





















数字游民请注意:您需要了解泰国新推出的 DTV 签证


Jan 20, 1970

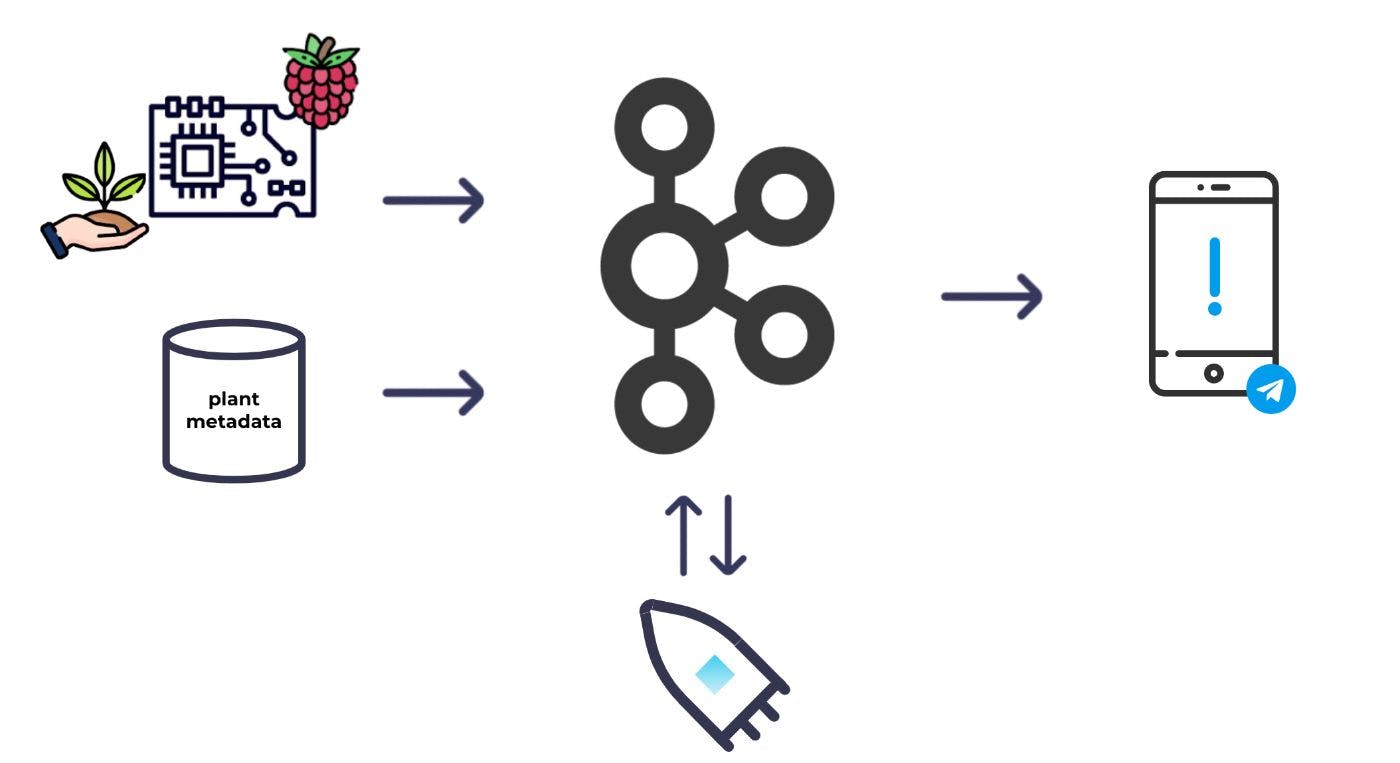
Come along to explore Apache Kafka and see how to get the most out of your event-driven pipelines!
Come along to explore Apache Kafka and see how to get the most out of your event-driven pipelines!
Come along to explore Apache Kafka and see how to get the most out of your event-driven pipelines!

Jan 20, 1970
Jan 20, 1970
Jan 20, 1970
Jan 20, 1970
Jan 20, 1970
Jan 20, 1970





