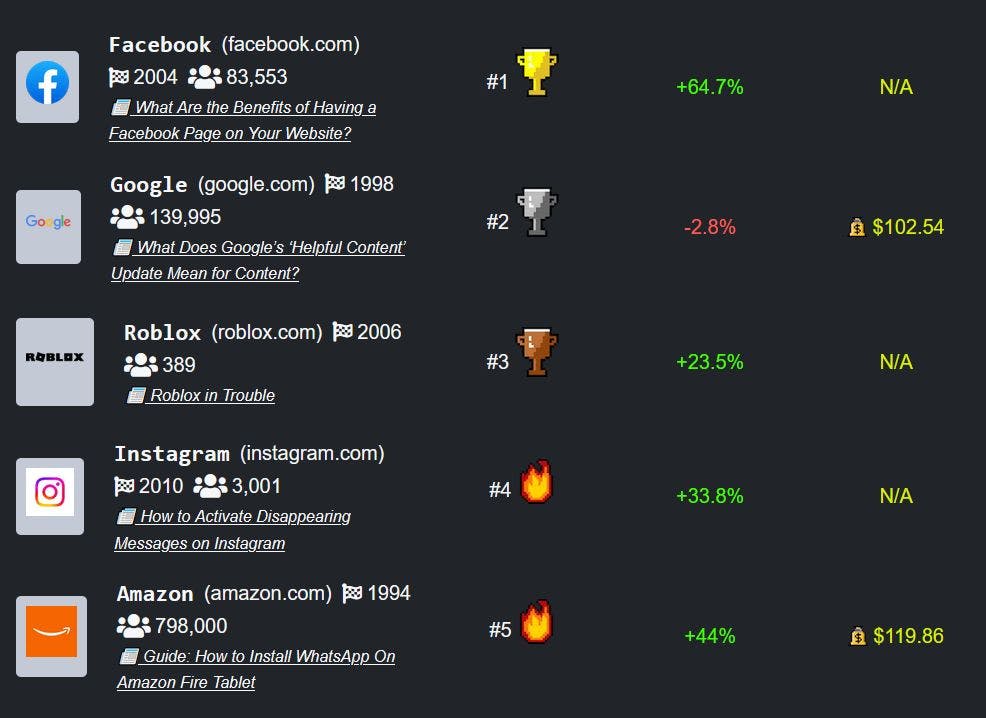
Die skrywers: Scott Reed Konrad Żołna Emilio Parisotto Sergio Gómez Colmenarejo Alexander Novikov Gabriel Barth-Maron Mai Giménez Yury Sulsky Jackie Kay Jost Tobias Springenberg Tom Eccles Jake Bruce Ali Razavi Ashley Edwards Nicolas Heess Yutian Chen Raia Hadsell Oriol Vinyals Mahyar Bordbar Nando de Freitas Die skrywers: Skot Reed Konrad se vrou Emilio Pariso Sergio Gómez van Colmenarejo Alexander Novikow Gabriël Barth-Maron Nie meer gimnasium Yuri Sulsky se Die Jackie Kay Geskryf deur Tobias Springenberg Tom van Eccles Jake Bruce Oorwegende Ashley Edwards se lewe Nicolas Heess se Jodi Chen Raie Hadsell Oorspronklike vinyl Mahyar Bordbar Nando van Freitas abstrakte Die agent, wat ons as Gato noem, werk as 'n multi-modale, multi-task, multi-embodiment generalist beleid. Die dieselfde netwerk met dieselfde gewigte kan speel Atari, ondertitelings beelde, chat, stapel blokke met 'n werklike robot arm en nog baie meer, besluit gebaseer op sy konteks of om teks uit te voer, gesamentlike torse, knoppie drukke, of ander tokens. 1 Inleiding Daar is aansienlike voordele om 'n enkele neurale volgordemodel oor al die take te gebruik. Dit verminder die behoefte aan handwerkbeleidsmodelle met toepaslike inductiewe vooroordele vir elke domein. Dit verhoog die hoeveelheid en diversiteit van opleiding data aangesien die volgordemodel enige data kan opneem wat in 'n plat volgorde geserialiseer kan word. Histories het generiese modelle wat beter in die gebruik van berekening is, ook geneig om meer gespesialiseerde domeinspesifieke benaderings te oorskry. Maar uiteindelik. (Kaplan et al. die jaar 2020; Hoopman et al. Die jaar 2022). van Sutton, van 2019), In hierdie artikel beskryf ons die huidige iterasie van 'n algemene-doeleindes agent wat ons Gato noem, as 'n enkele, groot, transformer seëningemodel.Met 'n enkele stel gewigte, kan Gato in dialoog betrokke raak, foto's, blokke stapel met 'n werklike robotarm, menslike prestasies oorskry by die speel van Atari-speletjies, navigeer in gesimuleerde 3D-omgewing, volg instruksies, en meer. Terwyl geen agent kan verwag word om te uitsteek in alle denkbare beheer take, veral dié wat ver buite sy opleiding verspreiding, ons hier toets die hipotese dat die opleiding van 'n agent wat oor die algemeen in staat is om op 'n Ons hypotheseer dat so 'n agent kan verkry word deur data, berekening en modelparameters te skaal, voortdurend die opleiding verspreiding uit te brei terwyl die prestasie gehou word, om enige taak, gedrag en vervulling van belang te dek. Groot getal Ons fokus ons opleiding op die bedryfspunt van modelskala wat real-time beheer van real-world robotte toelaat, tans rondom 1.2B-parameters in die geval van Gato. Terwyl hardeware- en modelarchitekture verbeter, sal hierdie bedryfspunt natuurlik die haalbare modelgrootte verhoog, wat algemene modelle hoër na die skaalwetkurve stoot. Vir eenvoud Gato is offline op 'n suiwer beheerde manier opgelei; egter, in beginsel, is daar geen rede waarom dit ook nie met offline of online versterking leer (RL) opgelei kon word nie. 2 Modelle Die gidsontwerpbeginsel van Gato is om op die breedste verskeidenheid relevante data moontlik te oefen, insluitend verskillende modaliteite soos beelde, teks, proprioceptie, gesamentlike koppelvlakke, knoppie drukke, en ander diskrete en voortdurende waarnemings en aksies. Om hierdie multi-modale data te verwerk, stel ons al die data in 'n vlakke volgorde van tokens. In hierdie verteenwoording kan Gato opgelei en sampling word van soortgelyk aan 'n standaard grootskaalse taalmodel. Tydens die invoering word sampling van sampling tokens versamel in dialoogreaksies, tekens, knoppie drukke of ander aksies gebaseer op die konteks. In die volgende subseksies beskryf ons Gato se tokenisering, netwer 2.1 Tokenisering Daar is oneindige moontlike maniere om data in tokens te transformeer, insluitend direk met behulp van die ruwe onderliggende byte vloei. Tekst word gekodeer via SentencePiece (Kudo & Richardson, 2018) met 32000 subwoorde in die integerbereik [0, 32000]. Beelde word eers omskep in volgorde van nie-overlappende 16 16 vlekke in raster volgorde, soos gedoen in ViT (Dosovitskiy et al., 2020). Elke pixel in die beeld __p__atches word dan genormaliseer tussen [−1*,* 1] en verdeel deur die vierkante wortel van die vlek grootte (dws √16 = 4). Diskrete waardes, byvoorbeeld Atari-knoppie drukke, word in reeks-major volgorde in volgorde van integere geplaas. Die tokeniseer resultaat is 'n volgorde van integere binne die bereik van [0*,* 1024). Kontinuïteite waardes, byvoorbeeld proprioceptiewe inputs of gesamentlike koppelvlakke, word eers in reeks van dryfpuntwaardes in reëlsmajorreëls afgeplaas. Die waardes word mu-law gekodeer na die bereik [ 1*,* 1] indien nie reeds daar nie (sien Figuur 14 vir besonderhede), dan gediskretiseer na 1024 uniforme bins. Nadat ons data in tokens omskep het, gebruik ons die volgende kanoniese volgorde. Tekst tokens in dieselfde volgorde as die ruwe invoer teks. Foto patch tokens in raster volgorde. Tensors in grootskaalse orde. Genoemde strukture in lexikografiese orde per sleutel. Agent tydstape as waarneming tokens gevolg deur 'n skeerder, dan aksie tokens. Agente episodes as timestapes in tydsreeks. Verdere besonderhede oor tokenizing agent data word aangebied in die aanvullende materiaal (Seksie b) die 2.2 Bepaal input tokens en stel output doelwitte Na tokenisering en opeenvolging, toepas ons 'n geparameteriseerde embedding funksie *f* ( ; *θe*) op elke token (dws dit word toegepas op beide waarnemings en aksies) om die finale modelinvoer te produseer. • Tokens wat tot teks, diskrete of voortdurend gewaardeerde waarnemings of aksies vir enige tydstap behoort, word via 'n soektabel in 'n geleerde vektor-beddingsruimte ingebed. Leerbare posisie-kodings word bygevoeg vir alle tokens gebaseer op hul plaaslike tokenposisie binne hul ooreenstemmende tydstap. • Tokens wat tot beeldpatches behoort vir enige tydstap word ingebed met behulp van 'n enkele ResNet Vir beeld patch token embeddings, voeg ons ook 'n leerbare in-beeld posisie kodeer vektor. Hy en al. Die jaar 2016a Ons verwys na die appendix Vir volledige besonderhede oor die embedding funksie. C.3 die Soos ons die data autoregressief model, is elke token potensieel ook 'n doeletiket gegeven aan die vorige tokens. Tekst tokens, diskrete en voortdurende waardes, en aksies kan direk as doelwitte na tokenisering gestel word. Image tokens en agent nontextual waarnemings word tans nie in Gato voorspel nie, alhoewel dit 'n interessante rigting vir toekomstige werk kan wees. Doelwitte vir hierdie nie-voorspelbare tokens word ingestel op 'n ongebruikte waarde en hul bydrae tot die verlies word weggesteek. 2.3 Opleiding Gegewe 'n volgorde van tokens 1 : die Die parameters , model ons die data met behulp van die kettingregel van waarskynlikheid: s L θ laat ons definieer 'n maskeringsfunksie *m* so dat *m* (*b, l*) = 1 as die token by indeks *l* ofwel uit teks of uit die geplaasde aksie van 'n agent is, en 0 andersins. b Soos hierbo beskryf, het Gato se netwerk-argitektuur twee hoofkomponente: die parameteriseerde embedding funksie wat tokens omskep in token-embeddings, en die volgorde model wat 'n verspreiding oor die volgende diskrete token uitvoer. vir eenvoud en skaalbaarheid. Gato gebruik 'n 1.2B-parameters dekodeer-alleen transformator met 24 lae, 'n ingebedde grootte van 2048, en 'n post-attention feedforward verborge grootte van 8196 (meer besonderhede in Afdeling Aswan en al. 2017 die die 1). Aangesien verskillende take binne 'n domein identiese uitvoerings, waarnemingsformaate en aksie spesifikasies kan deel, benodig die model soms verdere konteks om take te ontken. and use prompt conditioning. During training, for 25% of the sequences in each batch, a prompt sequence is prepended, coming from an episode generated by the same source agent on the same task. Half of the prompt sequences are from the end of the episode, acting as a form of goal conditioning for many domains; and the other half are uniformly sampled from the episode. During evaluation, the agent can be prompted using a successful demonstration of the desired task, which we do by default in all control results that we present here. (Ons en al. Die jaar 2022 Wêreld en al. Die jaar 2021; Brown en al. Die jaar 2020 Opleiding van die model word uitgevoer op 'n 16x16 TPU v3 sny vir 1M stappe met batch grootte 512 en token volgorde lengte = 1024, wat ongeveer 4 dae neem. Architektuur besonderhede kan gevind word in Afdeling Aangesien agent-episode en dokumente maklik baie meer tokens kan bevat as wat in konteks pas, samel ons willekeurig opvolgings van Elke batch meng subsequences ongeveer uniform oor domeine (bv. Atari, MassiveWeb, ens.), met 'n paar handmatige gewig van groter en hoër gehalte datasette (sien Tabel) In die afdeling vir die besonderhede). L c. die L 1 3 2.4 Uitbreiding Die implementering van Kat as 'n beleid word geïllustreer in Figuur Eerstens word 'n prompt, soos 'n demonstrasie, tokeniseer, wat die aanvanklike volgorde vorm. Standaard neem ons die eerste 1024 tokens van die demonstrasie. Vervolgens gee die omgewing die eerste waarneming wat tokeniseer en aan die volgorde bygevoeg word. Gato monster die aksievektor autoregressief een token op 'n keer. Sodra al die tokens wat die aksievektor bevat, monster gemaak is (bepaal deur die aksie spesifikasie van die omgewing), word die aksie gedekodeer deur die tokenisering prosedure wat in Afdeling beskryf word, te omkeren. Hierdie aksie word na die omgewing gestuur wat stappe maak en 'n nuwe waarneming lewer. Die prosedure herhaal. Die model sien altyd al die vorige waarnemings en aksie in sy konteksvenster van 1024 tokens. Ons het gevind dat dit voordelig was om transformer XL-geheue te gebruik tydens uitrusting, hoewel dit nie tydens opleiding gebruik is nie. 3. 2.1 Die (Ons en al. van 2019). 3 Die data Gato is opgelei op 'n groot aantal datasette wat agent-ervaring in beide gesimuleerde en werklike omgewings bevat, sowel as 'n verskeidenheid natuurlike taal- en beelddatasette. Die ooreenstemmende aantal tokens per beheerdataset word bereken met die aanname van die tokenisering meganisme wat in Afdeling beskryf word. 1. 2.1 Die 3.1 Simuleer beheer take Ons beheer take bestaan uit dataset gegenereer deur spesialis SoTA of naby-SoTA versterking leer agente opgelei op 'n verskeidenheid van verskillende omgewings. vir elke omgewing registreer ons 'n subset van die ervaring wat die agent genereer (state, aksies, en belonings) terwyl dit is opleiding. Die gesimuleerde omgewings sluit in Meta-Wereld (Y geïntroduceer aan benchmark meta-versterking leer en multi-task leer, Sokoban voorgestel as 'n beplanningsprobleem, BabyAI for language instruction following in grid-worlds, the DM Control Suite (T vir voortdurende beheer, sowel as DM Lab ontwerp om agente te leer navigeer en 3D-visie van ruwe piksels met 'n egosentrieke perspektief. met klassieke Atari speletjies (ons gebruik twee stel speletjies wat ons ALE Atari en ALE Atari uitgebrei noem, sien Afdeling vir die besonderhede). U en al. Die jaar 2020 (Ons en die ander, 2017 die (Kaptein en ander, Die jaar 2018 Oor die owerhede en al. Die jaar 2020 (Beattie en al., Die 2016 (Ons en die ander, 2013) F1 oorweeg Ons sluit ook die Procgen-benchmark in Modulêre RL Ons sluit ook vier take met behulp van 'n gesimuleerde Kinova Jaco arm van DM Manipulation Playground, soos in die afdeling bevat 'n meer diepgaande beskrywing van hierdie beheer take, saam met watter RL agent gebruik is om die data te genereer. (Hierdie en al. Die jaar 2020 (Hierdie en al. die jaar 2020). Zolna et al. Hy het (2020) F Ons het bevind dat dit effektief is om op 'n gefilterde stel episodes te oefen met ten minste 80% van die deskundige terugkeer vir die taak. Die deskundige terugkeer meet die maksimum volgehoue prestasie wat die deskundige agent kan bereik. Ons definieer dit as die maksimum oor die stel van al die venster gemiddelde terugkeer bereken oor al die versamel episodes vir 'n taak: Waar die totale aantal versamelde episodes vir die taak, is die grootte van die venster, en is die totale terugkeer vir episode Om presiese ramings te verkry, stel ons in die praktyk moet 10% van die totale data bedrag of 'n minimum van 1000 episodes wees (dws = min(1000 * 0 * * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * 1 * • Die N W Ri i W W Die n 3.2 Visie en taal Gato word op MassiveText opgelei 'n versameling van groot Engelse teksdatasette van verskeie bronne: webbladsye, boeke, nuusartikels en kode. (Hierdie en al. in die jaar 2021, Ons het ook verskeie visie-taal dataset in Gato se opleiding ingesluit. ALIGN bestaan uit 1.8B beelde en hul alternatiewe teks (alt-tekst) annotasies. LTIP (Long Text & Image Pairs), bestaan uit 312 miljoen beelde met kopieë die Konseptuele begrippe Die Coco Captions die Die data stel met 3,3M en 120k beeld-tekst paartjies, respectievelik. • die bevat 43M webbladsye waar beide teks en beelde geëxtraheer is. Ons het ook visuele vrae beantwoord datasets ingesluit. In die besonder OKVQA die VQAv2 met 9K en 443K triplets van beelde, vrae en antwoorde. Om 'n opleiding-episode van hierdie te vorm, monster ons vyf (beeld, teks) paartjies, tokenize hulle, verstrengel, en dan pad of willekeurig gewas na die vereiste opleiding sekonde lengte. (Jy en al. Die jaar 2021) (Ons en al. Die jaar 2022). (Sharma en al., Die jaar 2018 (Henry en al. van 2015) (Ons en al Die jaar 2022) Die Marine en al, van 2019) (Ons en al. van 2015) 3.3 Robotics - RGB Stacking Benchmark (real en sim) As 'n testbed data vir die neem van fisiese aktiwiteite in die werklike wêreld, het ons die robotiese blok stapel omgewing deur [Lee et al.](#_bookmark89) [(2021).](#_bookmark89) Die omgewing bestaan uit 'n Sawyer robot arm met 3-DoF cartesian spoedbeheer, 'n bykomende DoF vir spoed, en 'n diskrete gripper aksie gekies. Die robot se werkruimte bevat drie plastiekblokke gekleurde rooi, groen en blou met verskillende vorms. Die beskikbare waarnemings sluit in twee 128 kamera beelde, robot arm en gripper gesamentlike hoeke sowel as die robot se eindeffektor posisie. Opmerklik, die grond waarheid staat inligting vir die drie voorwerpe in die kos word nie deur die agent In Skill Generalization, vir beide simulasie en werklike, gebruik ons data wat deur die beste algemene sim2real agent van Ons versamel data slegs wanneer ons met die aangewese RGB-stacking interaksie maak (dit is 'n totaal van 387k suksesvolle trajektories in simulasie en 15k trajektories in werklikheid). in simulasie en van die beste sim2real beleid op die werklike robot (tot 219k trajektories in totaal). Let daarop dat hierdie data slegs ingesluit is vir spesifieke Skill Mastery eksperimente in Afdeling Lee en al. (2021) van die Opleiding van voorwerpe Lee en al. Hierdie (2021) 5.4 Die 4 Die vermoëns van die generalistiese agent In hierdie afdeling stel ons die prestasie van Gato saam wanneer hy op die hierbo beskryf data opgelei word. Dit wil sê, al die resultate oor al die take is afgelei van 'n enkele vooropleide model met 'n enkele stel gewigte. 5. 4.1 Simulated control tasks Figure shows the number of distinct control tasks for which Gato performs above a given score threshold, relative to expert performance demonstrated in Gato’s training data. 5 We report performance as a percentage, where 100% corresponds to the per-task expert and 0% to a random policy. For each simulated control task we trained our model on, we roll out the Gato policy on the corresponding environment 50 times and average the defined scores. As shown in Figure Gato performs over 450 out of 604 tasks at over a 50% expert score threshold. 5, die In ALE Atari Gato bereik die gemiddelde menslike (of beter) punte vir 23 Atari speletjies , achieving over twice human score for 11 games. While the single-task online RL agents which generated the data still outperform Gato, this may be overcome by adding capacity or using offline RL training rather than purely supervised (see Section where we present a specialist single domain ALE Atari agent achieving better than human scores for 44 games). (Bellemare et al., 2013) 1 5.5 Die baba Gato bereik meer as 80% van die kundige score vir byna alle vlakke . For the most difficult task, called BossLevel, Gato scores 75%. The two other published baselines we could find, BabyAI 1.0 and BabyAI 1.1 die Hy het 77% en 90%, respectievelik, opgelei op hierdie enkele taak alleen met behulp van 'n miljoen demonstrasie. (Kaptein en ander, 2018) 2 (Hui et al. die jaar 2020), On Meta-World (Y Gato achieves more than 50% for all 44 out of 45 tasks that we trained on, over 80% for 35 tasks, and over 90% for 3 tasks. On canonical DM Control Suite (T Gato achieves better than 50% of the expert score on 21 out of 30 tasks from state, and more than 80% for 18 tasks. u et al., Die jaar 2020 Asma en al. 2018), 4.2 Robotics First person teleoperation enables the collection of expert demonstrations. However, such demonstrations are slow and costly to collect. Data-efficient behavior cloning methods are therefore desirable for training a generalist robot manipulator and offline pretraining is thus a well-motivated area of research. To that end, we evaluated Gato on the established RGB Stacking benchmark for robotics. Skill Generalization Performance The Skill Generalization challenge from the RGB Stacking robotics benchmark tests the agent’s ability to stack objects of previously unseen shapes. The agent is trained on a dataset consisting of episodes of the robot stacking objects with a variety of different shapes. Five triplets of object shapes are, however, not included in the training data and serve as test triplets. We evaluated the trained generalist for 200 episodes per test triplet on the real robot. Table shows that our generalist agent’s success rate on each test triplet is comparable to the single task BC-IMP (filtered BC) baseline in 2 Lee en al. (2021). 4.3 Text samples The model demonstrates rudimentary dialogue and image captioning capabilities. Figure contains a rep-resentative sample of Gato’s image captioning performance. Figure shows some hand-picked examples of plain text dialogue exchange. 6 7 5 Analiseer 5.1 Scaling Laws Analysis In die figuur ons analiseer die geaggregeerde prestasie in die verspreiding van die vooropleide model as 'n funksie van die aantal parameters om insig te kry oor hoe prestasie met verhoogde modelkapasiteit kan verbeter. Ons het 3 verskillende model groottes (gemeten in parameter getal): 'n 79M model, 'n 364M model, en 'n 1.18B model (Gato). Ons verwys na Afdeling for details on the three model architectures. 8, C Here, for all three model sizes we plot the normalized return as training progresses. To get this single value, for each task we calculate the performance of the model as a percentage of expert score (the same as done in Section 1). Then for each domain listed in Table Ons gemiddeld die persentasie punte oor al die take vir daardie domein. Ten slotte, ons gemiddeld-aggregeer die persentasie punte oor alle domeine. Ons kan sien dat vir 'n ekwivalente token telling, daar is 'n beduidende prestasie verbetering met verhoogde skaal. 4. 1 5.2 Buite die verspreiding taak In this section we want to answer the following question: For this reason, we held-out all data for four tasks from our pre-training set: cartpole.swingup (DM Control Suite domain), assembly-v2 (Meta-World domain), order_of_apples_forage_simple (DM Lab domain), and boxing (ALE Atari domain). These four tasks will serve as testbeds for evaluating the out-of-distribution capabilities of Gato. Kan ons agent gebruik word om 'n heeltemal nuwe taak doeltreffend op te los? Ideally, the agent could potentially learn to adapt to a new task via conditioning on a prompt including demonstrations of desired behaviour. However, due to accelerator memory constraints and the extremely long sequence lengths of tokenized demonstrations, the maximum context length possible does not allow the agent to attend over an informative-enough context. Therefore, to adapt the agent to new tasks or behaviours, we choose to fine-tune the agent’s parameters on a limited number of demonstrations of a single task, and then evaluate the fine-tuned model’s performance in the environment. Fine-tuning is very similar to pretraining with minor changes, such as different learning rate schedule; see Section for details. E We want to measure how choice of data used during pretraining influences post-fine-tuning performance. To this end, we compare Gato (trained on ) to variants trained on ablated datasets: all data 'N model wat slegs op data van dieselfde domein as die taak voorberei word, . same domain only data 2. A model pretrained only on non-control data, . no control data 3. A model fine-tuned from scratch, i.e. no pretraining at all, . scratch Considering as all these experiments require training a new model from scratch and then also fine-tuning, we present results using the less compute-intensive 364M parameter architecture described in Section Results are shown in Figure 5.1. 9. Fine-tuning performance on both cartpole.swingup and assembly-v2 tasks, both of which do not require image processing, present similar trends. Pretraining on all the datasets yields the best results, followed by pretraining on the same domain only. This difference is smaller for assembly-v2 but consistent for all few shot datasets. For these non-image-based environments, we see either no benefit (cartpole.swingup) or even negative transfer (assembly-v2) when pretraining on Datasets, wat slegs beelde en teks data bevat. no control Results for DM Lab order_of_apples_forage_simple are slightly different. Pretraining on DM Lab data only is already enough to approach the maximum reward of 19 and hence there is no observable benefit of adding data from different environments. What is different when compared to previously analysed no-vision environments is that pretraining on data helps, which can be possibly explained by the fact that agents in the DM Lab environment are fed images which, despite being simulated, are natural looking. Therefore, transfer from image captioning or visual grounded question answering tasks is possible. no control We were not able to observe any benefit from pretraining on boxing. The randomly initialized model seems to work better than any of the pretrained variants considered. We hypothesise that this is caused by the game’s input images being visually very distinct from the other data, suggesting transfer is difficult. We discuss this Atari challenge further in our related work section. 5.3 Fine-tuning on Robotic Stacking Tasks afdeling demonstrates that the base Gato capable of a diverse array of tasks can perform competitively on the RGB Stacking Skill Generalization benchmark. In this section, we would like to answer the following question: *How does our agent improve on robotics tasks when allowed to fine-tune similarly to how we fine-tune on new tasks in Section *Ons oorweeg verskillende model groottes en analiseer die impak van vooropleiding datasette op die Skill Generalization benchmark, sowel as 'n nuwe uit die verspreiding taak. 4.2 5.2? I. Skill Generalization First, we would like to show that fine-tuning on object-specific data, similarly to what was done by Daarom het ons Gato afsonderlik op vyf subset van demonstrasie van die dataset. Each subset was obtained by random partitioning of a test dataset consisting of demonstrations gathered by a generalist sim-to-real agent stacking real test objects. We consider this setting, which is comparable to the fine-tuning baselines on RGB stacking tasks from and use the 5k dataset that their behavior cloning 5k results are obtained with. To best match their experiments, we change our return filtering scheme during training: instead of using only successful stacks, we condition on the normalized return of the episode. Lee en al. (2022), Testeer (Lee et al., 2022); Figure compares the success rate of Gato across different fine-tuning data regimes to the sim-to-real expert and a Critic-Regularized Regression (CRR) agent trained on 35k episodes of all test triplets. Gato, in both reality and simulation (red curves on the left and right figure, respectively), recovers the expert’s performance with only 10 episodes, and peaks at 100 or 1000 episodes of fine-tuning data, where it exceeds the expert. After this point (at 5000), performance degrades slightly but does not drop far below the expert’s performance. 10 (Wang et al., 2020) Fine-tuning and Model Size To better understand the benefit of large models for few-shot adaptation in robotics domains, we conducted an ablation on model parameter size. This section focuses on in-simulation evaluation. Figure vergelyk die volledige 1.18B-parameter Gato met die kleiner 364M- en 79M-parametervariante vir verskillende hoeveelhede fine-tuning data. Alhoewel die 364M-model op een episode oorskakel, wat veroorsaak dat die prestasie daal, is daar 'n duidelike tendens na beter aanpassing met minder episodes as die aantal parameters verhoog word. Die 79M-model prestasie duidelik swakker as sy groter eweknieë. 10 Adaptation to Perceptual Variations While the Skill Generalization task is an effective benchmark for motor Skill Generalization to shape varia-tions, it does not test the agent’s ability to adapt to perceptual variations and permutations in the objective specification. To further evaluate Gato’s generalization capabilities, we devised a new task in the RGB stacking benchmark where the goal is to stack the blue object on the green object, for test triplet 1 (see Figure First, we used a 3D mouse to collect 500 demonstrations of this task on the real robot, for a total of 2 hours and 45 minutes of demonstration data, and fine-tuned Gato on these episodes. Notably, all of the simulated and real robotics data in the pretraining set shows the robot successfully stacking the red object on the blue object, and the data does not include the object shapes in the test set. We found that additionally adding simulated demonstrations of the stack blue on green task to the fine-tuning dataset improved performance, and 10% was an ideal sampling ratio for this data. 11). We achieved a final 60% success rate after evaluating fine-tuned Gato on the real robot, while a BC baseline trained from scratch on the blue-on-green data achieved only 0.5% success (1/200 episodes). Qualitatively, the BC baseline would consistently move towards the blue object and occasionally pick it up and place it on top of the green object, but a full, stable stack was almost never achieved. 5.4 Robotics: Skill Mastery Similarly to the Skill Generalization challenge discussed in Section die Skill Mastery uitdaging bestaan uit die opleiding van 'n robotiese arm om blokke van verskillende vorme te stap. set in Skill Generalization becomes a part of the Skill Mastery set. Thus, this challenge serves to measure Gato’s performance on in-distribution tasks (possibly with initial conditions not seen in the training demonstrations). Our Skill Mastery results use an earlier version of the Gato architecture described in Appendix with no fine-tuning. 4.2, test training H, Tafel compares the group-wise success percentage and the average success across object groups for Gato and the established BC-IMP baseline. Gato exceeds or closely matches BC-IMP’s performance on all but one training triplet. 3 5.5 Specialist single-domain multi-task agents In this section we show results obtained with two specialist (rather than generalist) agents. Both of them were trained on data from a single domain only and rolled out 500 times for each training task without any per-task fine-tuning. Meta-World The first agent uses the smallest architecture introduced in Section i.e. 79M parameters, and is trained on all 50 Meta-World tasks. While Gato has access to the state of the MuJoCo physics engine and unlimited task seeds, the agent presented here has no access to any extra features or tasks and uses the canonical API as in (Y This experiment is to show that the architecture proposed in our paper can be used to obtain state-of-the-art agents also at small scale. The training procedure was to train single-task MPO experts on each of the MT-50 tasks individually, recording the trajectories produced while training. This experience is then combined, or distilled, into a single agent, which achieves 96.6% success rate averaged over all 50 tasks. To the best of our knowledge this agent is the first one to accomplish nearly 100% average success rate simultaneously (multi-task) for this benchmark. See Table in the supplementary material (Section for the full list of tasks and corresponding success rates of our agent. 5.1, u et al., 2020). (Abdolmaleki et al., 2018) 7 K) ALE Atari We also trained a specialist agent on all 51 ALE Atari tasks. As the Atari domain is much more challenging than Meta-World, we used the Gato architecture with 1.18B parameters. The resulting agent performs better than the average human for 44 games (see Section for details on our evaluation and scoring). We want to note that the performance of online experts used to generate training data for the other 7 games were also below the average human. Hence, the specialist Atari agent achieved better than human performance for all games where data contained super-human episodes. 4.1 Die spesialis Atari-agent oorskry ons algemene agent Gato, wat op 23 wedstryde supermenslike prestasies bereik het. Dit dui daarop dat die skaal van Gato selfs beter kan wees. 5.6 Attention Analysis We rendered the transformer attention weights over the image observations for various tasks, to gain a qualitative sense of how Gato attends to different regions of the image across tasks (see Figure Further details and visualizations for more tasks can be found in Appendix These visualizations clearly show that attention tracks the task-relevant objects and regions. 12). J. 5.7 Embedding Visualization To understand how Gato encodes differently information per task, we visualized per-task embeddings. We analysed 11 tasks. For each task, we randomly sample 100 episodes and tokenize each of them. Then, from each episode we take a subsequence of 128 tokens, compute their embeddings (at layer 12, which is half the total depth of the transformer layers) and average them over the sequence. The averaged embeddings for all tasks are used as input to PCA, which reduces their dimensionality to 50. Then, T-SNE is used to get the final 2D embeddings. Figuur shows the final T-SNE embeddings plotted in 2D, colorized by task. Embeddings from the same tasks are clearly clustered together, and task clusters from the same domain and modality are also located close to each other. Even held-out task (cartpole.swingup) is clustered correctly and lays next to another task from DM Control Suite Pixels. 13 6 Related Work The most closely related architectures to that of Gato are Decision Transformers , and Trajectory Transformer which showed the usefulness of highly generic LM-like architectures for a variety of control problems. Gato also uses an LM-like architecture for control, but with design differences chosen to support multi-modality, multi-embodiment, large scale and general purpose deployment. Pix2Seq ook gebruik 'n LM-gebaseerde argitektuur vir voorwerpdeteksie. ., uses a transformer-derived architecture specialized for very long sequences, to model any modality as a sequence of bytes. This and similar architectures could be used to expand the range of modalities supported by future generalist models. (Chen et al., 2021b; Reid et al., Die jaar 2022 Zheng et al., 2022; Verhoogte en al. 2021) (Janneke en al. 2021), (Chen et al., 2022) (Jaegle et al 2021) Gato was inspired by works such as GPT-3 and Gopher pushing the limits of generalist language models; and more recently the Flamingo generalist visual language model. developed the 540B parameter Pathways Language Model (PalM) explicitly as a generalist few-shot learner for hundreds of text tasks. (Brown et al., 2020) (Rae et al., in die jaar 2021, (Alayrac et al., 2022) Chowdhery et al. (2022) Future work should consider how to unify these text capabilities into one fully generalist agent that can also act in real time in the real world, in diverse environments and embodiments. Gato also takes inspiration from recent works on multi-embodiment continuous control. used message passing graph networks to build a single locomotor controller for many simulated 2D walker variants. showed that transformers can outperform graph based approaches for incom-patible (i.e. varying embodiment) control, despite not encoding any morphological inductive biases. learn a modular policy for multi-task and multi-robot transfer in simulated 2D manipulation environments. train a universal policy conditioned on a vector representation of robot hardware, showing successful transfer both to simulated held out robot arms, and to a real world sawyer robot arm. Huang en al. (2020) Kurin et al. (2020) Devin et al. (2017) Chen en al. 2018 die 'N verskeidenheid vroeëre generalistiese modelle is ontwikkel wat, soos Gato, oor hoogs onderskeie domeine en modaliteite bedryf. trained a single LSTM to execute diverse programs such as sorting an array and adding two numbers, such that the network is able to generalize to larger problem instances than those seen during training. developed the MultiModel that trains jointly on 8 distinct speech, image and text processing tasks including classifica-tion, image captioning and translation. Modality-specific encoders were used to process text, images, audio and categorical data, while the rest of the network parameters are shared across tasks. proposed “ ”, describing a method for the incremental training of an increasingly general problem solver. proposed controllable multi-task language models that can be directed according to language domain, subdomain, entities, relationships between entities, dates, and task-specific behavior. (Reed & De Freitas, 2016) (Hochreiter & Schmidhuber, 1997) Kaiser en al. (2017) Schmidhuber 2018 die Een groot net vir alles Keskar et al. (2019) In this discussion, it is important to distinguish between one single multi-task network architecture versus one single neural network with the same weights for all tasks. Several poplar RL agents achieve good multi-task RL results within single domains such as Atari57 and DMLab However, it is much more common to use the same policy architecture and hyper-parameters across tasks, but the policy parameters are different in each task This is also true of state-of-the-art RL methods applied to board games Moreover, this choice has been adopted by off-line RL benchmarks and recent works on large sequence neural networks for control, including decision transformers and the Trajectory Transformer of In contrast, in this work we learn a single network with the same weights across a diverse set of tasks. (Espeholt et al., 2018; Song en al. 2020; Hessel et al., 2019). (Veel van hulle en al. 2015; Tassa en al. 2018). (Hierdie boek en al. 2020). (Gulcehre et al., die jaar 2020; Fu et al., 2020) (Henry en al. die jaar 2021b; Reid et al. 2022; Zheng et al., 2022) Janneke en al. (2021). Recent position papers advocate for highly generalist models, notably proposing one big net for everything, and on foundation models. However, to our knowledge there has not yet been reported a single generalist trained on hundreds of vision, language and control tasks using modern transformer networks at scale. Schmidhuber 2018 die Bommasani et al. (2021) “Single-brain”-style models have interesting connections to neuroscience. famously stated that “ ”. Mountcastle found that columns of neurons in the cortex behave similarly whether associated with vision, hearing or motor control. This has motivated arguments that we may only need one algorithm or model to build intelligence Mountcastle (1978) the processing function of neocortical modules is qualitatively similar in all neocortical regions. Put shortly, there is nothing intrinsically motor about the motor cortex, nor sensory about the sensory cortex Hawkins en Blakeslee, 2004). Sensory substitution provides another argument for a single model Byvoorbeeld, dit is moontlik om taktiele visuele hulpbronne vir blinde mense te bou soos volg. Die signaal wat deur 'n kamera gevang word, kan deur middel van 'n elektrode-reeks op die tong na die brein gestuur word. Die visuele cortex leer om hierdie taktiele signale te verwerk en te interpreteer, wat die persoon met 'n vorm van "visie" verskaf. Dit dui daarop dat, ongeag die tipe ingangssignaal, dieselfde netwerk dit tot nuttige uitwerking kan verwerk. (Bach-y Rita & Kercel, 2003). Ons werk is gebaseer op diep autoregressiewe modelle, wat 'n lang geskiedenis het en in generatiewe modelle van teks, beelde, video en klank gevind kan word. Dit het 'n groot invloed op taalmodelle gehad. protein folding vision-language models (T code generation dialogue systems with retrieval capabilities speech recognition Neurale masjien vertaling en meer , Recently researchers have explored task decomposition and grounding with language models aswani et al., 2017; Devlin et al., 2018) (Brown et al., 2020; Rae et al., 2021), (Jumper et al., 2021), simpoukelli et al., 2021; Wang et al., 2021; Alayrac et al., Die jaar 2024), (Chen et al., 2021c; Li et al., 2022b), (Ons en al. Die jaar 2021; Thoppilan et al., 2022), (Pratap et al., 2020), (Johnson et al., 2019) (Bommasani et al. 2021). (Huang et al., 2022; Ahn et al., 2022). construct a control architecture, consisting of a sequence tokenizer, a pretrained language model and a task-specific feed-forward network. They apply it to VirtualHome and BabyAI tasks, and find that the inclusion of the pretrained language model improves generalisation to novel tasks. Similarly, Demonstreer dat visie modelle vooroplei met selfbeheerde leer, veral gewas segmentasies en momentum kontras can be effectively incorporated into control policies. Li et al. (2022a) Parys en al. (2022) (He et al., 2020), As mentioned earlier, transfer in Atari is challenging. researched transfer between ran-domly selected Atari games. They found that Atari is a difficult domain for transfer because of pronounced differences in the visuals, controls and strategy among the different games. Further difficulties that arise when applying behaviour cloning to video games like Atari are discussed by Rusu et al. (2016) Kanervisto et al. (2020). There has been great recent interest in data-driven robotics However, note that in robotics “ ”. Moreover, every time we update the hardware in a robotics lab, we need to collect new data and retrain. We argue that this is precisely why we need a generalist agent that can adapt to new embodiments and learn new tasks with few data. (Hierdie en al. 2019; Chen et al., 2021a). Bommasani et al. (2021) the key stumbling block is collecting the right data. Unlike language and vision data, robotics data is neither plentiful nor representative of a sufficiently diverse array of embodiments, tasks, and environments Die genereer van aksies met behulp van 'n autoregressiewe model kan lei tot kausale "self-delusie" vooroordele wanneer daar verwarrende veranderlike is. Byvoorbeeld, sampling aksie kan die model om die verkeerde taak op te los wanneer verskeie take deel soortgelyke waarneming en aksie spesifikasies. we use prompt engineering in ambiguous tasks, conditioning our model on a successful demon-stration. This screens off confounding variables, reducing self-delusions. Another solution which we did not explore in this work is to use counterfactual teaching, where we train a model online using instantaneous expert feedback. We leave this for future investigation. (Ortega et al., 2021). 2, 7 Broader Impact Alhoewel algemene agente nog steeds slegs 'n opkomende gebied van navorsing is, vereis hul potensiële impak op die samelewing 'n grondige interdissiplinêre analise van hul risiko's en voordele. However, the tools for mitigating harms of generalist agents are relatively underdeveloped, and require further research before these agents are deployed. A. Since our generalist agent can act as a vision-language model, it inherits similar concerns as discussed in Daarbenewens kan algemene agente optrede in die fisiese wêreld neem; nuwe uitdagings wat nuwe beperkingsstrategieë kan vereis. Byvoorbeeld, fisiese uitvoerings kan lei tot gebruikers wat die agent antropomorfiseer, wat lei tot verkeerde vertroue in die geval van 'n wanfunksionerende stelsel, of word uitbuigbaar deur slegte akteurs. Daarbenewens, terwyl kruis-domein kennisoverdrag dikwels 'n doelwit in ML-navorsing is, kan dit onverwagte en ongewenste uitkomste skep as sekere gedrag (bv. arcade spel veg) na die verkeerde konteks oorgedra word. (Wei-dinger et al., Die jaar 2021; Bommasani et al., 2021; Rae et al., 2021; Alayrac et al. 2022). Technical AGI safety may also become more challenging when considering generalist agents that operate in many embodiments. For this reason, preference learning, uncertainty modeling and value alignment (R are especially important for the design of human-compatible generalist agents. It may be possible to extend some of the value alignment approaches for language to generalist agents. However, even as technical solutions are developed for value alignment, generalist systems could still have negative societal impacts even with the intervention of well-intentioned designers, due to unforeseen circumstances or limited oversight Hierdie beperking beklemtoon die behoefte aan 'n versigtige ontwerp en 'n uitrolproses wat verskeie dissiplines en standpunte insluit. (Bostrom, 2017 die ussell, 2019) (Hierdie en al. 2022; Kenton et al., 2021) (Amodei et al., 2016). Understanding how the models process information, and any emergent capabilities, requires significant ex-perimentation. External retrieval Dit is getoon dat dit beide interpretasie en prestasie verbeter, en daarom moet dit in toekomstige ontwerpe van algemene agente oorweeg word. (Borgeaud et al., 2021; Menick et al., 2022; Nakano et al., 2021; Toerisme et al., 2022) Although still at the proof-of-concept stage, the recent progress in generalist models suggests that safety researchers, ethicists, and most importantly, the general public, should consider their risks and benefits. We are not currently deploying Gato to any users, and so anticipate no immediate societal impact. However, given their potential impact, generalist models should be developed thoughtfully and deployed in a way that promotes the health and vitality of humanity. 8 Beperkings en toekomstige werk 8.1 RL data collection Gato is a data-driven approach, as it is derived from imitation learning. While natural language or image datasets are relatively easy to obtain from the web, a web-scale dataset for control tasks is not currently available. This may seem at first to be problematic, especially when scaling Gato to a higher number of parameters. That being said, there has already been extensive investigation into this issue. Offline RL aims at leveraging existing control datasets, and its increasing popularity has already resulted in the availability of more diverse and larger datasets. Richer environments and simulations are being built (e.g. Metaverse), and increasing numbers of users already interact with them among thousands of already deployed online games (e.g. there exists a large dataset of Starcraft 2 games). Real-life data has also been already stored for ML research purposes; for example, data for training self-driving cars is acquired from recording human driver data. Finally, while Gato uses data consisting of both observations and corresponding actions, the possibility of using large scale observation-only data to enhance agents has been already studied (Baker et al., 2022). Thanks to online video sharing and streaming platforms such as Youtube and Twitch, observation-only datasets are not significantly more difficult to collect than natural language datasets, motivating a future research direction to extend Gato to learn from web data. While the previous paragraph focuses on alleviating drawbacks of data collection from RL agents, it is important to note that this approach presents a different set of tradeoffs compared to scraping web data and can be actually more practical in some situations. Once the simulation is set up and near SOTA agent trained, it can be used to generate massive amounts of high quality data. That is in contrast to the quality of web data which is notorious for its low quality. Kortom, ons glo dat die verkryging van geskikte data is nog 'n navorsingsvraag op sigself, en dit is 'n aktiewe gebied van navorsing met toenemende momentum en belangrikheid. 8.2 Prompt and short context Gato is prompted with an expert demonstration, which aids the agent to output actions corresponding to the given task. This is particularly useful since there is otherwise no task identifier available to the agent (that is in contrast to many multi-task RL settings). Gato infers the relevant task from the observations and actions in the prompt. However, the context length of our agent is limited to 1024 tokens which translates to the agent sometimes attending to only a few environment timesteps in total. This is especially the case for environments with image observations, where depending on the resolution each observation can result in more than one hundred tokens each. Hence for certain environments only a short chunk of a demonstration episode fits in the transformer memory. Due to this limited prompt context, preliminary experiments with different prompt structures resulted in very similar performance. Similarly, early evaluations of the model using prompt-based in-context learning on new environments did not show a significant performance improvement compared to prompt-less evaluation in the same setting. Context-length is therefore a current limitation of our architecture, mainly due to the quadratic scaling of self-attention. Many recently proposed architectures enable a longer context at greater efficiency and these innovations could potentially improve our agent performance. We hope to explore these architectures in future work. 9 Conclusions Transformer sequence models are effective as multi-task multi-embodiment policies, including for real-world text, vision and robotics tasks. They show promise as well in few-shot out-of-distribution task learning. In the future, such models could be used as a default starting point via prompting or fine-tuning to learn new behaviors, rather than training from scratch. Gegewe skalering van wettrends, sal die prestasie oor al die take, insluitend dialoog, met skaal in parameters, data en berekening verhoog. Betere hardeware- en netwerkarchitektures sal die opleiding van groter modelle toelaat terwyl real-time robotbeheersingskapasiteit gehandhaaf word. Acknowledgments We would like to thank Dan Horgan, Manuel Kroiss, Mantas Pajarskas, and Thibault Sottiaux for their help with data storage infrastructure; Jean-Baptiste Lespiau and Fan Yang for help on concurrent evalua-tion; Joel Veness for advising on the model design; Koray Kavukcuoglu for helping inspire the project and facilitating feedback; Tom Erez for advising on the agent design and task selection for continuous control; Igor Babuschkin for helping code the initial prototype; Jack Rae for advising on the transformer language model codebase; Thomas Lampe for building robot infrastructure and advising on real robotics experiments; Boxi Wu for input on ethics and safety considerations; Pedro A. Ortega for advice in regard to causality and self-delusion biases. Author Contributions developed the project concept, wrote the initial prototype, and led the project overall. led architecture development for vision and text, built infrastructure for tokenization and prompting, and contributed heavily to overall agent development and evaluation. Scott Reed Konrad Żołna led work on optimizing the transformer architecture, ran the largest number of experi-ments, and analyzed scaling law properties and in-distribution agent performance. Emilio Parisotto was the technical lead, responsible for creating a scalable data loader and evaluator supporting hundreds of tasks at once, and for the initial robot integration with Gato. Sergio Gómez Colmenarejo developed the model including the sampler for the initial prototype, carried out ex-periments focusing on robotics, and created visualizations. Alexander Novikov built scalable storage infrastructure to provide Gato with SoTA-level agent expe-rience in Atari and other domains. Gabriel Barth-Maron conducted large scale agent data collection, built substantial data loading infrastructure, and integrated large scale visual-language datasets into the training of Gato. Mai Giménez contributed broadly to the Gato codebase including a bespoke distributed training sequence loader, and led the development of benchmarks for out-of-distribution generalization, and the training of competitive baseline agents. Yury Sulsky ondersteun fisiese robotika-infrastruktuur, het talle evaluerings en eksperimente uitgevoer om die generaliseringseienskappe van Gato te analiseer, en het die breër etiese impak beskou. Jackie Kay guided Gato’s deployment to the physical robot, provided strong existing base-lines for block stacking, and advised on model development and experimental design. Jost Tobias Springenberg developed the Gato dialogue and image captioning demonstrations, allowing users to easily probe the vision and language capacities of agents in development. Tom Eccles het bygedra tot agent ontwerp sowel as beheer dataset en omgewings met gerandomiseerde fisika en morfologie variasies. Jake Bruce helped in exploring vision architectures. Ali Razavi contributed to the first prototype of Gato that worked on Atari, in addition to exploring alternative network architectures and training objectives. Ashley Edwards advised on agent design, experiment design and task selection, especially for continuous control applications. Nicolas Heess adviseer oor modelontwerp en eksperimente, en gee terugvoer in gereelde vergaderings. Yutian Chen advised on the design and planning of robotics efforts. Raia Hadsell advised on all aspects of the project, especially model architecture, training strategies and benchmark design. Oriol Vinyals was the primary project manager; eliciting key goals, tracking progress, facilitating pre-sentations and feedback, and coordinating resource planning. Mahyar Bordbar oversaw the project from its inception. Nando de Freitas References Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Martin Ried-miller. Maximum a posteriori policy optimisation. Die jaar 2018. Preprint arXiv:1806.06920 Samira Abnar en Willem Zuidema. Kwantifiseer aandagstroom in transformateurs. , 2020. Preprint arXiv:2005.00928 Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, et al. Do as I can, not as I say: Grounding language in robotiese affordances. Die jaar 2022. Voordruk arXiv:2204.01691 Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman en Karen Simonyan. , 2022. Preprint arXiv:2204.14198 Dario Amodei, Chris Olah, Jacob Steinhardt, Paul F. Christiano, John Schulman, and Dan Mané. Concrete problems in AI safety. , 2016. Preprint arXiv:1606.06565 Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. VQA: Visual question answering. In , bladsy 2425–2433, 2015. International Conference on Computer Vision Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. Die jaar 2016. Preprint arXiv:1607.06450 Paul Bach-y Rita and Stephen W Kercel. Sensory substitution and the human-machine interface. , 7(12):541–546, 2003. Trends in cognitive sciences Bowen Baker, Ilge Akkaya, Peter Zhokhov, Joost Huizinga, Jie Tang, Adrien Ecoffet, Brandon Houghton, Raul Sampedro, and Jeff Clune. Video pretraining (vpt): Learning to act by watching unlabeled online videos. , 2022. Voordruk arXiv: 2206.11795 Gabriel Barth-Maron, Matthew W Hoffman, David Budden, Will Dabney, Dan Horgan, Dhruva Tb, Alistair Muldal, Nicolas Heess, and Timothy Lillicrap. Distributed distributional deterministic policy gradients. , 2018. Preprint arXiv:1804.08617 Charles Beattie, Joel Z Leibo, Denis Teplyashin, Tom Ward, Marcus Wainwright, Heinrich Küttler, Andrew Lefrancq, Simon Green, Víctor Valdés, Amir Sadik, et al. DeepMind lab. , 2016. Preprint arXiv:1612.03801 Marc G Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents. , 47:253 tot 279, 2013. Journal van kunsmatige intelligensie navorsing Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. , 2021. Preprint arXiv:2108.07258 Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, en ander. , 2021. Preprint arXiv:2112.04426 Nick Bostrom. . Dunod, 2017. Superintelligence Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang en Wojciech Zaremba. , 2016. Preprint arXiv:1606.01540 TB Brown, B Mann, N Ryder, M Subbiah, J Kaplan, P Dhariwal, A Neelakantan, P Shyam, G Sastry, A Askell, et al. Language models are few-shot learners. In , pp. 1877–1901, 2020. Advances in Neural Information Processing Systems Serkan Cabi, Sergio Gómez Colmenarejo, Alexander Novikov, Ksenia Konyushkova, Scott Reed, Rae Jeong, Konrad Zolna, Yusuf Aytar, David Budden, Mel Vecerik, et al. Scaling data-driven robotics with reward sketching and batch reinforcement learning. , 2019. Preprint arXiv:1909.12200 Annie S Chen, Suraj Nair, and Chelsea Finn. Learning generalizable robotic reward functions from “in-the-wild" human videos. , 2021a. Preprint arXiv:2103.16817 Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Ar-avind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. , 34, 2021b. Advances in Neural Information Processing Systems Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. , 2021c. Preprint arXiv:2107.03374 Tao Chen, Adithyavairavan Murali, and Abhinav Gupta. Hardware conditioned policies for multi-robot transfer learning. , 31, 2018. Advances in Neural Information Processing Systems Ting Chen, Saurabh Saxena, Lala Li, David J Fleet, and Geoffrey Hinton. Pix2seq: A language modeling framework for object detection. In Die jaar 2022. ICLR Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server. , 2015. Preprint arXiv:1504.00325 Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen, and Yoshua Bengio. BabyAI: A platform to study the sample efficiency of grounded language learning. , 2018. Preprint arXiv:1810.08272 Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, en ander. , 2022. Preprint arXiv:2204.02311 Karl Cobbe, Chris Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. In , pp. 2048–2056, 2020. International Conference on Machine Learning Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G Carbonell, Quoc Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. In , pp. 2978–2988, 2019. Annual Meeting of the Association for Computational Linguistics Coline Devin, Abhishek Gupta, Trevor Darrell, Pieter Abbeel, en Sergey Levine. Leer modulêre neurale netwerk beleid vir multi-task en multi-robot oordrag. In , pp. 2169–2176, 2017. IEEE Internasionale Konferensie oor Robotiek en Automatisering Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirec-tional transformers for language understanding. , 2018. Voorgedruk arXiv:1810.04805 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Un-terthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. , 2020. Preprint arXiv:2010.11929 Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Vlad Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. Impala: Scalable distributed deep-RL with importance weighted actor-learner architectures. In , pp. 1407–1416, 2018. International Conference on Machine Learning Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4RL: Datasets for deep data-driven reinforcement learning. , 2020. Preprint arXiv:2004.07219 Hiroki Furuta, Yutaka Matsuo, and Shixiang Shane Gu. Generalized decision transformer for offline hindsight information matching. , 2021. Preprint arXiv:2111.10364 Caglar Gulcehre, Ziyu Wang, Alexander Novikov, Thomas Paine, Sergio Gómez, Konrad Zolna, Rishabh Agarwal, Josh S Merel, Daniel J Mankowitz, Cosmin Paduraru, et al. RL unplugged: A suite of benchmarks for offline reinforcement learning. , 33:7248–7259, 2020. Advances in Neural Information Processing Systems Jeff Hawkins and Sandra Blakeslee. . Macmillan, 2004. On intelligence Kaiming He, Xiangyu Zhang, Shaoqing Ren, en Jian Sun. Diepe residuele leer vir beeldherkenning. In , pp. 770–778, 2016a. IEEE Computer Vision and Pattern Recognition Kaiming He, Xiangyu Zhang, Shaoqing Ren, en Jian Sun. Identiteitskaartings in diepe residuele netwerke. , pp. 630–645, 2016b. European Conference on Computer Vision Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In , pp. 9729–9738, 2020. IEEE Computer Vision and Pattern Recognition Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (GELUs). , 2016. Matteo Hessel, Hubert Soyer, Lasse Espeholt, Wojciech Czarnecki, Simon Schmitt, and Hado van Hasselt. Preprint arXiv:1606.08415 Multi-task diep versterking leer met popart. in , 2019. AAAI Matteo Hessel, Ivo Danihelka, Fabio Viola, Arthur Guez, Simon Schmitt, Laurent Sifre, Theophane Weber, David Silver, and Hado van Hasselt. Muesli: Combining improvements in policy optimization. , 2021. Voordruk arXiv:2104.06159 Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. , 9(8):1735–1780, 1997. Neural computation Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. , 2022. Voordruk arXiv:2203.15556 Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Weinberger. Deep networks with stochastic depth. , 2016. Preprint arXiv:1603.09382 Wenlong Huang, Igor Mordatch, and Deepak Pathak. One policy to control them all: Shared modular policies for agent-agnostic control. In , pp. 4455–4464, 2020. International Conference on Machine Learning Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. , 2022. Preprint arXiv:2201.07207 David Yu-Tung Hui, Maxime Chevalier-Boisvert, Dzmitry Bahdanau, and Yoshua Bengio. Babyai 1.1. , 2020. Voorgedruk arXiv:2007.12770 Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver IO: A general architecture for structured inputs & outputs. , 2021. Preprint arXiv:2107.14795 Michael Janner, Qiyang Li, and Sergey Levine. Offline reinforcement learning as one big sequence modeling problem. , 34, 2021. Vooruitgang in neurale inligting verwerkingsstelsels Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In , bladsy 4904–4916, 2021. International Conference on Machine Learning Melvin Johnson, Orhan Firat, and Roee Aharoni. Massively multilingual neural machine translation. In , pp. 3874–3884, 2019. Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, et al. Highly accurate protein structure prediction with AlphaFold. , 596(7873):583–589, 2021. Nature Lukasz Kaiser, Aidan N Gomez, Noam Shazeer, Ashish Vaswani, Niki Parmar, Llion Jones, and Jakob Uszkoreit. One model to learn them all. , 2017. Preprint arXiv:1706.05137 Anssi Kanervisto, Joonas Pussinen, en Ville Hautamäki. Benchmarking van eind-tot-end gedragskloonering op videospeletjies. , bladsy 558 tot 565, 2020. IEEE conference on games (CoG) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. , 2020. Voorgedruk arXiv:2001.08361 Steven Kapturowski, Georg Ostrovski, John Quan, Remi Munos, and Will Dabney. Recurrent experience replay in distributed reinforcement learning. In , 2018. Internasionale konferensie oor leerverteenwoordigings Zachary Kenton, Tom Everitt, Laura Weidinger, Iason Gabriel, Vladimir Mikulik en Geoffrey Irving. Die jaar 2021. Preprint arXiv:2103.14659 Nitish Shirish Keskar, Bryan McCann, Lav R Varshney, Caiming Xiong, and Richard Socher. CTRL: A conditional transformer language model for controllable generation. , 2019. Voorgedruk arXiv:1909.05858 Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. , 2014. Preprint arXiv:1412.6980 Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In , Jaarvergadering van die Vereniging vir Computational Linguistics Hoofstuk 66-71 van 2018. Vitaly Kurin, Maximilian Igl, Tim Rocktäschel, Wendelin Boehmer, en Shimon Whiteson. My liggaam is 'n kooi: die rol van morfologie in graf-gebaseerde onverenigbare beheer. Die jaar 2020. Preprint arXiv:2010.01856 Alex X Lee, Coline Manon Devin, Yuxiang Zhou, Thomas Lampe, Konstantinos Bousmalis, Jost Tobias Springenberg, Arunkumar Byravan, Abbas Abdolmaleki, Nimrod Gileadi, David Khosid, et al. Beyond pick-and-place: Die aanpak van robotiese stapels van verskillende vorme. Die jaar 2021. Conference on Robot Learning Alex X Lee, Coline Manon Devin, Jost Tobias Springenberg, Yuxiang Zhou, Thomas Lampe, Abbas Abdol-maleki, and Konstantinos Bousmalis. How to spend your robot time: Bridging kickstarting and offline reinforcement learning for vision-based robotic manipulation. , 2022. Preprint arXiv:2205.03353 Shuang Li, Xavier Puig, Chris Paxton, Yilun Du, Clinton Wang, Linxi Fan, Tao Chen, De-An Huang, Ekin Akyürek, Anima Anandkumar, Jacob Andreas, Igor Mordatch, Antonio Torralba, and Yuke Zhu. Pre-trained language models for interactive decision-making. , 2022a. Voordruk arXiv:2202.01771 Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with AlphaCode. , 2022b. Preprint arXiv:2203.07814 Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. , 2017. Voorgeskryf arXiv:1711.05101 Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-VQA: A visual question answering benchmark requiring external knowledge. In ,pp. 3195–3204, 2019 IEEE rekenaar visie en patroon erkenning Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, et al. Teaching language models to support answers with verified quotes. , 2022. Preprint arXiv:2203.11147 Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. Model cards for model reporting. In , bladsy 220–229, 2019. Proceedings of the conference on fairness, accountability, and transparency Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, ens. , 518(7540):529–533, 2015. natuur Vernon Mountcastle. An organizing principle for cerebral function: the unit module and the distributed system. , 1978. The mindful brain Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, en ander. , 2021. Preprint arXiv:2112.09332 Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. WaveNet: A generative model for raw audio. , 2016. Voordruk arXiv:1609.03499 Pedro A Ortega, Markus Kunesch, Grégoire Delétang, Tim Genewein, Jordi Grau-Moya, Joel Veness, Jonas Buchli, Jonas Degrave, Bilal Piot, Julien Perolat, et al. Shaking the foundations: delusions in sequence models for interaction and control. Die jaar 2021. Preprint arXiv:2110.10819 Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. , 2022. Preprint arXiv:2203.02155 Simone Parisi, Aravind Rajeswaran, Senthil Purushwalkam, and Abhinav Gupta. The unsurprising effec-tiveness of pre-trained vision models for control. , 2022. Preprint arXiv:2203.03580 Vineel Pratap, Anuroop Sriram, Paden Tomasello, Awni Hannun, Vitaliy Liptchinsky, Gabriel Synnaeve en Ronan Collobert. Massief meertalige ASR: 50 tale, 1 model, 1 miljard parameters. , 2020. Preprint arXiv:2007.03001 Sébastien Racanière, Théophane Weber, David Reichert, Lars Buesing, Arthur Guez, Danilo Jimenez Rezende, Adrià Puigdomènech Badia, Oriol Vinyals, Nicolas Heess, Yujia Li, et al. Verbeeldingstoename agente vir diepe versterking leer. , 30, 2017. Advances in Neural Information Processing Systems Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher. , 2021. Voordruk arXiv:2112.11446 Scott Reed en Nando De Freitas. Neurale programmeerders-interpreteurs. , 2016. International Conference on Learning Representations Machel Reid, Yutaro Yamada, and Shixiang Shane Gu. Can Wikipedia help offline reinforcement learning? , 2022. Preprint arXiv:2201.12122 van Stuart Russell. . Penguin, 2019. Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Human compatible: Artificial intelligence and the problem of control Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive neural networks. , 2016. Preprint arXiv:1606.04671 Victor Sanh, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Teven Le Scao, Stella Biderman, Leo Gao, Thomas Wolf, and Alexander M Rush. Multitask prompted training enables zero-shot task generalization. In , 2022. International Conference on Learning Representations Jürgen Schmidhuber. One big net for everything. , 2018. Voorgedruk arXiv:1802.08864 Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model. , 588(7839):604–609, 2020. Nature Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hyper-nymed, image alt-text dataset for automatic image captioning. In , pp. 2556–2565, 2018. Annual Meeting of the Association for Computational Linguistics Noam Shazeer. Glu variants improve transformer. , 2020. Preprint arXiv::2002.05202 H Francis Song, Abbas Abdolmaleki, Jost Tobias Springenberg, Aidan Clark, Hubert Soyer, Jack W Rae, Seb Noury, Arun Ahuja, Siqi Liu, Dhruva Tirumala, et al. V-mpo: On-policy maximum a posteriori policy optimization for discrete and continuous control. In , 2020. ICLR Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. , 15(56): 1929–1958, 2014. Journal of Machine Learning Research Richard Sutton, Die bittere les Op 13:12 van 2019. Incomplete Ideas (blog) Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. DeepMind control suite. Die jaar 2018. Preprint arXiv:1801.00690 Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. LaMDA: Language models for dialog applications. , 2022. Voordruk arXiv:2201.08239 Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In , pp. 5026–5033, 2012. Internasionale konferensie oor intelligente robotte en stelsels Maria Tsimpoukelli, Jacob L Menick, Serkan Cabi, SM Eslami, Oriol Vinyals, and Felix Hill. Multimodal few-shot learning with frozen language models. , pp. 200–212, 2021. Advances in Neural Information Processing Systems Saran Tunyasuvunakool, Alistair Muldal, Yotam Doron, Siqi Liu, Steven Bohez, Josh Merel, Tom Erez, Timothy Lillicrap, Nicolas Heess en Yuval Tassa. dm_control: sagteware en take vir voortdurende beheer. , 6:100022, 2020. Software Impacts Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. , 30, 2017. Advances in Neural Information Processing Systems Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, en Yuan Cao. Simvlm: Eenvoudige visuele taalmodel vooropleiding met swak toesig. Die jaar 2021. Preprint arXiv:2108.10904 Ziyu Wang, Alexander Novikov, Konrad Zolna, Josh S Merel, Jost Tobias Springenberg, Scott E Reed, Bobak Shahriari, Noah Siegel, Caglar Gulcehre, Nicolas Heess, et al. Kritiek geregulariseer regressie. , 33:7768 tot en met 7778, 2020. Vooruitgang in neurale inligting verwerkingsstelsels Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, en Quoc V Le. Finetuned taalmodelle is nul-shoot leerlinge. , 2021. Preprint arXiv:2109.01652 Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, et al. Ethical and social risks of harm from language models. , 2021. Preprint arXiv:2112.04359 Yuxin Wu and Kaiming He. Group normalization. In , pp. 3–19, 2018. European Conference on Computer Vision Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, en Sergey Levine. Meta-Wereld: 'n benchmark en evaluering vir multi-task en meta-versterking leer. In , pp. 1094–1100, 2020. Conference on Robot Learning Qinqing Zheng, Amy Zhang, and Aditya Grover. Online decision transformer. , 2022. Preprint arXiv:2202.05607 Konrad Zolna, Alexander Novikov, Ksenia Konyushkova, Caglar Gulcehre, Ziyu Wang, Yusuf Aytar, Misha Denil, Nando de Freitas, and Scott Reed. Offline learning from demonstrations and unlabeled experience. Die jaar 2020. Voorgedruk arXiv:2011.13885 Konrad Zolna, Scott Reed, Alexander Novikov, Sergio Gómez Colmenarejo, David Budden, Serkan Cabi, Misha Denil, Nando de Freitas, and Ziyu Wang. Task-relevant adversarial imitation learning. In , bladsye 247–263, 2021. Conference on Robot Learning Supplementary Material A Model card We present a model card for Gato in Table 4. Table 4: We follow the framework proposed in Gato Model Card. (Mitchell et al., 2019). B Agent Data Tokenization Details In this section we provide additional details on our tokenization schemes. Our agent data is sequenced as follows: • Dit word aan die agent in volgorde van tyd (timesteps) aangebied. Episodes • die in turn are presented in the following order: Timesteps ([ 1: 1 : die 1: ]) are ordered lexicographically by key, each item is sequenced as follows: – Observations y k, x m, z n ∗ Text tokens ( 1: ) are in the same order as the raw input text. y k ∗ Image patch tokens ( 1: ) are in raster order. x m ∗ Tensors ( 1: ) (such as discrete and continuous observations) are in row-major order. z n - die (' '); 'n aangewese separator token word na waarnemings verskaf. Separator | – ( 1: ) are tokenized as discrete or continuous values and in row-major order. Actions a A A full sequence of tokens is thus given as the concatenation of data from T timesteps: where L = T(k + m + n + 1 + A) is the total number of tokens. Elke vloeiend puntelement van tensors in die waarnemingsekvensie is mu-law gekompandeer soos in WaveNet (Oord et al., 2016): with parameters µ = 100 and M = 256. (If the floating-point tensor is in the action set, we do not need to compand the elements in the sequence because actions are only defined in the range \[ 1, 1\] for all our environments.) All the elements are subsequently clipped so that they fall in the set \[ 1, 1\]. Finally, they are discretized using bins of uniform width on the domain \[ 1,1\]. We use 1024 bins and shift the resulting integers so they are not overlapping with the ones used for text tokens. The tokenized result is therefore a sequence of integers within the range of \[32000, 33024). See Figure and Figure for visualizations of tokenizing and sequencing values (both discrete and con-tinuous) and images. See Section for details about local position encodings referenced in the figures. 14 15 C C Model Architecture C.1 Transformer Hyperparameters The transformer hyperparameters of Gato are presented in Table We also list the hyperparameters of smaller architecture variants used in Section 5. 5. C.2 Embedding Function Die ResNet blok gebruik die v2 argitektuur contains GroupNorm met 32 groepe in plaas van LayerNorm and GELU activation functions instead of RELU. The block is diagrammed in Figure Hy en al. 2016b), (Wu & He, 2018) (Ons en al. 2016), (Hendrycks & Gimpel, Die 2016 16. C.3 Position Encodings After tokens are mapped into token embeddings, two position encodings are added to the token embeddings (when applicable) to provide temporal and spatial information to the model. These are described below. Patch posisie kodeer These position encodings convey information about a patch’s global position within the image from which the patch was extracted. First, the relative row and column intervals of the patch are calculated by normalizing the patch’s pixel intervals by the image resolution. The row and column normalized intervals are then quantized into a vocabulary size (we use 128) and are used to index a row and column table of learnable position encodings. The method in which the quantized row and column intervals are converted into indices depends on whether we are training or evaluating the model: during training a random index is uniformly sampled from the quantized interval, while during evaluation we deterministically take the (rounded) mean of the interval. Once row and column position encoding are retrieved from the embedding table, they are added onto the token embedding produced by the resnet embedding function, as described previously. Om hierdie proses meer spesifiek te demonstreer, gee ons 'n voorbeeld in Figuur [17.](#_bookmark144) Ons sal die proses volg met die patch in rooi verlig op die linkerkant van die subfiguur. Die beeld is van resolusie 80 64 en elke patch is 16 16, wat beteken dat daar 5 4 = 20 patches in totaal is. Die verligte patch begin by pixel-reeks-interval \[16*,* 32\] en pixel-kolom-interval \[32*,* 64\]. Normaliser, is die reeks-interval dus \[0*25*,* 0*.*5\] en die kolom-interval is \[0**4*,* 0*.*6\]. Ons kwanties dan afsonderlik die intervalle in 128 uniforme spasies, met die resul Local Observation Position Encodings The local observation position encoding adds positional information about where observation tokens are positioned within the local time-step they were an element of. First, we reiterate that, during tokenization, for each time-step all elements of the observation set are tokenized into sequences and concatenated into an observation sequence. Each token in this observation sequence is given an index which corresponds to the sequence order, i.e. the first token is 0 and the last is the length of the observation sequence minus one. After embedding, for any tokens that were a part of an observation set, the corresponding observation token index is used to index an embedding table of learnable position encodings, with one embedding for every possible observation token index (in practice we simply set the table size to a large value like 512). / Die posisie kodering word dan by die waarneming token embedding bygevoeg om die finale token embedding te produseer. Let daarop dat alle aksie tokens dieselfde posisie kodering gegee word, ongeag hul posisie in die tyd-stap-reeks. 18. D Pretraining Setup For all models we use the AdamW optimizer with a linear warm-up and cosine schedule decay. The linear warmup lasts for 15*,* 000 steps, starting from a learning rate of 1e-7 and ending at a different maximum learning rate depending on the model (see Table Hierdie leerperk word dan met 'n faktor 10x oor 1 000 000 stappe verval. 1 = 0 2 = 0.*95 and = 1e-8. We use a batch size of 512 and a sequence length of 1024 tokens for all models. Optimizer: Loshchilov en Hutter, 2017 die Die 6). β 9 Die V ϵ Ons oefen met 'n AdamW gewig verval parameter van 0.1. tydens vooropleiding, waar elke van die transformer sub-lae (dws elke Multi-Head Attention en Dense Feedforward laag) met 'n waarskynlikheid van 0,1 verbyg word. Regularization: (Hierdie en al. Die 2016 E Fine-tuning opstel Vir al die modelle wat ons gebruik die Adam optimizer with a constant learning rate of 1e-5. The Adam optimizer has parameters 1 = 0 2 = 0.*95 and = 1e-8. Ons gebruik 'n batch grootte van 64 en 'n volgorde lengte van 1024 tokens vir alle modelle. Optimizer: (Kingma en Ba, van 2014) β 9 Die V ϵ Ons gebruik drops Met 'n verhouding van 0,1 Regularization: (Ons en die ander, 2014) We evaluate agent every 100 learning steps. Each evaluation reports the average of 10 runs of a given checkpoint. The moving average of 5 such scores is computed (to gather 50 runs together). The final fine-tuning performance is defined as the maximum of these smoothed scores. Evaluation: In plaas daarvan om al die data te gebruik vir 'n fine-tuning taak, het ons al behalwe 2000 beste episodes (wat lei tot die hoogste opbrengs) weggegooi. Die fine-tuning datasets is op die volgende manier geskep. Ons het willekeurig 1000 episodes geneem (van 2000 vooraf gekies episodes), dan 'n subset van 100 episodes van die geselekteerde episodes, dan 10, 5, 3, en uiteindelik 'n enkele episode. Ons het hierdie prosedure 3 keer herhaal om 3 reeks van cascading subset vir elke taak te verkry. Elke subset word gebruik om een fine-tuning eksperiment te voer, en elkeen word op ons plot in Afdeling gerapporteer. As 'n aparte punt Datasets: 5.2 Ons het geen van die take verander nie en hulle kanoniese weergawes gebruik nie. Aangesien 3 van die 4 take oopbron is, benodig hulle geen verdere verduideliking nie. Vir die vierde taak, DMLab order_of_apples_forage_simple, is die doel om appels in die regte volgorde te versamel, groen die eerste gevolg deur die goue een. Task settings: F Data Collection Details F1 van die Atari Ons versamel twee afsonderlike stel Atari omgewings. die eerste (wat ons ALE Atari noem) bestaan uit 51 kanoniese speletjies van die Arcade Learning Environment Die tweede (wat ons noem as ALE Atari Extended) is 'n stel alternatiewe speletjies with their game mode and difficulty randomly set at the beginning of each episode. (Ons en die ander, Die jaar 2013). 3 Vir elke omgewing in hierdie stel versamel ons data deur 'n Muesli te oefen agent vir 200M totale omgewingsstappe. Ons registreer ongeveer 20,000 ewekansige episodes wat deur die agent tydens opleiding gegenereer word. (Ons en al. 2021) F2 Sokoban Sokoban is a planning problem in wat die agent het om bokse te dryf na die teiken plekke. Sommige van die bewegings is onomkeerbaar en gevolglik foute kan maak die legkaart onoplosbaar. Vooraf beplanning is dus nodig om te slaag op hierdie legkaart. Ons gebruik 'n Muesli agent vir die versameling van opleiding data. (Racanière et al., 2017), (Ons en al. 2021) F.3 BabyAI BabyAI is a gridworld environment whose levels consist of instruction-following tasks that are described by a synthetic language. We generate data for these levels with the built-in BabyAI bot. The bot has access to extra information which is used to execute optimal solutions, see Section C in the appendix of for more details about the bot. We collect 100,000 episodes for each level. (Chevalier-Boisvert et al., Die jaar 2018 F.4 DeepMind beheer suite Die DeepMind Control Suite (T) ., is 'n stel fisika-gebaseerde simulasie omgewings. Vir elke taak in die beheer suite ons versamel twee disjoint sets van data, een gebruik slegs state eienskappe en 'n ander gebruik slegs piksels. agent om data te versamel van take met state funksies, en 'n MPO based agent to collect data using pixels. verwysing en al 2020; Tassa en al. Die jaar 2018 (Barth-Maron et al., Die jaar 2018 (Abdolmaleki et al., Die jaar 2018 We also collect data for randomized versions of the control suite tasks with a D4PG agent. These versions randomize the actuator gear, joint range, stiffness, and damping, and geom size and density. There are two difficulty settings for the randomized versions. The small setting scales values by a random number sampled from the union of intervals [0*. ,* 0*. [Die eerste · 1 * . Die 0’s [Die eerste · · · · · · · · · · · 9 95] ∪ 05 1]. Die groot instelling skaal waardes deur 'n ewekansige getal gesamel uit die unie van intervalle [0 6 8 Die 2 F5 DeepMind laboratorium DeepMind Lab die is 'n eerste-persoon 3D-omgewing wat ontwerp is om agente 3D-visie te leer uit ruwe pixel-inputs met 'n egosentrieke perspektief, navigasie en beplanning. (Beattie et al. 2016) Ons het 'n IMPALA opgelei Agente gesamentlik op 'n stel van 18 ouer DM Lab vlakke wat kaarte prosedureel vir elke nuwe episode genereer. data is versamel deur die uitvoering van die agent op hierdie 18 vlakke, sowel as 'n bykomende stel van 237 vlakke handgemaak om 'n diverse stel vaardighede te toets. (Espeholt et al., 2018) Die 18 ouer vlakke word gekenmerk deur 'n hoë diversiteit van gegenereerde kaarte. Die verskil tussen die vlakke is gewortel in hyper-parameters wat in 'n generasieproses gebruik word. Hierdie hyper-parameters beheer hoë-vlak eienskappe soos soorte strukture wat gebore word, moeilikheid van taal instruksies, of die teenwoordigheid van spesifieke gereedskap. Die ouer vlakke is ontwikkel om die prestasie van RL agente wat aanlyn op hulle opgelei word, te verbeter. In teenstelling met die ouer vlakke, elke van die bykomende handgemaakte 237 vlakke gebruik byna dieselfde kaart, en die belangrikste verskille tussen voorbeelde van dieselfde vlak kaart is estetika soos die kleure van die mure of verligting toestande. procedurally generated and were designed to test a diverse set of skills such as walking up stairs or using specific tools. They are similar to levels presented in Figure 3, Figure 7 and Figure 8 in aforementioned paper by nie Beattie et al. (2016) van die Aanvullende inligting oor die 18 ouer vlakke (en hul verhouding met die ander vlakke) word in besonderhede in die NeurIPS-workshopgesprek aangebied. Geskryf deur Daniel Tanis . 'N Methodologie vir RL omgewingsnavorsing 4 In total, we collected data for 255 levels from the DeepMind Lab (18 parent levels and 237 handcrafted levels), 254 of which were used while training Gato. The remaining level was used for out of distribution evaluation. F6 Procgen benchmark Probeer is 'n suite van 16 procedurele gegenereer Atari-agtige omgewings, wat voorgestel is om benchmark monster doeltreffendheid en generalisering in versterking leer. Ons gebruik die harde moeilikheid instelling vir alle omgewings behalwe vir labyrint en roof, wat ons eenvoudig ingestel het. (Cobbe et al., Die jaar 2020 (Kapturowski en al., Die jaar 2018 F.7 Modulêre RL Modular RL is 'n versameling van MuJoCo (T based continuous control environments, composed of three sets of variants of the OpenAI Gym Walker2d-v2, Humanoid-v2, en Hopper-v2. Elke variant is 'n morfologiese verandering van die oorspronklike liggaam: die stel morfologieë word gegenereer deur al die moontlike subset van ledemate op te stel, en slegs die stel te hou wat a) die torso bevat, en b) nog steeds 'n verbindde graf vorm. Dit lei tot 'n stel variante met verskillende in- en uitvoergrootte, sowel as verskillende dinamika as die oorspronklike morfologieë. Ons het data versamel deur 'n enkele morfologie-spesifieke D4PG agent op elke variant te opleiding vir 'n totaal van 140M akteur stappe, dit is gedoen vir 30 ewekansige sade per variant. (Hierdie en al. Die jaar 2020 Oorweg en al. van 2012) (Boekman en al. Die 2016 F.8 DeepMind Manipulasie Speelplek Die DeepMind Manipulasie Speelplek is a suite of MuJoCo based simulated robot tasks. We collect data for 4 of the Jaco tasks (box, stack banana, insertion, and slide) using a Critic-Regularized Regression (CRR) agent Die versamel data sluit in die MuJoCo fisiese toestand, wat ons gebruik vir die opleiding en evaluering van Gato. (Ons en al. 2021) (Wang et al., Die jaar 2020 F.9 Meta-wêreld Meta-World (Y is a suite of environments vir benchmarking meta-versterking leer en multi-task leer. Ons versamel data van al die opleiding en toets take in die MT50 modus deur die opleiding van 'n MPO agent met onbeperkte omgewingsseem en met toegang tot die toestand van die MuJoCo fisika-motor. u et al., Die jaar 2020 5 (Ons en die ander, Die jaar 2018 G Real Robotics evaluering besonderhede In the real world, control is asynchronous; physics does not wait for computations to finish. Thus, inference latency is a concern for evaluating a large model for real world tasks. In robotics, a fast control rate is thought to be critical for reacting to dynamic phenomena. The robot setup for RGB stacking has a 20Hz control rate (0.05 second timestep) by design. In order to reach an acceptable margin of latency, we modified inference at evaluation time by shortening the context length to 1. We also implemented a parallel sampling scheme where all the action tokens are zeroed out in the input sequences during training so we can sample all tokens corresponding to a robot action in a single model inference step instead of autoregressively as it’s done in other domains. We found that the 1.18B parameter model was able to run on the hardware accelerators in our robots (NVidia GeForce RTX 3090s), but still overran the 20Hz control rate by a small amount (~0.01 seconds). Ons gebruik die sparse beloning funksie wat beskryf word in for data filtering. We only select trajectories with taak sukses; dit is, 'n geringe beloning van 1 op die finale tydstap. Lee et al. (2021) final H Skill Meestery Arkitektuur The numbers reported for the Skill Mastery benchmark were collected by executing a model zero-shot that used an earlier version of the Gato architecture. Instead of the ResNet patch embedding, a similar architecture using a local transformer was used to embed image patch tokens. The local position embeddings and patch position embeddings were not used. These changes were implemented and found to improve Gato’s performance after the pretraining data was changed (as we decided to focus on Skill Generalization instead of Skill Mastery challenge), which is why they are presented as the final architecture of our full model. Aanvullende robotiese ablasie Ons het 'n reeks ablasie in simulasie uitgevoer om die effek van uiteenlopende vooropleidingsdata in die robotika-domein beter te verstaan (sien Figuur Ons het dieselfde baseline soos in Afdeling ingesluit selecting the 364M parameter size variant, as well as an additional baseline trained with control suite data only. The DM Control-only agent is superior to the base Gato at zero-shot transfer and with a lot of fine-tuning data, suggesting that Gato may not be using the representations learned from the text-based datasets when adapting to robotics tasks. The same domain only agent performs the best overall, matching the CRR baseline at 1 fine-tuning episode and outperforming it with more data, suggesting that Gato at current scale can trade its generalization capacity for data-efficient and effective few-shot adaptation. 19). 5.2 Die J. Aandacht vir visualisering To render the transformer attention weights, we retrieved the cross-attention logits, a tensor with dimension ( • Waar is die aantal koppe en is die aantal tokens in 'n opeenvolging. die ( Die invoer van hierdie matrix kan geïnterpreteer word as die bedrag wat die hoof attends to token van die token As gevolg van Gato se beeld tokeniseringsstelsel, is daar verskeie tokens per timestep. Daarom, om aandag te gee aan 'n spesifieke timestep, het ons die sub-matrix geneem wat ooreenstem met daardie timestep. Ons het dan 'n softmax op die rye van hierdie matrix toegepas om die relevante waardes te normaliseer. Omdat ons net belangstel in aandag aan die vorige tokens, het ons die diagonaal uitgesluit deur dit tot negatiewe oneindigheid te stel voor softmax. H, T, T H T H, I en J h j i To measure the importance of each patch, we averaged the attention weights over the corresponding column. Because Gato uses a causal transformer, the attention matrix is lower triangular, so the mean was only considered over the sub-column below the diagonal of the matrix. This corresponds to the average attention paid to particular patch over a whole timestep. Met behulp van hierdie metode, het ons gevind dat die aandag kaarte by die eerste laag van die transformator is die mees interpreteerbaar, saamstem met die bevindings van Bepaalde koppe volg duidelik taak-spesifieke entiteite en streke van die prentjie. toon die aandag kaarte vir handmatig gekies koppe in die eerste laag vir verskeie take. Abnar en Zuidema Hy het (2020) 20 K Gedetailleerde resultate vir spesialis Meta-Wereld agent Die spesialis Meta-Wereld agent beskryf in Afdeling bereik 96,6% gemiddelde suksesperk oor al 50 Meta-Wereld take. Ons het die agent 500 keer vir elke taak beoordeel. 5.5 7. L Per-domein resultate vir Kat Ons beskryf die prestasie van Gato vir gesimuleerde beheer take in Afdeling In die tafel Ons het die agent 50 keer vir elke taak geëvalueer. 4.1 Die 8, Hierdie artikel is beskikbaar onder CC by 4.0 Deed (Attribution 4.0 International) lisensie. Hierdie artikel is beskikbaar onder CC by 4.0 Deed (Attribution 4.0 International) lisensie.