
1,901 чтения
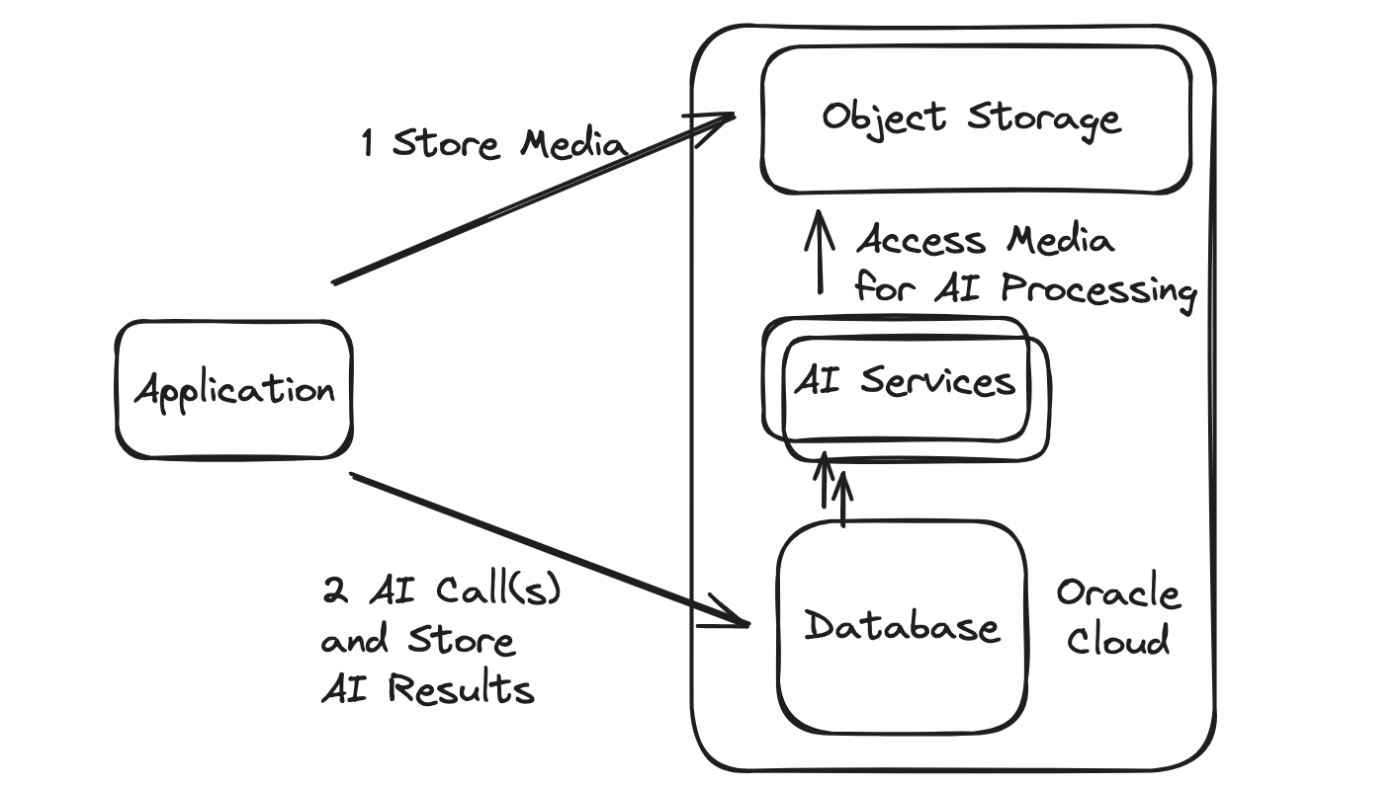
Как разрабатывать приложения ИИ, управляемые данными: руководство по созданию услуг ИИ непосредственно из базы данных
by byPaul Parkinson@paulparkinson
byPaul Parkinson@paulparkinson
Architect and Developer Advocate, Microservices with Oracle Database. XR Developer
2024/01/07


















Architect and Developer Advocate, Microservices with Oracle Database. XR Developer
Story's Credibility


Architect and Developer Advocate, Microservices with Oracle Database. XR Developer
Story's Credibility
About Author

Architect and Developer Advocate, Microservices with Oracle Database. XR Developer
КОММЕНТАРИИ












