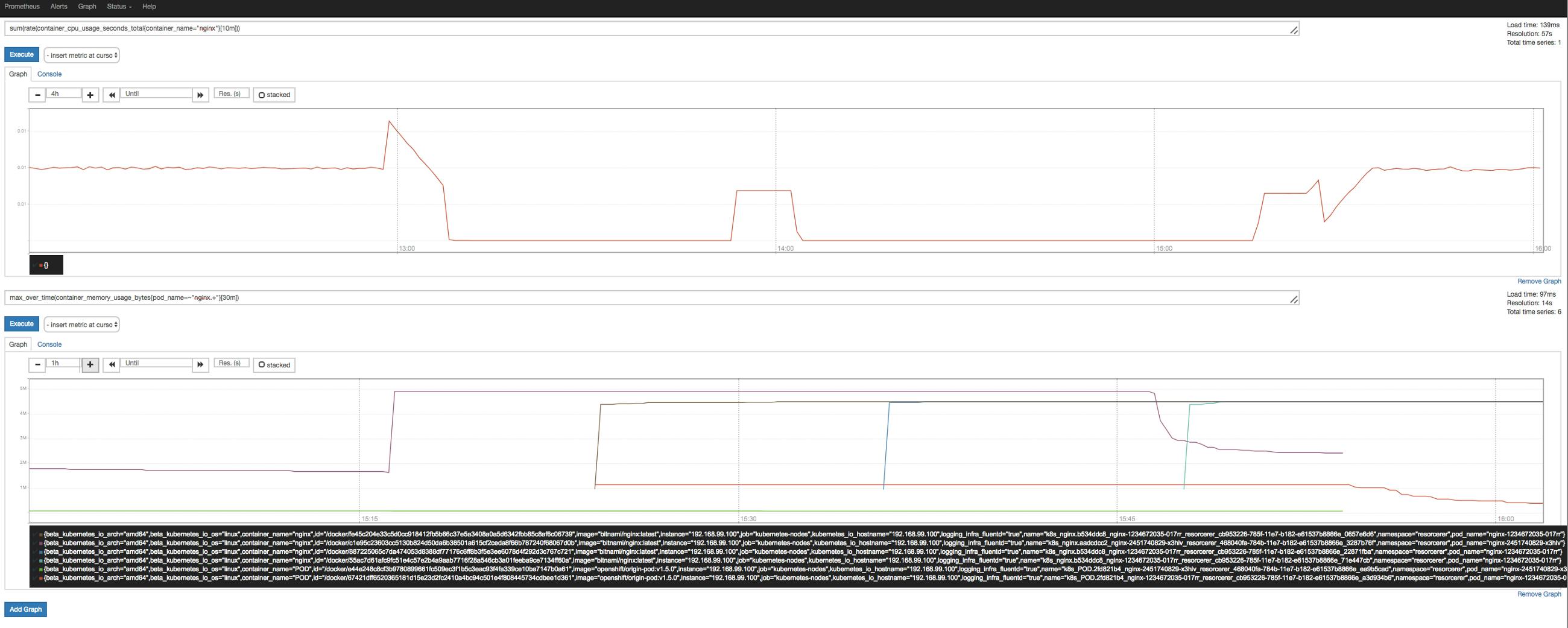
Quick question: do you know how much memory your app consumes? How about CPU time? What about spikes in the traffic? How do you deal with that in the context of the resource consumption? Are you managing the memory and CPU constraints per container manually? Or, maybe you’re not there, yet. Maybe this whole resource consumption and constraints thing is totally new to you. Read on. TL;DR: in Kubernetes it’s important that you set the CPU and memory resource requirements of your containers and we’re now about to automate this process. Why bother? Why indeed should you bother how much memory and CPU the containers in your Kubernetes cluster consume? Let’s see what practitioners have to say on this topic: Unfortunately, Kubernetes has not yet implemented dynamic resource management, which is why we have to set resource limits for our containers.I imagine that at some point Kubernetes will start implementing a less manual way to manage resources, but this is all we have for now. Ben Visser, 12/2016 in: Kubernetes — Understanding Resources Kubernetes doesn’t have dynamic resource allocation, which means that requests and limits have to be determined and set by the user. When these numbers are not known precisely for a service , a good approach is to start it with overestimated resources requests and no limit, then let it run under normal production load for a certain time: hours, days, weeks according to the nature of the service. Antoine Cotten, 05/2016 in: 1 year, lessons learned from a 0 to Kubernetes transition Now, it turns out that Google—in the context of —has such a resource consumption predictor/adjuster called , which does in fact offer an automatic resource consumption management. Borg autopilot Enter the person who brought this topic up at KubeCon 2016: , one of the early Kubernetes committers when it was still a Google-internal project: Tim Hockin As the wise Tim stated in his talk (also, check out the and the ): Everything You Ever Wanted To Know About Resource Scheduling slide deck video Some 2/3 of the Borg users use autopilot. This sounds quite convincing; way more than half of the Borg users seem to be happy to not only have the resource consumption set explicitly but also to delegate this job to autopilot. Back to Kubernetes. Already in mid-2015 we find that the Kubernetes community — informed by Google’s experience—raised an to capture the need for an automated resource consumption management. In early 2017 the according was completed and now the initial work on the resulting Vertical Pod Autoscaler ( ) is on its way. autopilot issue design proposal VPA A demonstrator: resorcerer To gather experience on the problem domain—assessing container resource consumption and adjusting the containers accordingly—we put together a POC, a demonstrator called . resorcerer Check out the for resorcerer where I show you how you can use it in a Kubernetes cluster (in a namespace, really), how it works and what the limitations are: video walkthrough A of resorcerer, its features and inner workings (~27min). video walkthrough Under the hood: heavy lifting is done by Prometheus To come up with recommendations for resource consumption limits, the resorcerer demonstrator leverages . For example, to determine the CPU usage of a certain container for the past 30 min, we can use the following PromQL query: Prometheus sum(rate(container_cpu_usage_seconds_total{pod_name=~"nginx.+", container_name="nginx"}[30m])) This will result in something like the following: Screen shot of Prometheus, showing container CPU usage over time. The tricky part here is to pick meaningful PromQL queries as well as the right parameter for the observation time period. For starters, think of three cases: —no load on the container, this is the of CPU/memory resources required. idle minimum amount —observing the container for a longer period of time (days or weeks) and figuring out the baseline; this is the of resources required to operate. normal typical case —think of an external event, for example a half-prize sales event or a mention in a popular news outlet, driving tons of traffic to your app; this is an exceptional case of resource consumption which you still want to be able to accommodate. spike In above case distinction we conveniently only considered the simple case of a stateless application such as an app server or Web server. Things do get considerably more complicated for stateful services, involving databases, for example. In the context of resorcerer, we’d like to thank for his support around Prometheus scraping and PromQL as well as , who helped navigating the tricky parts of the Kubernetes library. Julius Volz Stefan Schimanski client-go The road ahead The topic of container resource consumption is an important one and I hope with above I made a point that you should pay attention to it. In Kubernetes we’re at time of writing at the start of the journey and we need to gather more experience concerning automation of resource consumption management. The official work on the Kubernetes Vertical Pod Autoscalers (VPA) is ramping up now in the , so now is a good point in time to start contributing with use cases and/or sharing your requirements as well as experiences. You can join us on the community, #sig-autoscaling channel as well as participate via the or chime in on one of the taking place roughly every two weeks. SIG Autoscaling Kubernetes Slack mailing list Thursday online meetings