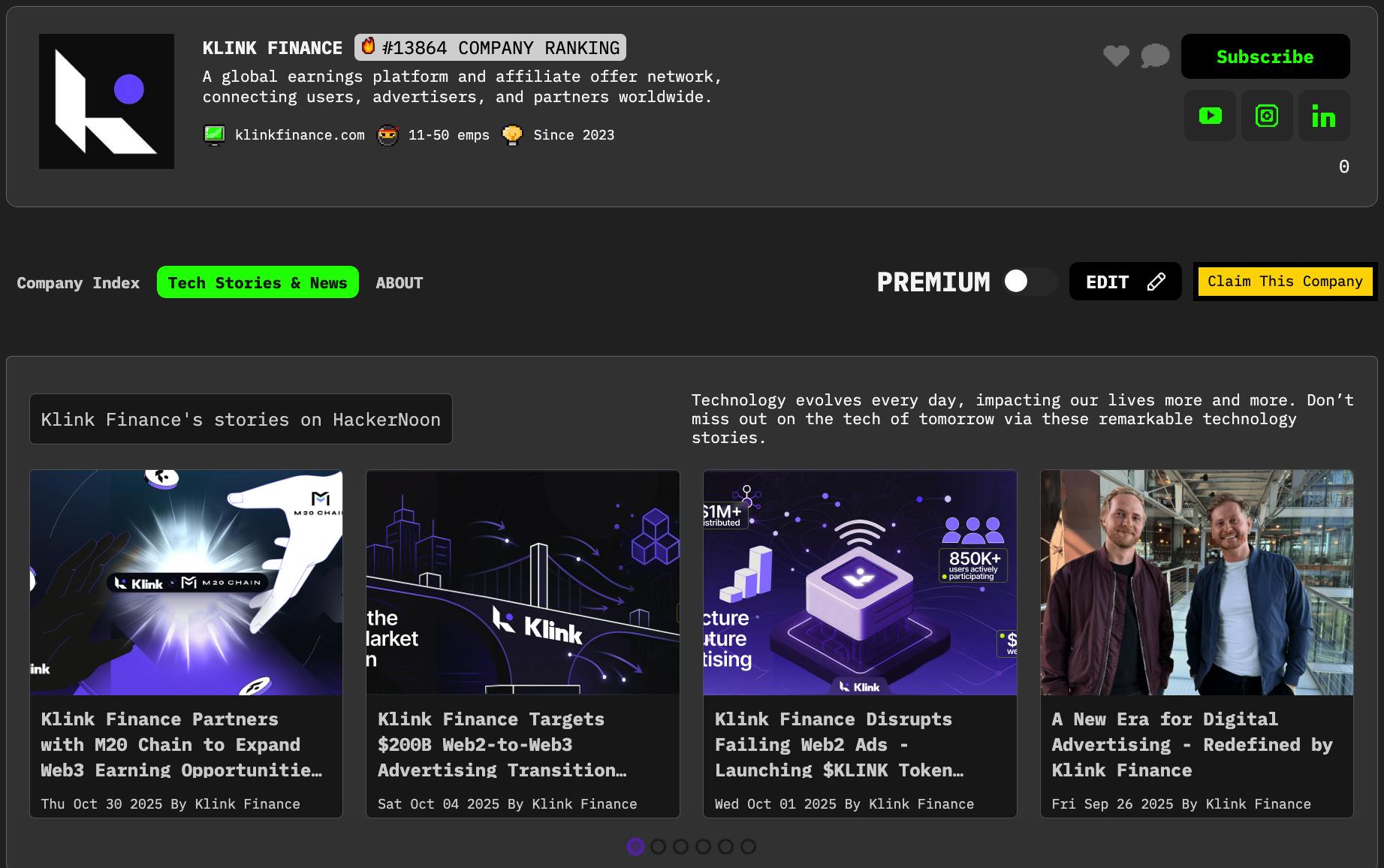
Jeśli sprawdzisz popularne testy porównawcze służące do pomiaru wydajności LLM, to prawdopodobnie odniesiesz wrażenie, że sztuczna inteligencja jest taaaka mądra. Na pierwszy rzut oka jest to dość powierzchowne wrażenie. Czy jednak sztuczna inteligencja rzeczywiście radzi sobie lepiej niż przeciętny człowiek w zadaniach poznawczych? Modele Frontier, takie jak o1 z OpenAI i Claude 3.5 Sonnet z Anthropic, działają lepiej niż eksperci w wielu dziedzinach, w tym w prawie, kodowaniu i matematyce. Dlaczego więc ChatGPT nie może rozwiązać prostych zadań z zakresu rozumowania przestrzennego lub głupich podchwytliwych pytań? Cóż, nadal mówimy o „dużych modelach językowych” — przyjmują mnóstwo liter i próbują przewidzieć, jakie litery wypluć dla danego zapytania. Zauważ, że nigdzie w tym równaniu nie wspomniano o rzeczywistym „myśleniu”. Modele są swego rodzaju , ponieważ próbują pobrać właściwe informacje ze swojego zestawu danych treningowych zamiast faktycznie rozważyć twoje pytanie. Przynajmniej tak było do czasu, aż OpenAI wydało o1-preview, ale więcej o tym później. stochastycznymi papugami Wśród tych, którzy zaczęli kwestionować istniejące benchmarki LLM pod kątem trafności, jest autor „AI Explained”, popularnego kanału YouTube, którego jestem wielkim fanem. Phillip (imię YouTubera) zauważył, że standardowe benchmarki branżowe mają jasny styl pytań, które są również w większości publicznie dostępne. Oznacza to, że nie tylko te dokładne pytania mogą być częścią zestawu danych treningowych, ale dzięki standaryzacji modelom łatwiej jest dostrzegać i stosować wzorce z ogólnych danych treningowych. Mówiąc prościej, badacze sztucznej inteligencji, którzy tworzą przełomowe i złożone technologie, z pewnością znajdą sposób, aby nadać swojemu modelowi odpowiednie pytania i odpowiedzi, które będzie mógł „zapamiętać” przed przeprowadzeniem testów porównawczych. Patrząc na wyniki najlepszego dostępnego modelu, o1 z OpenAI, można wnioskować, że w wielu profesjonalnych dziedzinach osiąga on wyniki powyżej średniej. I to prawda, ale wynik ten opiera się na dostępności odpowiednich danych szkoleniowych i wcześniejszych przykładach z tych konkretnych dziedzin. Nie zrozumcie mnie źle, modele są teraz niesamowite w udzielaniu podręcznikowych odpowiedzi na pytania podręcznikowe, a to samo w sobie jest niesamowicie imponujące. Termin „sztuczna inteligencja” oznacza jednak coś więcej niż tylko wyszukiwanie informacji; powinno być w to zaangażowane pewne myślenie. Tak więc logicznym następstwem wszystkich imponujących liczb powyżej jest to, czy taka „AI” może odpowiedzieć na trudne pytanie dotyczące rozumowania. Czy ma jakąś inteligencję przestrzenną? Albo czy potrafi dobrze poruszać się w typowych scenariuszach społecznych? Odpowiedź brzmi – czasami. W przeciwieństwie do pytań dotyczących konkretnej dziedziny, na które istnieją z góry określone odpowiedzi, problemy, które ludzie rozwiązują na co dzień, często wymagają zrozumienia kontekstu wykraczającego poza język naturalny (a to jedyna rzecz, którą mają studenci LLM). Powyżej znajdują się najlepsi wyniki testu porównawczego SIMPLE, który zadaje pytania LLM, które przeciętna osoba uznałaby za trywialne, ale modele niekoniecznie potrafią jeszcze odpowiedzieć. Przyzwyczailiśmy się do tego, że AI radzi sobie o wiele lepiej niż przeciętny człowiek na egzaminach lub specjalistycznych testach porównawczych, ale tutaj najlepsza wydajność modelu wynosi zaledwie 41,7% (o1-preview) w porównaniu z 83,7% przeciętnego człowieka. Ten test porównawczy wykorzystuje 200 pytań tekstowych wielokrotnego wyboru skupionych na rozumowaniu czasoprzestrzennym, inteligencji społecznej i pytaniach podchwytliwych. Najważniejszą cechą benchmarku jest to, że te pytania nie są publicznie dostępne, więc laboratoria AI nie mogą po prostu dodać ich do swoich danych treningowych. Możesz dowiedzieć się więcej o tym benchmarku . tutaj To nowe podejście do pomiaru wydajności LLM pokazuje, jak daleko wszystkie modele wciąż są od przeciętnej zdolności rozumowania ludzkiego. Im szybciej ta luka się zamknie w nadchodzących miesiącach, tym bardziej definitywna stanie się odpowiedź „tak” na nasz tytuł. Interesująca nowa miara, na którą warto zwrócić uwagę, jeśli jesteś entuzjastycznie nastawiony, ale ostrożny w kwestii AI.