
1,901 leituras
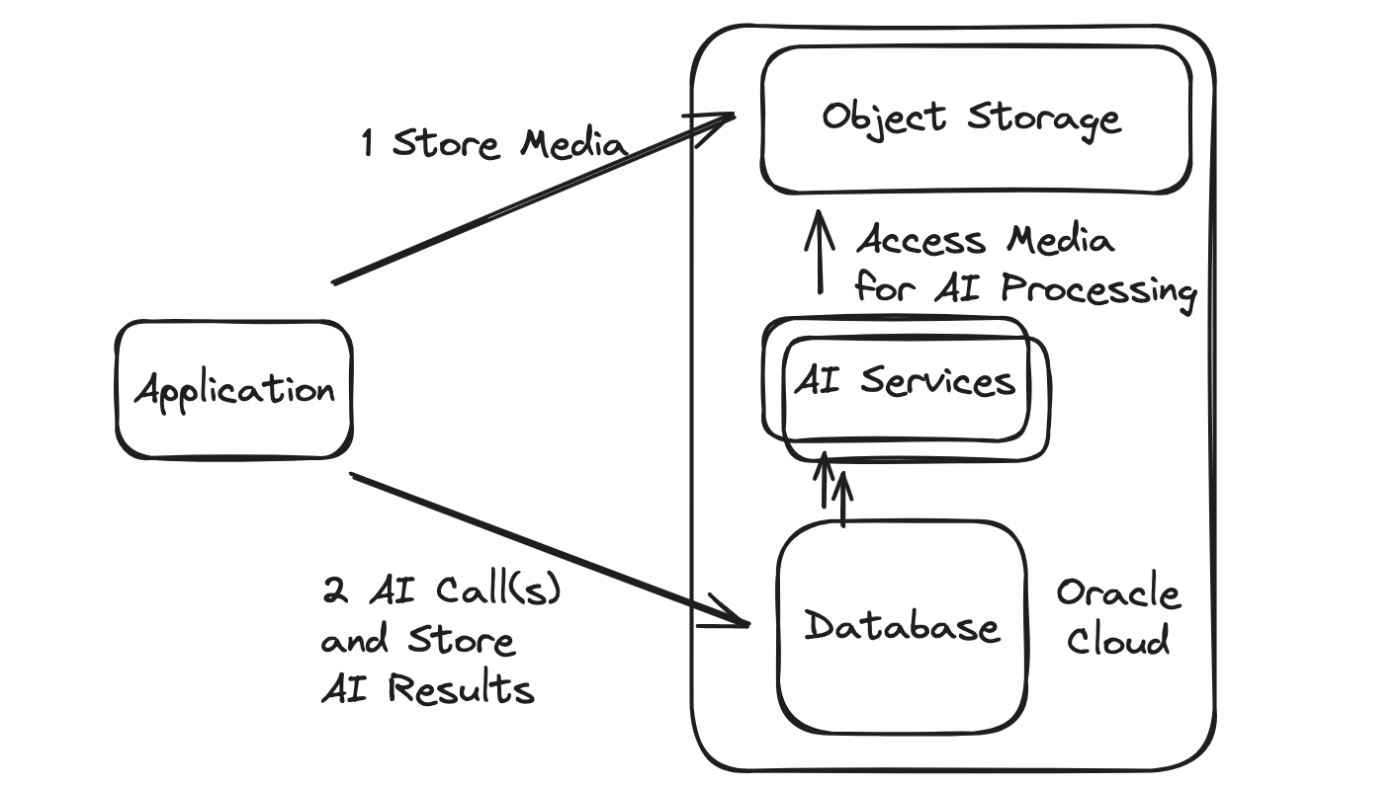
Como desenvolver aplicativos de IA baseados em dados: um guia para criar serviços de IA diretamente do banco de dados
by byPaul Parkinson@paulparkinson
byPaul Parkinson@paulparkinson
Architect and Developer Advocate, Microservices with Oracle Database. XR Developer
2024/01/07


















Architect and Developer Advocate, Microservices with Oracle Database. XR Developer
Story's Credibility


Architect and Developer Advocate, Microservices with Oracle Database. XR Developer
Story's Credibility
About Author

Architect and Developer Advocate, Microservices with Oracle Database. XR Developer
COMENTARIOS












