
15,935 रीडिंग
क्या एजीआई करीब आ रहा है? एंथ्रोपिक का क्लाउड 3 ओपस मॉडल मेटाकॉग्निटिव रीज़निंग की झलक दिखाता है
by byaimodels44@aimodels44
byaimodels44@aimodels44
Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
2024/03/05


















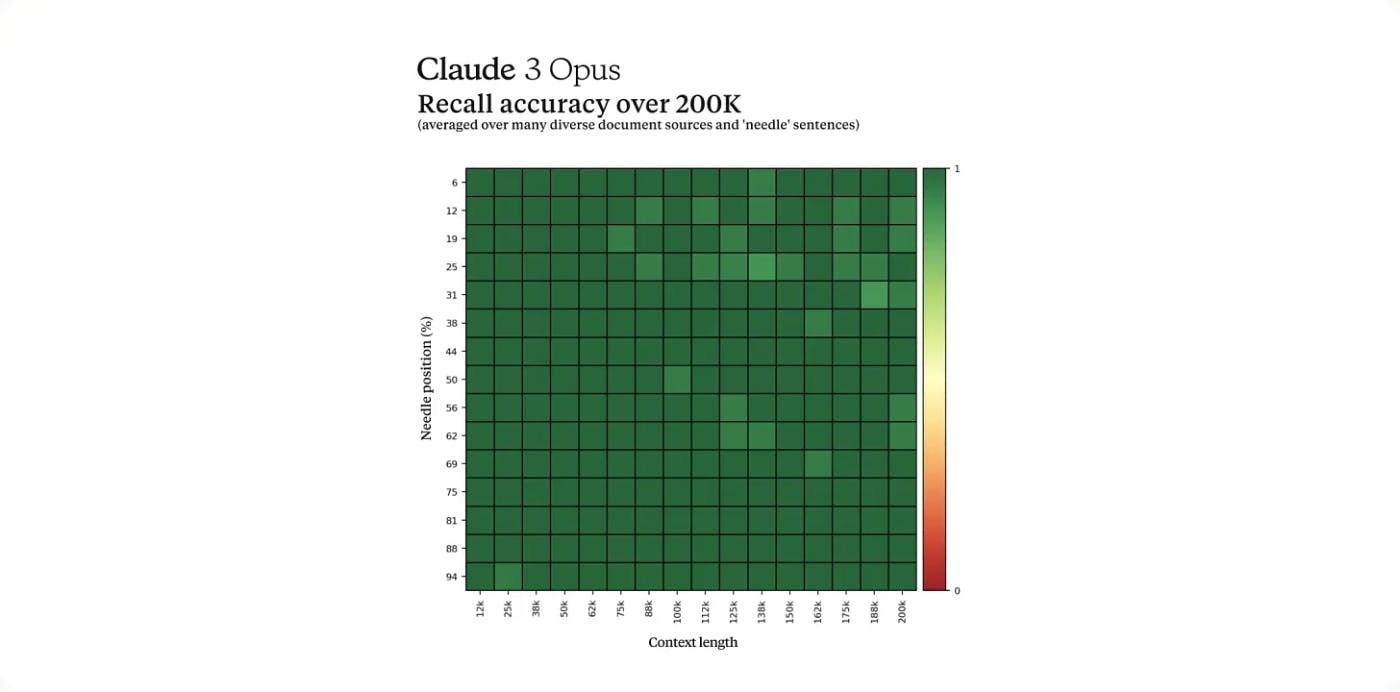
Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
Story's Credibility


Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
Story's Credibility
About Author

Among other things, launching AIModels.fyi ... Find the right AI model for your project - https://aimodels.fyi
टिप्पणियाँ












