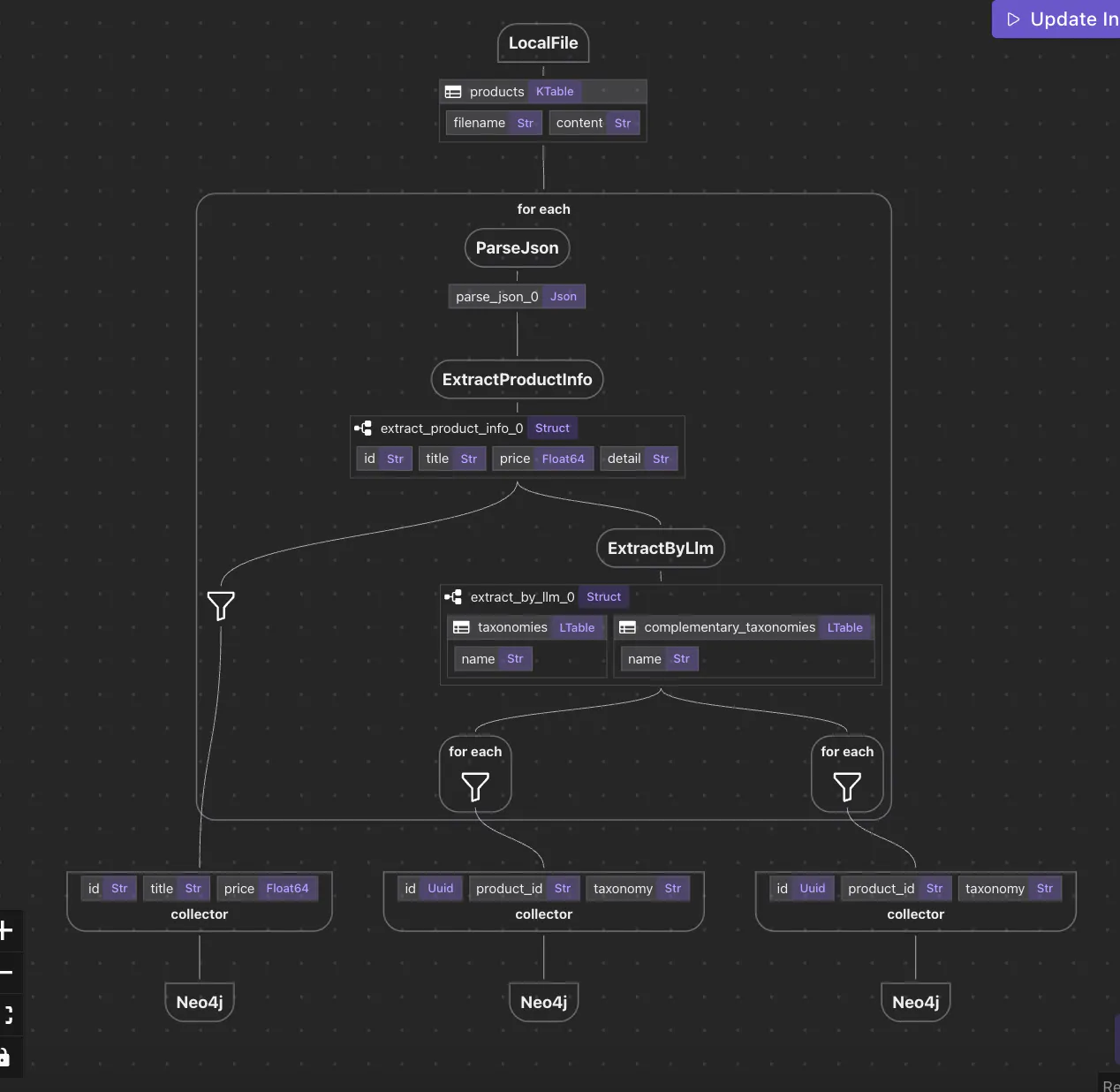
#DATA-ENGINEERINGРедефиниране на операциите на данните с програмиране на потока от данни в CocoIndexLJJul 17, 2025
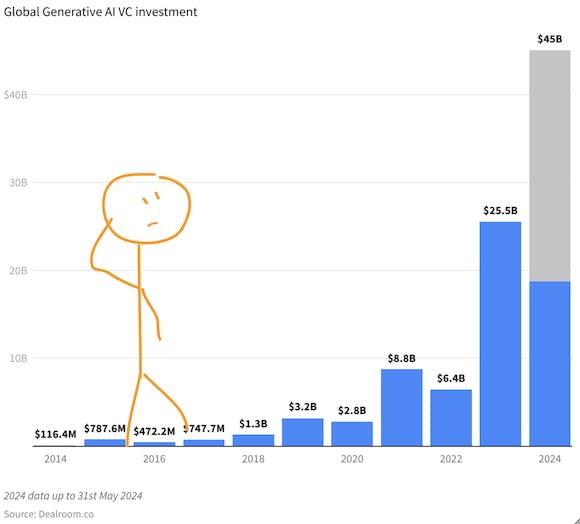
#AIAI Disruptobloat: Как свръхпроизводството намалява стойността, но ускорява иновациитеKamila SeligSep 14, 2024
#ARTIFICIAL-INTELLIGENCEУправление на портфолио: Всички начини, по които AI трансформира съвременните стратегии за активиAndrey KustarevApr 25, 2024
#ARTIFICIAL-INTELLIGENCEДа започнем лесно: Стратегическото предимство на базовите модели в машинното обучениеAndrey KustarevMay 01, 2024
#DATA-ENGINEERINGРедефиниране на операциите на данните с програмиране на потока от данни в CocoIndexLJJul 17, 2025
#AIAI Disruptobloat: Как свръхпроизводството намалява стойността, но ускорява иновациитеKamila SeligSep 14, 2024
#ARTIFICIAL-INTELLIGENCEУправление на портфолио: Всички начини, по които AI трансформира съвременните стратегии за активиAndrey KustarevApr 25, 2024
#ARTIFICIAL-INTELLIGENCEДа започнем лесно: Стратегическото предимство на базовите модели в машинното обучениеAndrey KustarevMay 01, 2024