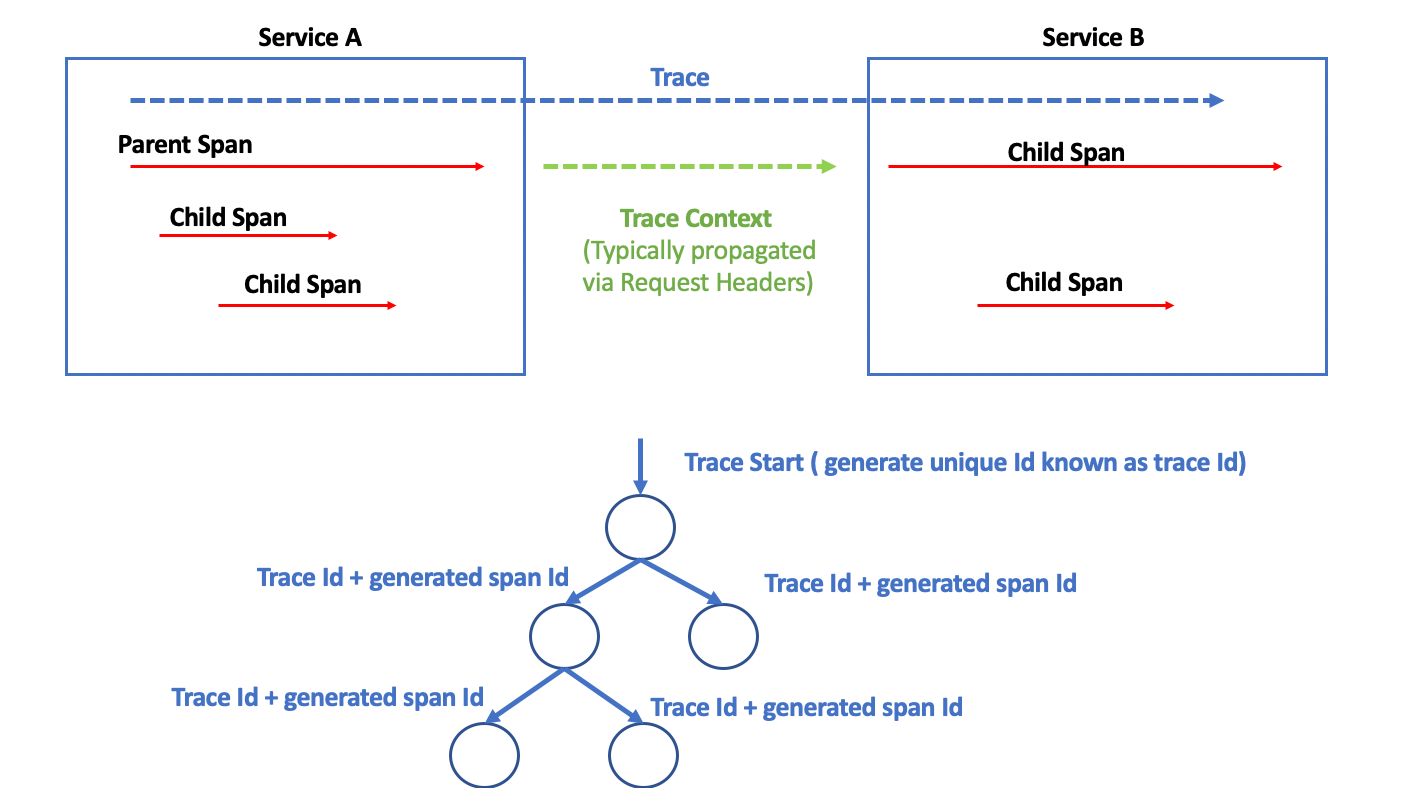
A distributed architecture brings in several challenges when it comes to operability and monitoring. Here, one may be dealing with tens if not hundreds of microservices, each of which may or may not have been built by the same team. With a large-scale system, it is very important to have eyes on key system metrics, application health and enough data to be able to track down issues quickly and mitigate them. Being in a CLOUD environment such as AWS, Google Cloud, Azure further accentuate the problem and makes it difficult to detect, troubleshoot and isolate an issue due to the dynamic nature of the infrastructure (scale up / down, temporal machines, dynamic IPs etc.). : KEY PILLARS OF OBSERVABILITY - Application metrics, Host/System metrics, Network metrics etc. Metrics - Application and supporting infrastructure logs Logs - Track down a flow of a request through the distributed systemIn this article I will be focusing on the Logs (Application generated only) & Traces aspect of the observability. Traces LOGS With the distributed architecture it has become a standard practice to use centralized logging systems to be able to gather logs and visualize them. Logs generated by different microservice will be automatically shipped to a central location for storage and analysis. Some of the popular centralized logging solutions for application logs are : Splunk Datadog Logstash Fluentd Logs provide useful information about events that have occurred within your application. These could be INFO level logs or error logs with detailed stack traces around exceptions. LOG CORRELATION ACROSS MICROSERVICES A centralized logging system in a large distributed application may be ingesting Gigabytes of data per hour, if not more. Given that a request may be travelling through multiple microservices, one way to query all logs related to a request spanning several microservices is to attribute each request with some kind of unique identifier. In most cases this could be a associated with the request or some sort of generated at the first point of ingress into the application. These identifiers will be attached to each and every log message and are propagated downstream from one microservice to another via request headers (in case the identifier is not part of the request being made downstream). Now one can easily use the or to query the logging system to find all logs associated with the request across multiple services !!! userId unique UUID requestId userId Fig 1: Centralized Logging Below are few examples of how to tag your logs with required information in Java using Request Filters. Fig2 : Log4J2 Config & Sample Log Fig 3: Request Filters with UUID or UserId TRACING Tracing is a method which allows one to profile and monitor applications while they are running. Traces provide useful information such as: Pathway of a request through the distributed system Latency of a request at every hop/call (as in from one service to another) Below is a sample trace for a request interacting with two microservices (ad-bidding-service and ad-integrator service). Fig 4: Tracing In the above example the data was captured and visualized via tool. There are several other ways to capture traces which I will highlight in the upcoming section. DataDog COMPONENTS OF A TRACE A trace is composed of a tree like structure with parent trace and child spans. A request trace has scope over several services and is further broken down into smaller chunks by operations/functionality known as spans. For example, a call from one microservice to another encompasses a span. Within a microservice there may be multiple spans( depending on how many layers of classes/function or dependent microservices are called to serve the request). Tracing works by generating a unique id per request at the point of ingress and propagating that to downstream systems as in request headers. This allows the different trace information emitted from several services to be tied together at a central location for analysis and visualization. trace-context LOGS & TRACE CORRELATION Now that we are able to search logs by or some other unique identifier (such as ) and are able to trace the performance/behavior of a single request. Would it not be great if we are able to tie these together and be able to correlate logs and traces for a single request !! userId generated UUID Having this correlation between logs and request allows one to: Correlate performance metrics directly with logs Be able to make ad-hoc request to the system for troubleshooting issues Enables synthetic transactions to be made against the system at different points in time and be able to compare current traces with historic ones and collect system logs related to these requests automatically IMPLEMENTING DISTRIBUTED TRACING VIA LOG-TRACE CORRELATION APPROACH #1: INSTRUMENTING WITH 3RD PARTY TOOLS SUCH AS DATADOG Reference: DataDog APM In this approach we are instrumenting the services in the distributed systems with DataDog APMs (application performance monitors). Datadog does 100% tracing of requests and also is able to collect logs emitted by your applications. Datadog essentially takes care of all your centralized logging and trace information collection. Datadog generates unique traceIds and propagates the same across all the instrumented downstream microservices automatically. The only thing we need to do is attribute the DD traceId with the logs and we are able to achieve log-trace correlation. Fig 6: Application Instrumentation Using DataDog Fig 7: Log-Trace Correlation as seen in DataDog APPROACH #2: ZIPKINS, CLOUD-SLEUTH WITH SPRING BOOT APPLICATION Reference: , Zipkins Cloud Sleuth Advantages: Fully integrated into SPRING boot Simple and easy to use Traces can be visualized using Zipkins UI Supports OpenTracing standards via external libraries Supports log correlation via Log4j2 MDC contexts Disadvantages: Does not have a solution to automatically collect LOGs related to trace. We would have to ship logs to ElastiSearch ourself and search using the cloud-sleuth generated trace ids (as header X-B3-TraceId ) Design: Fig 8: Zipkins, Cloud Sleuth and Spring Boot Application APPROACH #3: AMAZON XRAY Reference: Amazon XRAY Advantages: Supports all AWS resources natively. Good if your distributed services deployed and running in AWS AWS Load balancers auto-generate a REQUEST ID per incoming request. Frees up the APPLICATION to generate one. (Reference: ) https://docs.aws.amazon.com/elasticloadbalancing/latest/application/load-balancer-request-tracing.html Allows tracing all the way from API gateway to load balancer, to service and other dependent AWS resources Allows log correlation with help of logs in CLOUDWATCH logs Disadvantages: Cloudwatch logs can get very expensive with large log volumes APPROACH #4: JAGER Reference: Jager Advantages: Supports opentracing by default Has libraries that work with Spring Supports a Jager Agent which can be installed as a side car to propagate traces and logs Disadvantages: More complicated from infrastructure maintenance perspective and setup CONCLUSION Logs and traces are definitely helpful by themselves. But when tied together via log-trace correlation they become a powerful tool to expedite troubleshooting of issue in PRODUCTION environment and at the same time giving operations and development time insight into the health, performance and behavior of the distributed systems. As described about there are several ways to implement the solution. Pick your poison :-)