
1,959 reads
Kubernetes 101- Concepts, Potential, and lots of Container Orchestrations
by byMagalix@Magalix
byMagalix@Magalix
Right-size your Kubernetes, achieve better app performance, and lower your cloud infrastructure cost
October 2nd, 2019





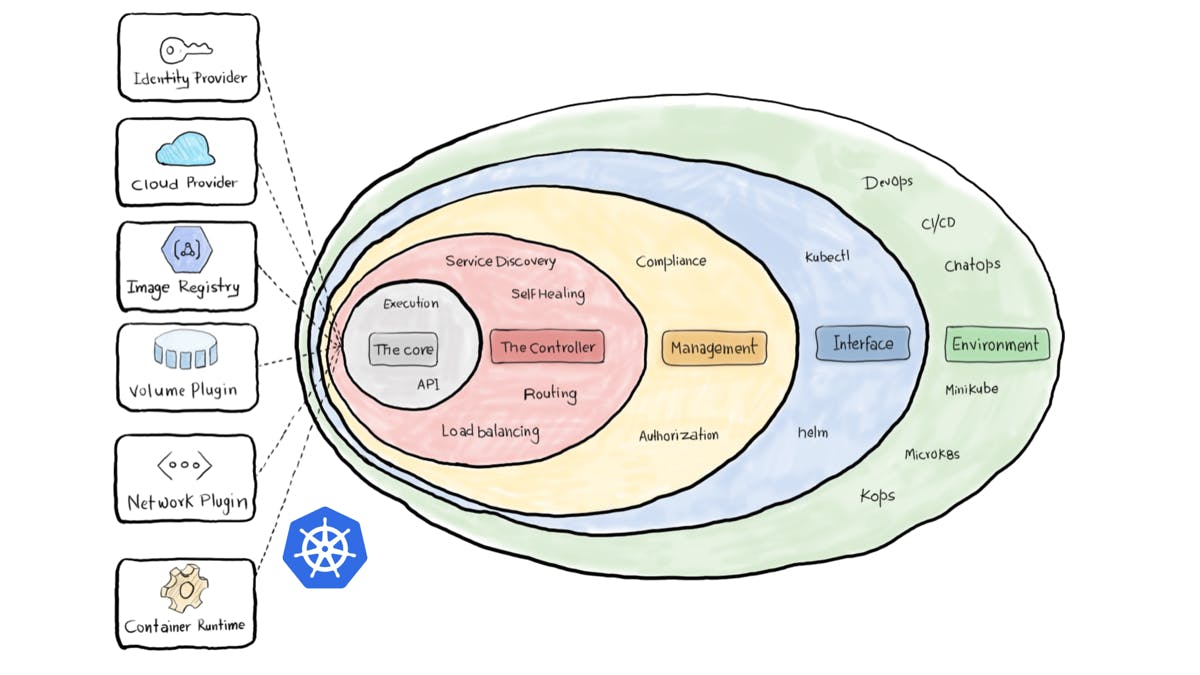
Right-size your Kubernetes, achieve better app performance, and lower your cloud infrastructure cost


Right-size your Kubernetes, achieve better app performance, and lower your cloud infrastructure cost
About Author

Right-size your Kubernetes, achieve better app performance, and lower your cloud infrastructure cost
Comments

TOPICS





Related Stories


5 Building Blocks of AIOps

Feb 14, 2022







5 Building Blocks of AIOps
Feb 14, 2022