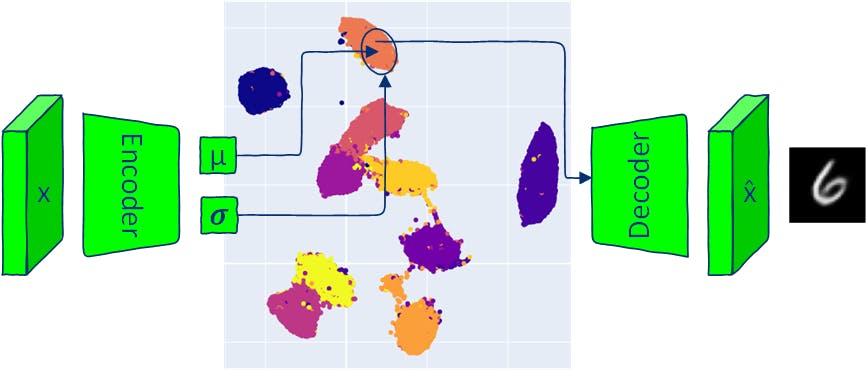
기존 자동 인코더와 마찬가지로 VAE 아키텍처는 인코더와 디코더라는 두 부분으로 구성됩니다. 기존 AE 모델은 입력을 잠재 공간 벡터에 매핑하고 이 벡터에서 출력을 재구성합니다. VAE는 입력을 다변량 정규 분포로 매핑합니다(인코더는 각 잠재 차원의 평균과 분산을 출력합니다). VAE 인코더는 분포를 생성하므로 이 분포에서 샘플링하고 샘플링된 잠재 벡터를 디코더에 전달하여 새 데이터를 생성할 수 있습니다. 생성된 분포에서 샘플링하여 출력 이미지를 생성한다는 것은 VAE가 입력 데이터와 유사하지만 동일한 새로운 데이터를 생성할 수 있음을 의미합니다. 이 기사에서는 VAE 아키텍처의 구성 요소를 살펴보고 VAE 모델을 사용하여 새 이미지(샘플링)를 생성하는 여러 가지 방법을 제공합니다. 모든 코드는 에서 사용할 수 있습니다. Google Colab 1 VAE 모델 구현 자동 인코더와 변형 자동 인코더는 모두 인코더와 디코더라는 두 부분으로 구성됩니다. AE의 인코더 신경망은 각 이미지를 잠재 공간의 단일 벡터로 매핑하는 방법을 학습하고 디코더는 인코딩된 잠재 벡터에서 원본 이미지를 재구성하는 방법을 학습합니다. VAE의 인코더 신경망은 잠재 공간의 각 차원에 대한 확률 분포(다변량 분포)를 정의하는 매개변수를 출력합니다. 각 입력에 대해 인코더는 잠재 공간의 각 차원에 대한 평균과 분산을 생성합니다. 출력 평균과 분산은 다변량 가우스 분포를 정의하는 데 사용됩니다. 디코더 신경망은 AE 모델과 동일합니다. 1.1 VAE 손실 VAE 모델 교육의 목표는 제공된 잠재 벡터에서 실제 이미지를 생성할 가능성을 최대화하는 것입니다. 훈련 중에 VAE 모델은 두 가지 손실을 최소화합니다. - 입력 이미지와 디코더 출력 간의 차이입니다. 재구성 손실 (KL Divergence는 두 확률 분포 사이의 통계적 거리) - 인코더 출력의 확률 분포와 사전 분포(표준 정규 분포) 사이의 거리로, 잠재 공간을 정규화하는 데 도움이 됩니다. Kullback–Leibler 발산 손실 1.2 재건 손실 일반적인 재구성 손실은 BCE(이진 교차 엔트로피)와 MSE(평균 제곱 오류)입니다. 이 글에서는 데모를 위해 MNIST 데이터세트를 사용하겠습니다. MNIST 이미지에는 채널이 하나만 있으며 픽셀은 0과 1 사이의 값을 갖습니다. 이 경우 BCE 손실을 재구성 손실로 사용하여 MNIST 이미지의 픽셀을 베르누이 분포를 따르는 이진 확률 변수로 처리할 수 있습니다. reconstruction_loss = nn.BCELoss(reduction='sum') 1.3 쿨백-라이블러 발산 위에서 언급했듯이 KL 발산은 두 분포 간의 차이를 평가합니다. 거리에 대한 대칭 속성이 없다는 점에 유의하십시오: KL(P”Q)!=KL(Q”P). 비교해야 할 두 가지 분포는 다음과 같습니다. 입력 이미지 x가 주어지면 인코더 출력의 잠재 공간: q(z|x) 잠재 공간 이전 는 각 잠재 공간 차원 에서 평균이 0이고 표준 편차가 1인 정규 분포로 가정됩니다. p(z) N(0, ) I 이러한 가정은 KL 발산 계산을 단순화하고 잠재 공간이 알려진 관리 가능한 분포를 따르도록 장려합니다. from torch.distributions.kl import kl_divergence def kl_divergence_loss(z_dist): return kl_divergence(z_dist, Normal(torch.zeros_like(z_dist.mean), torch.ones_like(z_dist.stddev)) ).sum(-1).sum() 1.4 인코더 class Encoder(nn.Module): def __init__(self, im_chan=1, output_chan=32, hidden_dim=16): super(Encoder, self).__init__() self.z_dim = output_chan self.encoder = nn.Sequential( self.init_conv_block(im_chan, hidden_dim), self.init_conv_block(hidden_dim, hidden_dim * 2), # double output_chan for mean and std with [output_chan] size self.init_conv_block(hidden_dim * 2, output_chan * 2, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=4, stride=2, padding=0, final_layer=False): layers = [ nn.Conv2d(input_channels, output_channels, kernel_size=kernel_size, padding=padding, stride=stride) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] return nn.Sequential(*layers) def forward(self, image): encoder_pred = self.encoder(image) encoding = encoder_pred.view(len(encoder_pred), -1) mean = encoding[:, :self.z_dim] logvar = encoding[:, self.z_dim:] # encoding output representing standard deviation is interpreted as # the logarithm of the variance associated with the normal distribution # take the exponent to convert it to standard deviation return mean, torch.exp(logvar*0.5) 1.5 디코더 class Decoder(nn.Module): def __init__(self, z_dim=32, im_chan=1, hidden_dim=64): super(Decoder, self).__init__() self.z_dim = z_dim self.decoder = nn.Sequential( self.init_conv_block(z_dim, hidden_dim * 4), self.init_conv_block(hidden_dim * 4, hidden_dim * 2, kernel_size=4, stride=1), self.init_conv_block(hidden_dim * 2, hidden_dim), self.init_conv_block(hidden_dim, im_chan, kernel_size=4, final_layer=True), ) def init_conv_block(self, input_channels, output_channels, kernel_size=3, stride=2, padding=0, final_layer=False): layers = [ nn.ConvTranspose2d(input_channels, output_channels, kernel_size=kernel_size, stride=stride, padding=padding) ] if not final_layer: layers += [ nn.BatchNorm2d(output_channels), nn.ReLU(inplace=True) ] else: layers += [nn.Sigmoid()] return nn.Sequential(*layers) def forward(self, z): # Ensure the input latent vector z is correctly reshaped for the decoder x = z.view(-1, self.z_dim, 1, 1) # Pass the reshaped input through the decoder network return self.decoder(x) 1.6 VAE 모델 무작위 샘플을 통해 역전파하려면 매개변수를 통한 기울기 계산을 허용하기 위해 무작위 샘플의 매개변수( 및 𝝈)를 함수 외부로 이동해야 합니다. 이 단계를 "재매개변수화 트릭"이라고도 합니다. μ PyTorch에서는 인코더의 출력 및 𝝈로 분포를 생성하고 재매개변수화 트릭을 구현하는 메서드를 사용하여 샘플링할 수 있습니다. 이는 μ 정규 rsample() torch.randn(z_dim) * stddev + mean) class VAE(nn.Module): def __init__(self, z_dim=32, im_chan=1): super(VAE, self).__init__() self.z_dim = z_dim self.encoder = Encoder(im_chan, z_dim) self.decoder = Decoder(z_dim, im_chan) def forward(self, images): z_dist = Normal(self.encoder(images)) # sample from distribution with reparametarazation trick z = z_dist.rsample() decoding = self.decoder(z) return decoding, z_dist 1.7 VAE 교육 MNIST 열차 및 테스트 데이터를 로드합니다. transform = transforms.Compose([transforms.ToTensor()]) # Download and load the MNIST training data trainset = datasets.MNIST('.', download=True, train=True, transform=transform) train_loader = DataLoader(trainset, batch_size=64, shuffle=True) # Download and load the MNIST test data testset = datasets.MNIST('.', download=True, train=False, transform=transform) test_loader = DataLoader(testset, batch_size=64, shuffle=True) 위 그림에 시각화된 VAE 훈련 단계를 따르는 훈련 루프를 만듭니다. def train_model(epochs=10, z_dim = 16): model = VAE(z_dim=z_dim).to(device) model_opt = torch.optim.Adam(model.parameters()) for epoch in range(epochs): print(f"Epoch {epoch}") for images, step in tqdm(train_loader): images = images.to(device) model_opt.zero_grad() recon_images, encoding = model(images) loss = reconstruction_loss(recon_images, images)+ kl_divergence_loss(encoding) loss.backward() model_opt.step() show_images_grid(images.cpu(), title=f'Input images') show_images_grid(recon_images.cpu(), title=f'Reconstructed images') return model z_dim = 8 vae = train_model(epochs=20, z_dim=z_dim) 1.8 잠재 공간 시각화 def visualize_latent_space(model, data_loader, device, method='TSNE', num_samples=10000): model.eval() latents = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): if len(latents) > num_samples: break mu, _ = model.encoder(data.to(device)) latents.append(mu.cpu()) labels.append(label.cpu()) latents = torch.cat(latents, dim=0).numpy() labels = torch.cat(labels, dim=0).numpy() assert method in ['TSNE', 'UMAP'], 'method should be TSNE or UMAP' if method == 'TSNE': tsne = TSNE(n_components=2, verbose=1) tsne_results = tsne.fit_transform(latents) fig = px.scatter(tsne_results, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with TSNE', width=600, height=600) elif method == 'UMAP': reducer = umap.UMAP() embedding = reducer.fit_transform(latents) fig = px.scatter(embedding, x=0, y=1, color=labels, labels={'color': 'label'}) fig.update_layout(title='VAE Latent Space with UMAP', width=600, height=600 ) fig.show() visualize_latent_space(vae, train_loader, device='cuda' if torch.cuda.is_available() else 'cpu', method='UMAP', num_samples=10000) 2 VAE를 사용한 샘플링 VAE(Variational Autoencoder)에서 샘플링하면 교육 중에 표시되는 것과 유사한 새로운 데이터를 생성할 수 있으며 이는 VAE를 기존 AE 아키텍처와 구분하는 고유한 측면입니다. VAE에서 샘플링하는 방법에는 여러 가지가 있습니다. 제공된 입력이 주어진 사후 분포에서 샘플링합니다. 사후 샘플링: 표준 정규 다변량 분포를 가정하여 잠재 공간에서 샘플링합니다. 이는 잠재 변수가 정규 분포를 따른다는 가정(VAE 훈련 중에 사용됨)으로 인해 가능합니다. 이 방법은 특정 속성을 가진 데이터 생성(예: 특정 클래스에서 데이터 생성)을 허용하지 않습니다. 사전 샘플링: : 잠재 공간의 두 점 사이의 보간은 잠재 공간 변수의 변화가 생성된 데이터의 변화에 어떻게 대응하는지를 밝힐 수 있습니다. 보간(interpolation) : traversing latent Dimensions of VAE 데이터의 잠재 공간 분산은 각 차원에 따라 다릅니다. 순회는 선택한 하나의 차원을 제외한 잠재 벡터의 모든 차원을 고정하고 해당 범위에서 선택한 차원의 값을 변경하여 수행됩니다. 잠재 공간의 일부 차원은 데이터의 특정 속성에 해당할 수 있습니다(VAE에는 해당 동작을 강제하는 특정 메커니즘이 없지만 발생할 수 있음). traversal of latent Dimensions 예를 들어, 잠재 공간의 한 차원은 얼굴의 감정 표현이나 물체의 방향을 제어할 수 있습니다. 각 샘플링 방법은 VAE의 잠재 공간에서 캡처한 데이터 속성을 탐색하고 이해하는 다양한 방법을 제공합니다. 2.1 후방 샘플링(주어진 입력 이미지로부터) def posterior_sampling(model, data_loader, n_samples=25): model.eval() images, _ = next(iter(data_loader)) images = images[:n_samples] with torch.no_grad(): _, encoding_dist = model(images.to(device)) input_sample=encoding_dist.sample() recon_images = model.decoder(input_sample) show_images_grid(images, title=f'input samples') show_images_grid(recon_images, title=f'generated posterior samples') posterior_sampling(vae, train_loader, n_samples=30) 사후 샘플링을 사용하면 변동성이 낮은 현실적인 데이터 샘플을 생성할 수 있습니다. 출력 데이터는 입력 데이터와 유사합니다. 2.2 사전 샘플링(무작위 잠재 공간 벡터에서) def prior_sampling(model, z_dim=32, n_samples = 25): model.eval() input_sample=torch.randn(n_samples, z_dim).to(device) with torch.no_grad(): sampled_images = model.decoder(input_sample) show_images_grid(sampled_images, title=f'generated prior samples') prior_sampling(vae, z_dim, n_samples=40) N(0, )을 사용한 사전 샘플링은 항상 그럴듯한 데이터를 생성하지는 않지만 변동성이 높습니다. I 2.3 수업 센터에서 샘플링 각 클래스의 평균 인코딩은 전체 데이터 세트에서 누적될 수 있으며 나중에 제어된(조건부 생성)에 사용될 수 있습니다. def get_data_predictions(model, data_loader): model.eval() latents_mean = [] latents_std = [] labels = [] with torch.no_grad(): for i, (data, label) in enumerate(data_loader): mu, std = model.encoder(data.to(device)) latents_mean.append(mu.cpu()) latents_std.append(std.cpu()) labels.append(label.cpu()) latents_mean = torch.cat(latents_mean, dim=0) latents_std = torch.cat(latents_std, dim=0) labels = torch.cat(labels, dim=0) return latents_mean, latents_std, labels def get_classes_mean(class_to_idx, labels, latents_mean, latents_std): classes_mean = {} for class_name in train_loader.dataset.class_to_idx: class_id = train_loader.dataset.class_to_idx[class_name] labels_class = labels[labels==class_id] latents_mean_class = latents_mean[labels==class_id] latents_mean_class = latents_mean_class.mean(dim=0, keepdims=True) latents_std_class = latents_std[labels==class_id] latents_std_class = latents_std_class.mean(dim=0, keepdims=True) classes_mean[class_id] = [latents_mean_class, latents_std_class] return classes_mean latents_mean, latents_stdvar, labels = get_data_predictions(vae, train_loader) classes_mean = get_classes_mean(train_loader.dataset.class_to_idx, labels, latents_mean, latents_stdvar) n_samples = 20 for class_id in classes_mean.keys(): latents_mean_class, latents_stddev_class = classes_mean[class_id] # create normal distribution of the current class class_dist = Normal(latents_mean_class, latents_stddev_class) percentiles = torch.linspace(0.05, 0.95, n_samples) # get samples from different parts of the distribution using icdf # https://pytorch.org/docs/stable/distributions.html#torch.distributions.distribution.Distribution.icdf class_z_sample = class_dist.icdf(percentiles[:, None].repeat(1, z_dim)) with torch.no_grad(): # generate image directly from mean class_image_prototype = vae.decoder(latents_mean_class.to(device)) # generate images sampled from Normal(class mean, class std) class_images = vae.decoder(class_z_sample.to(device)) show_image(class_image_prototype[0].cpu(), title=f'Class {class_id} prototype image') show_images_grid(class_images.cpu(), title=f'Class {class_id} images') 평균 클래스 μ를 갖는 정규 분포에서 샘플링하면 동일한 클래스에서 새 데이터 생성이 보장됩니다. 2.4 보간 def linear_interpolation(start, end, steps): # Create a linear path from start to end z = torch.linspace(0, 1, steps)[:, None].to(device) * (end - start) + start # Decode the samples along the path vae.eval() with torch.no_grad(): samples = vae.decoder(z) return samples 2.4.1 두 개의 무작위 잠재 벡터 사이의 보간 start = torch.randn(1, z_dim).to(device) end = torch.randn(1, z_dim).to(device) interpolated_samples = linear_interpolation(start, end, steps = 24) show_images_grid(interpolated_samples, title=f'Linear interpolation between two random latent vectors') 2.4.2 두 클래스 센터 간의 보간 for start_class_id in range(1,10): start = classes_mean[start_class_id][0].to(device) for end_class_id in range(1, 10): if end_class_id == start_class_id: continue end = classes_mean[end_class_id][0].to(device) interpolated_samples = linear_interpolation(start, end, steps = 20) show_images_grid(interpolated_samples, title=f'Linear interpolation between classes {start_class_id} and {end_class_id}') 2.5 잠재 공간 탐색 잠재 벡터의 각 차원은 정규 분포를 나타냅니다. 차원 값의 범위는 차원의 평균과 분산에 의해 제어됩니다. 값 범위를 탐색하는 간단한 방법은 정규 분포의 역 CDF(누적 분포 함수)를 사용하는 것입니다. ICDF는 0과 1(확률을 나타냄) 사이의 값을 가져와 분포에서 값을 반환합니다. 주어진 확률 에 대해 ICDF는 확률 변수가 <= 확률이 주어진 확률 와 같도록 값을 출력합니다. p p_icdf일 p p_icdf 정규 분포가 있는 경우 icdf(0.5)는 분포의 평균을 반환해야 합니다. icdf(0.95)는 분포 데이터의 95%보다 큰 값을 반환해야 합니다. 2.5.1 단일차원 잠재공간 순회 def latent_space_traversal(model, input_sample, norm_dist, dim_to_traverse, n_samples, latent_dim, device): # Create a range of values to traverse assert input_sample.shape[0] == 1, 'input sample shape should be [1, latent_dim]' # Generate linearly spaced percentiles between 0.05 and 0.95 percentiles = torch.linspace(0.1, 0.9, n_samples) # Get the quantile values corresponding to the percentiles traversed_values = norm_dist.icdf(percentiles[:, None].repeat(1, z_dim)) # Initialize a latent space vector with zeros z = input_sample.repeat(n_samples, 1) # Assign the traversed values to the specified dimension z[:, dim_to_traverse] = traversed_values[:, dim_to_traverse] # Decode the latent vectors with torch.no_grad(): samples = model.decoder(z.to(device)) return samples for class_id in range(0,10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') for i in range(z_dim): interpolated_samples = latent_space_traversal(vae, mu, norm_dist=Normal(mu, torch.ones_like(mu)), dim_to_traverse=i, n_samples=20, latent_dim=z_dim, device=device) show_images_grid(interpolated_samples, title=f'Class {class_id} dim={i} traversal') 단일 차원을 순회하면 숫자 스타일이 변경되거나 숫자 방향이 제어될 수 있습니다. 2.5.3 2차원 잠재 공간 탐색 def traverse_two_latent_dimensions(model, input_sample, z_dist, n_samples=25, z_dim=16, dim_1=0, dim_2=1, title='plot'): digit_size=28 percentiles = torch.linspace(0.10, 0.9, n_samples) grid_x = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) grid_y = z_dist.icdf(percentiles[:, None].repeat(1, z_dim)) figure = np.zeros((digit_size * n_samples, digit_size * n_samples)) z_sample_def = input_sample.clone().detach() # select two dimensions to vary (dim_1 and dim_2) and keep the rest fixed for yi in range(n_samples): for xi in range(n_samples): with torch.no_grad(): z_sample = z_sample_def.clone().detach() z_sample[:, dim_1] = grid_x[xi, dim_1] z_sample[:, dim_2] = grid_y[yi, dim_2] x_decoded = model.decoder(z_sample.to(device)).cpu() digit = x_decoded[0].reshape(digit_size, digit_size) figure[yi * digit_size: (yi + 1) * digit_size, xi * digit_size: (xi + 1) * digit_size] = digit.numpy() plt.figure(figsize=(6, 6)) plt.imshow(figure, cmap='Greys_r') plt.title(title) plt.show() for class_id in range(10): mu, std = classes_mean[class_id] with torch.no_grad(): recon_images = vae.decoder(mu.to(device)) show_image(recon_images[0], title=f'class {class_id} mean sample') traverse_two_latent_dimensions(vae, mu, z_dist=Normal(mu, torch.ones_like(mu)), n_samples=8, z_dim=z_dim, dim_1=3, dim_2=6, title=f'Class {class_id} traversing dimensions {(3, 6)}') 한 번에 여러 차원을 탐색하면 가변성이 높은 데이터를 생성하는 제어 가능한 방법이 제공됩니다. 2.6 보너스 - 잠재 공간의 2D 숫자 다양체 VAE 모델이 로 훈련되면 잠재 공간에서 2D 숫자 다양체를 표시할 수 있습니다. 이를 위해 함수를 및 와 함께 사용하겠습니다. =2 z_dim traverse_two_latent_dimensions =0 Dim_1 =2 Dim_2 vae_2d = train_model(epochs=10, z_dim=2) z_dist = Normal(torch.zeros(1, 2), torch.ones(1, 2)) input_sample = torch.zeros(1, 2) with torch.no_grad(): decoding = vae_2d.decoder(input_sample.to(device)) traverse_two_latent_dimensions(vae_2d, input_sample, z_dist, n_samples=20, dim_1=0, dim_2=1, z_dim=2, title=f'traversing 2D latent space')