























독특한 생태계를 강화하는 비트코인 UTXO 모델


Jan 20, 1970

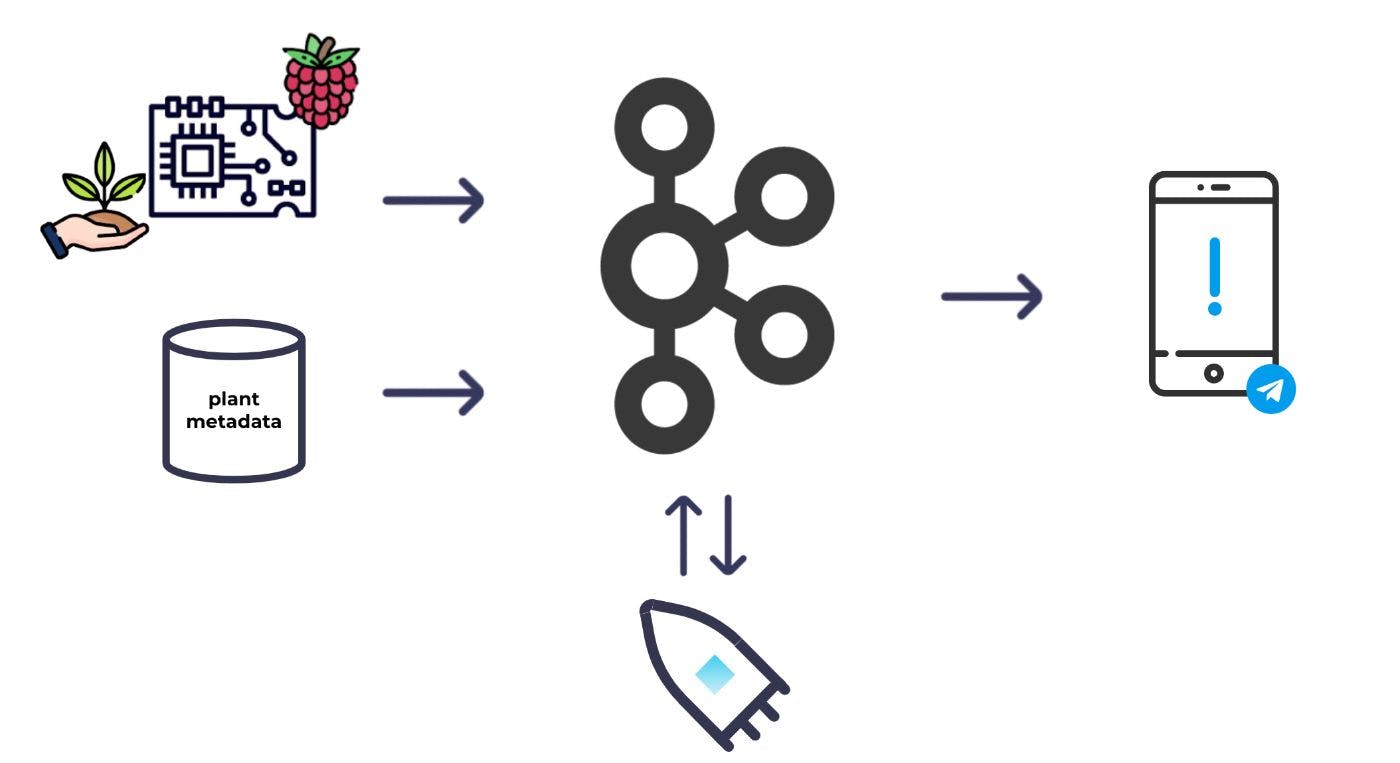
Come along to explore Apache Kafka and see how to get the most out of your event-driven pipelines!
Come along to explore Apache Kafka and see how to get the most out of your event-driven pipelines!
Come along to explore Apache Kafka and see how to get the most out of your event-driven pipelines!






